 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Multi-Teacher Selection for Knowledge Distillation
Dec 14, 2020
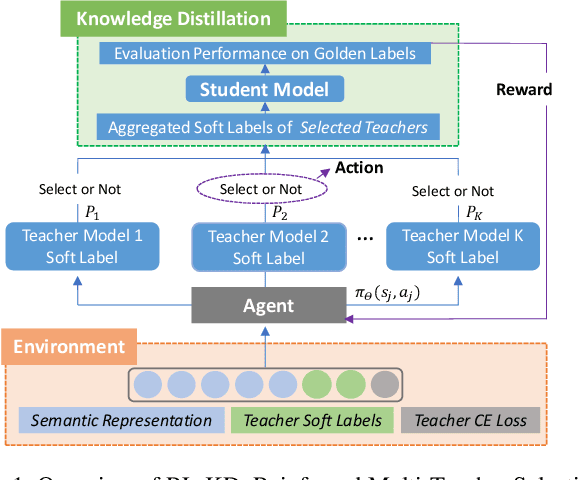

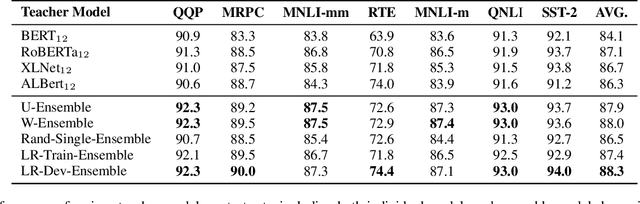
In natural language processing (NLP) tasks, slow inference speed and huge footprints in GPU usage remain the bottleneck of applying pre-trained deep models in production. As a popular method for model compression, knowledge distillation transfers knowledge from one or multiple large (teacher) models to a small (student) model. When multiple teacher models are available in distillation, the state-of-the-art methods assign a fixed weight to a teacher model in the whole distillation. Furthermore, most of the existing methods allocate an equal weight to every teacher model. In this paper, we observe that, due to the complexity of training examples and the differences in student model capability, learning differentially from teacher models can lead to better performance of student models distilled. We systematically develop a reinforced method to dynamically assign weights to teacher models for different training instances and optimize the performance of student model. Our extensive experimental results on several NLP tasks clearly verify the feasibility and effectiveness of our approach.
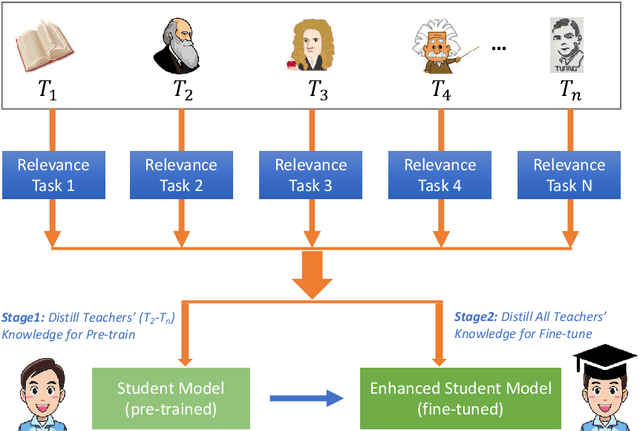
Model Compression with Two-stage Multi-teacher Knowledge Distillation for Web Question Answering System
Oct 18, 2019
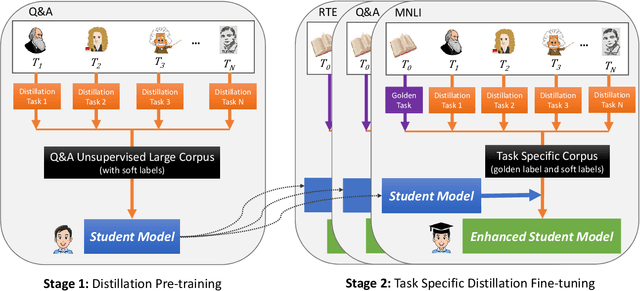

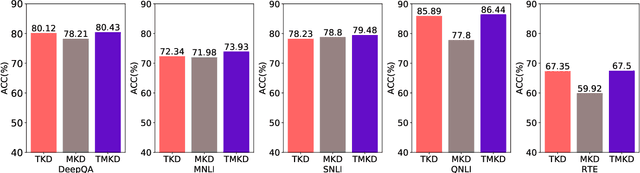
Deep pre-training and fine-tuning models (such as BERT and OpenAI GPT) have demonstrated excellent results in question answering areas. However, due to the sheer amount of model parameters, the inference speed of these models is very slow. How to apply these complex models to real business scenarios becomes a challenging but practical problem. Previous model compression methods usually suffer from information loss during the model compression procedure, leading to inferior models compared with the original one. To tackle this challenge, we propose a Two-stage Multi-teacher Knowledge Distillation (TMKD for short) method for web Question Answering system. We first develop a general Q\&A distillation task for student model pre-training, and further fine-tune this pre-trained student model with multi-teacher knowledge distillation on downstream tasks (like Web Q\&A task, MNLI, SNLI, RTE tasks from GLUE), which effectively reduces the overfitting bias in individual teacher models, and transfers more general knowledge to the student model. The experiment results show that our method can significantly outperform the baseline methods and even achieve comparable results with the original teacher models, along with substantial speedup of model inference.
Model Compression with Multi-Task Knowledge Distillation for Web-scale Question Answering System
Apr 21, 2019
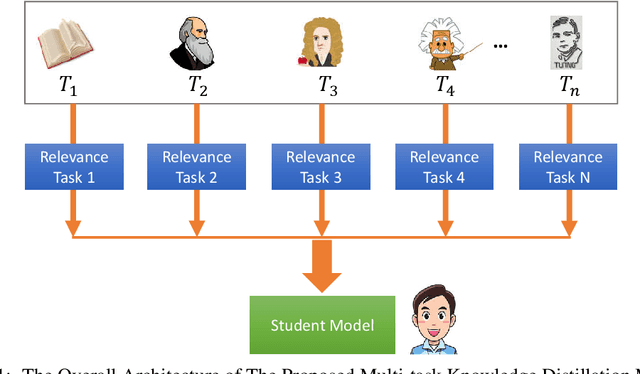

