 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation with Training Wheels
Feb 24, 2025Knowledge distillation is used, in generative language modeling, to train a smaller student model using the help of a larger teacher model, resulting in improved capabilities for the student model. In this paper, we formulate a more general framework for knowledge distillation where the student learns from the teacher during training, and also learns to ask for the teacher's help at test-time following rules specifying test-time restrictions. Towards this, we first formulate knowledge distillation as an entropy-regularized value optimization problem. Adopting Path Consistency Learning to solve this, leads to a new knowledge distillation algorithm using on-policy and off-policy demonstrations. We extend this using constrained reinforcement learning to a framework that incorporates the use of the teacher model as a test-time reference, within constraints. In this situation, akin to a human learner, the model needs to learn not only the learning material, but also the relative difficulty of different sections to prioritize for seeking teacher help. We examine the efficacy of our method through experiments in translation and summarization tasks, observing trends in accuracy and teacher use, noting that our approach unlocks operating points not available to the popular Speculative Decoding approach.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Multi-Task-oriented Nighttime Haze Imaging Enhancer for Vision-driven Measurement Systems
Feb 11, 2025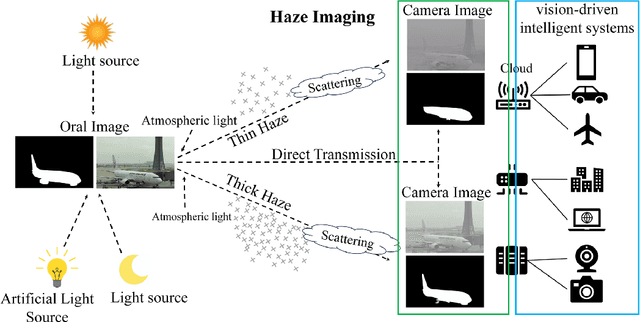
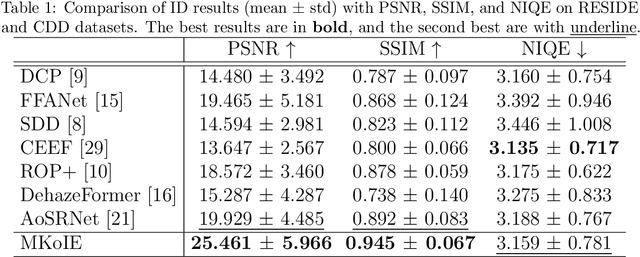
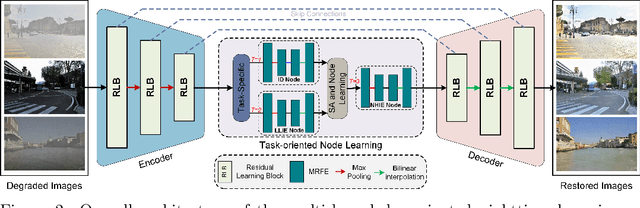
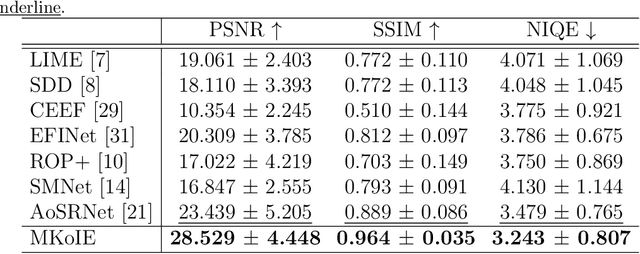
Salient object detection (SOD) plays a critical role in vision-driven measurement systems (VMS), facilitating the detection and segmentation of key visual elements in an image. However, adverse imaging conditions such as haze during the day, low light, and haze at night severely degrade image quality, and complicating the SOD process. To address these challenges, we propose a multi-task-oriented nighttime haze imaging enhancer (MToIE), which integrates three tasks: daytime dehazing, low-light enhancement, and nighttime dehazing. The MToIE incorporates two key innovative components: First, the network employs a task-oriented node learning mechanism to handle three specific degradation types: day-time haze, low light, and night-time haze conditions, with an embedded self-attention module enhancing its performance in nighttime imaging. In addition, multi-receptive field enhancement module that efficiently extracts multi-scale features through three parallel depthwise separable convolution branches with different dilation rates, capturing comprehensive spatial information with minimal computational overhead. To ensure optimal image reconstruction quality and visual characteristics, we suggest a hybrid loss function. Extensive experiments on different types of weather/imaging conditions illustrate that MToIE surpasses existing methods, significantly enhancing the accuracy and reliability of vision systems across diverse imaging scenarios. The code is available at https://github.com/Ai-Chen-Lab/MToIE.
A-Scan2BIM: Assistive Scan to Building Information Modeling
Nov 30, 2023



This paper proposes an assistive system for architects that converts a large-scale point cloud into a standardized digital representation of a building for Building Information Modeling (BIM) applications. The process is known as Scan-to-BIM, which requires many hours of manual work even for a single building floor by a professional architect. Given its challenging nature, the paper focuses on helping architects on the Scan-to-BIM process, instead of replacing them. Concretely, we propose an assistive Scan-to-BIM system that takes the raw sensor data and edit history (including the current BIM model), then auto-regressively predicts a sequence of model editing operations as APIs of a professional BIM software (i.e., Autodesk Revit). The paper also presents the first building-scale Scan2BIM dataset that contains a sequence of model editing operations as the APIs of Autodesk Revit. The dataset contains 89 hours of Scan2BIM modeling processes by professional architects over 16 scenes, spanning over 35,000 m^2. We report our system's reconstruction quality with standard metrics, and we introduce a novel metric that measures how natural the order of reconstructed operations is. A simple modification to the reconstruction module helps improve performance, and our method is far superior to two other baselines in the order metric. We will release data, code, and models at a-scan2bim.github.io.
Variational Model Inversion Attacks
Jan 26, 2022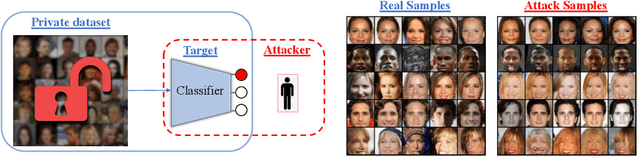
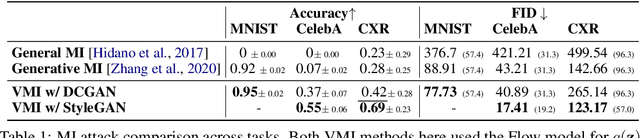

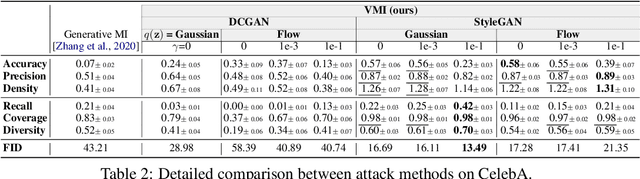
Given the ubiquity of deep neural networks, it is important that these models do not reveal information about sensitive data that they have been trained on. In model inversion attacks, a malicious user attempts to recover the private dataset used to train a supervised neural network. A successful model inversion attack should generate realistic and diverse samples that accurately describe each of the classes in the private dataset. In this work, we provide a probabilistic interpretation of model inversion attacks, and formulate a variational objective that accounts for both diversity and accuracy. In order to optimize this variational objective, we choose a variational family defined in the code space of a deep generative model, trained on a public auxiliary dataset that shares some structural similarity with the target dataset. Empirically, our method substantially improves performance in terms of target attack accuracy, sample realism, and diversity on datasets of faces and chest X-ray images.