Deep pre-training and fine-tuning models (like BERT, OpenAI GPT) have demonstrated excellent results in question answering areas. However, due to the sheer amount of model parameters, the inference speed of these models is very slow. How to apply these complex models to real business scenarios becomes a challenging but practical problem. Previous works often leverage model compression approaches to resolve this problem. However, these methods usually induce information loss during the model compression procedure, leading to incomparable results between compressed model and the original model. To tackle this challenge, we propose a Multi-task Knowledge Distillation Model (MKDM for short) for web-scale Question Answering system, by distilling knowledge from multiple teacher models to a light-weight student model. In this way, more generalized knowledge can be transferred. The experiment results show that our method can significantly outperform the baseline methods and even achieve comparable results with the original teacher models, along with significant speedup of model inference.
NeuronBlocks -- Building Your NLP DNN Models Like Playing Lego
Apr 21, 2019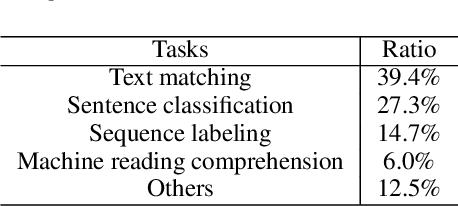
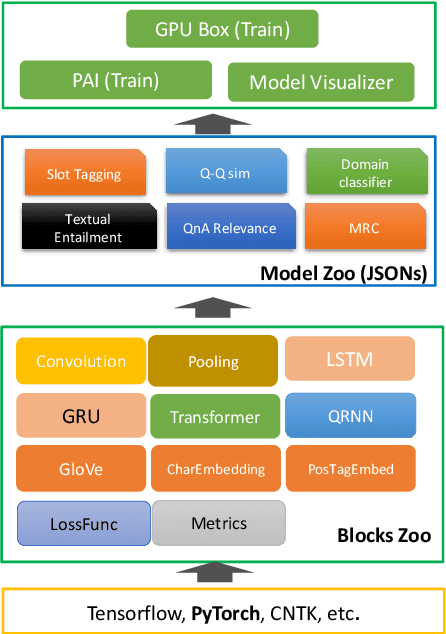
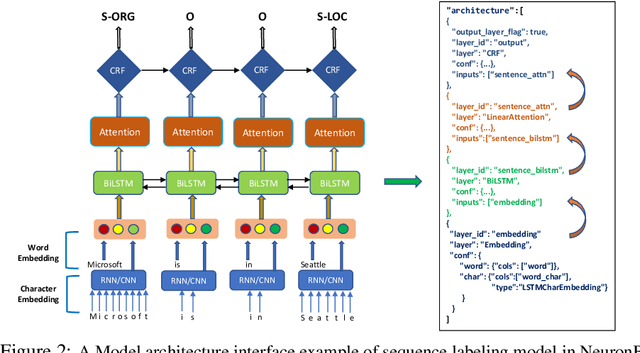
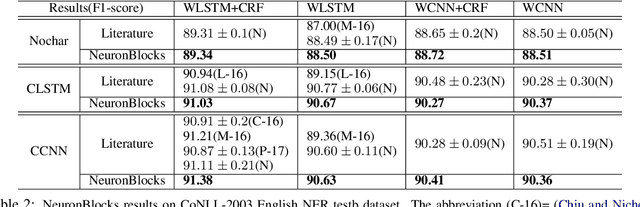
When building deep neural network models for natural language processing tasks, engineers often spend a lot of efforts on coding details and debugging, instead of focusing on model architecture design and hyper-parameter tuning. In this paper, we introduce NeuronBlocks, a deep neural network toolkit for natural language processing tasks. In NeuronBlocks, a suite of neural network layers are encapsulated as building blocks, which can easily be used to build complicated deep neural network models by configuring a simple JSON file. NeuronBlocks empowers engineers to build and train various NLP models in seconds even without a single line of code. A series of experiments on real NLP datasets such as GLUE and WikiQA have been conducted, which demonstrates the effectiveness of NeuronBlocks.