Identifying critical nodes in complex networks by graph representation learning
Jan 20, 2022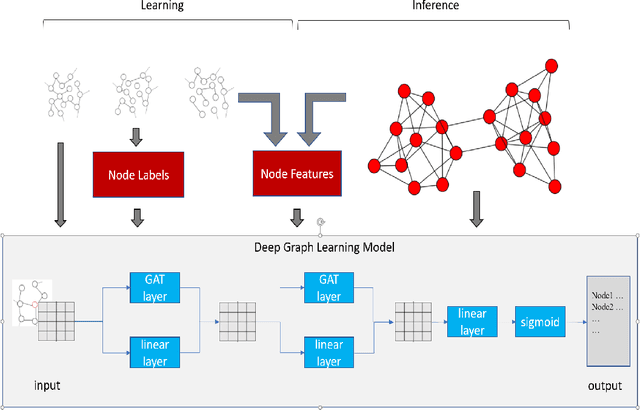
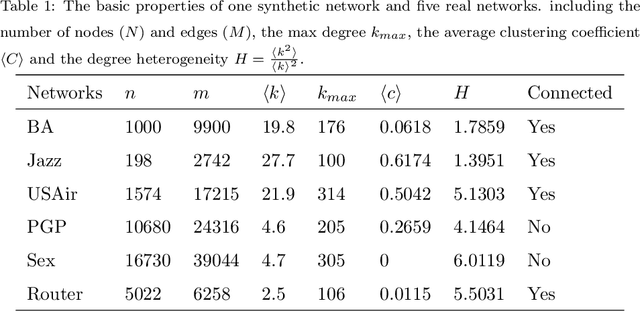
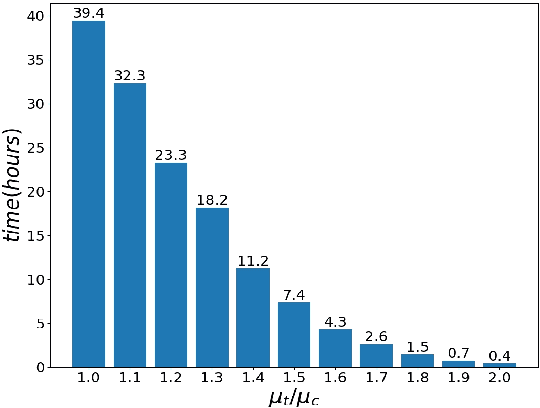
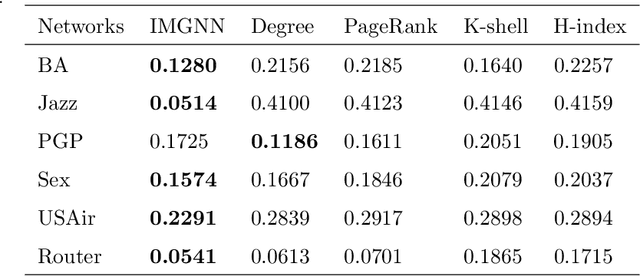
Because of its wide application, critical nodes identification has become an important research topic at the micro level of network science. Influence maximization is one of the main problems in critical nodes mining and is usually handled with heuristics. In this paper, a deep graph learning framework IMGNN is proposed and the corresponding training sample generation scheme is designed. The framework takes centralities of nodes in a network as input and the probability that nodes in the optimal initial spreaders as output. By training on a large number of small synthetic networks, IMGNN is more efficient than human-based heuristics in minimizing the size of initial spreaders under the fixed infection scale. The experimental results on one synthetic and five real networks show that, compared with traditional non-iterative node ranking algorithms, IMGNN has the smallest proportion of initial spreaders under different infection probabilities when the final infection scale is fixed. And the reordered version of IMGNN outperforms all the latest critical nodes mining algorithms.
Pruning with Compensation: Efficient Channel Pruning for Deep Convolutional Neural Networks
Aug 31, 2021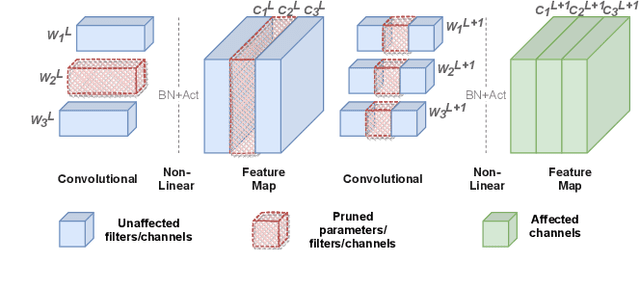
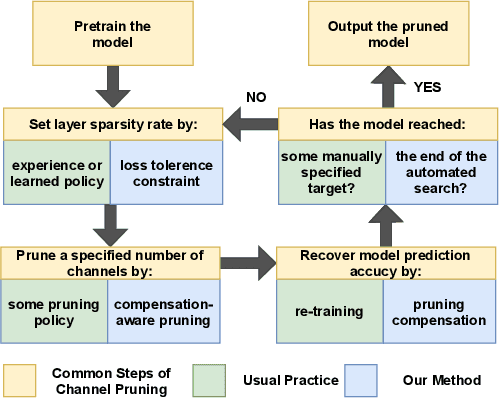
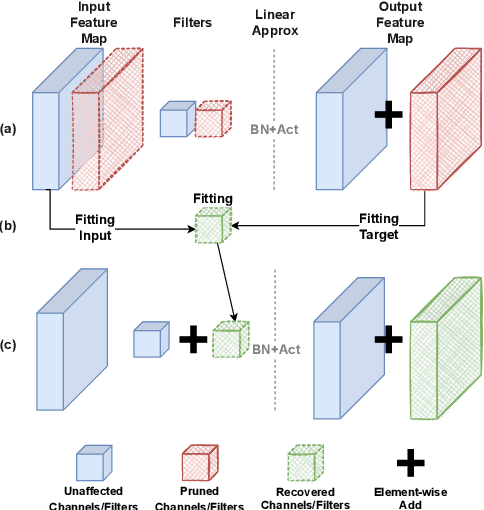
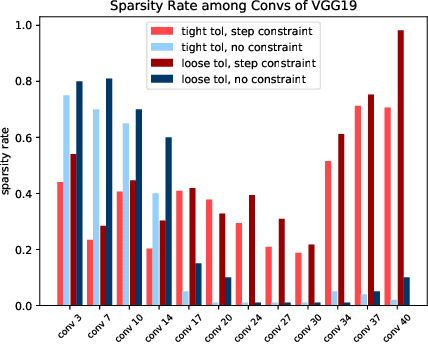
Channel pruning is a promising technique to compress the parameters of deep convolutional neural networks(DCNN) and to speed up the inference. This paper aims to address the long-standing inefficiency of channel pruning. Most channel pruning methods recover the prediction accuracy by re-training the pruned model from the remaining parameters or random initialization. This re-training process is heavily dependent on the sufficiency of computational resources, training data, and human interference(tuning the training strategy). In this paper, a highly efficient pruning method is proposed to significantly reduce the cost of pruning DCNN. The main contributions of our method include: 1) pruning compensation, a fast and data-efficient substitute of re-training to minimize the post-pruning reconstruction loss of features, 2) compensation-aware pruning(CaP), a novel pruning algorithm to remove redundant or less-weighted channels by minimizing the loss of information, and 3) binary structural search with step constraint to minimize human interference. On benchmarks including CIFAR-10/100 and ImageNet, our method shows competitive pruning performance among the state-of-the-art retraining-based pruning methods and, more importantly, reduces the processing time by 95% and data usage by 90%.
Predicting Critical Nodes in Temporal Networks by Dynamic Graph Convolutional Networks
Jul 06, 2021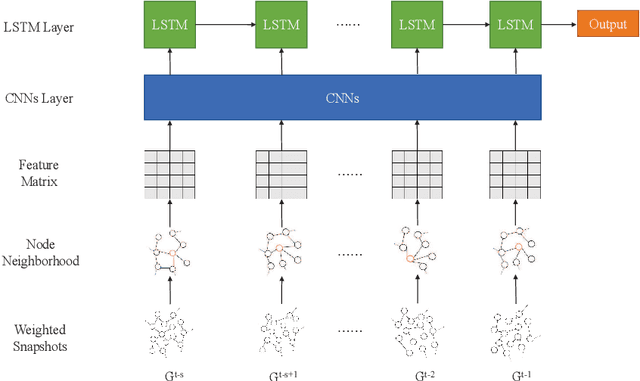
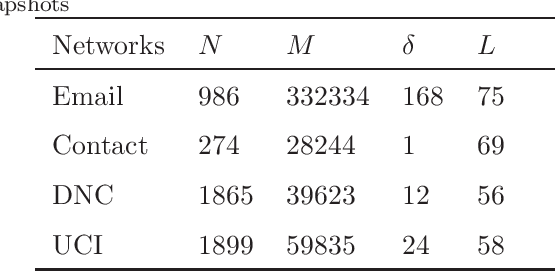


Many real-world systems can be expressed in temporal networks with nodes playing far different roles in structure and function and edges representing the relationships between nodes. Identifying critical nodes can help us control the spread of public opinions or epidemics, predict leading figures in academia, conduct advertisements for various commodities, and so on. However, it is rather difficult to identify critical nodes because the network structure changes over time in temporal networks. In this paper, considering the sequence topological information of temporal networks, a novel and effective learning framework based on the combination of special GCNs and RNNs is proposed to identify nodes with the best spreading ability. The effectiveness of the approach is evaluated by weighted Susceptible-Infected-Recovered model. Experimental results on four real-world temporal networks demonstrate that the proposed method outperforms both traditional and deep learning benchmark methods in terms of the Kendall $\tau$ coefficient and top $k$ hit rate.
A Graph Neural Network Approach for Product Relationship Prediction
May 12, 2021
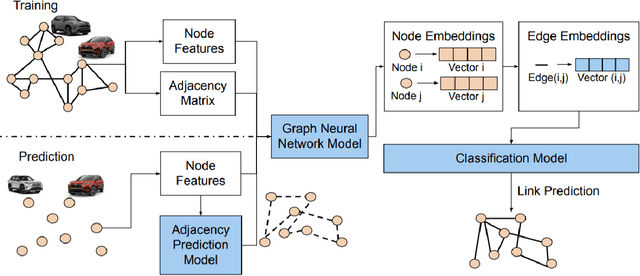
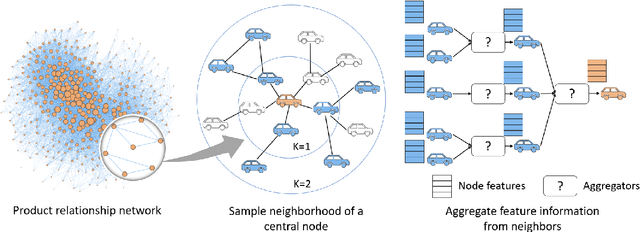
Graph Neural Networks have revolutionized many machine learning tasks in recent years, ranging from drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, or engineering attributes. They are combined with a classification model for predicting the existence of the relationship between products. Using a case study of the Chinese car market, we find that our method yields double the prediction performance compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla GraphSAGE requires a partial network to make predictions, we introduce an `adjacency prediction model' to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. This work provides a systematic method to predict the relationships between products in many different markets.
Reinforced Multi-Teacher Selection for Knowledge Distillation
Dec 14, 2020
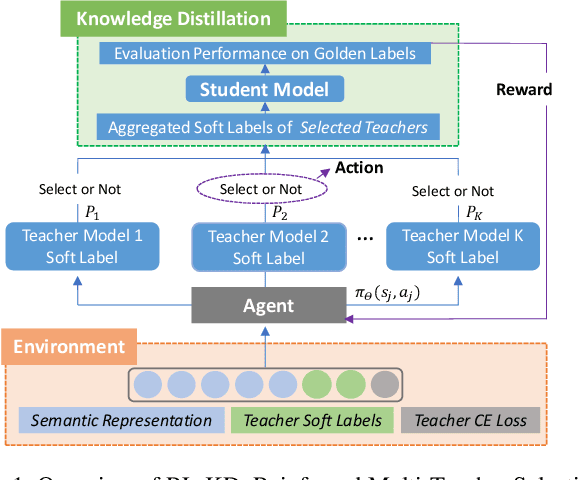

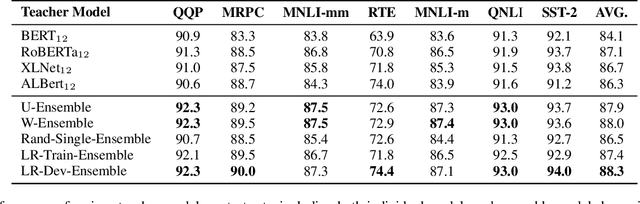
In natural language processing (NLP) tasks, slow inference speed and huge footprints in GPU usage remain the bottleneck of applying pre-trained deep models in production. As a popular method for model compression, knowledge distillation transfers knowledge from one or multiple large (teacher) models to a small (student) model. When multiple teacher models are available in distillation, the state-of-the-art methods assign a fixed weight to a teacher model in the whole distillation. Furthermore, most of the existing methods allocate an equal weight to every teacher model. In this paper, we observe that, due to the complexity of training examples and the differences in student model capability, learning differentially from teacher models can lead to better performance of student models distilled. We systematically develop a reinforced method to dynamically assign weights to teacher models for different training instances and optimize the performance of student model. Our extensive experimental results on several NLP tasks clearly verify the feasibility and effectiveness of our approach.