 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelism and Generation Order in Masked Diffusion Language Models: Limits Today, Potential Tomorrow
Jan 22, 2026Masked Diffusion Language Models (MDLMs) promise parallel token generation and arbitrary-order decoding, yet it remains unclear to what extent current models truly realize these capabilities. We characterize MDLM behavior along two dimensions -- parallelism strength and generation order -- using Average Finalization Parallelism (AFP) and Kendall's tau. We evaluate eight mainstream MDLMs (up to 100B parameters) on 58 benchmarks spanning knowledge, reasoning, and programming. The results show that MDLMs still lag behind comparably sized autoregressive models, mainly because parallel probabilistic modeling weakens inter-token dependencies. Meanwhile, MDLMs exhibit adaptive decoding behavior: their parallelism and generation order vary significantly with the task domain, the stage of reasoning, and whether the output is correct. On tasks that require "backward information" (e.g., Sudoku), MDLMs adopt a solution order that tends to fill easier Sudoku blanks first, highlighting their advantages. Finally, we provide theoretical motivation and design insights supporting a Generate-then-Edit paradigm, which mitigates dependency loss while retaining the efficiency of parallel decoding.
Training-Trajectory-Aware Token Selection
Jan 15, 2026Efficient distillation is a key pathway for converting expensive reasoning capability into deployable efficiency, yet in the frontier regime where the student already has strong reasoning ability, naive continual distillation often yields limited gains or even degradation. We observe a characteristic training phenomenon: even as loss decreases monotonically, all performance metrics can drop sharply at almost the same bottleneck, before gradually recovering. We further uncover a token-level mechanism: confidence bifurcates into steadily increasing Imitation-Anchor Tokens that quickly anchor optimization and other yet-to-learn tokens whose confidence is suppressed until after the bottleneck. And the characteristic that these two types of tokens cannot coexist is the root cause of the failure in continual distillation. To this end, we propose Training-Trajectory-Aware Token Selection (T3S) to reconstruct the training objective at the token level, clearing the optimization path for yet-to-learn tokens. T3 yields consistent gains in both AR and dLLM settings: with only hundreds of examples, Qwen3-8B surpasses DeepSeek-R1 on competitive reasoning benchmarks, Qwen3-32B approaches Qwen3-235B, and T3-trained LLaDA-2.0-Mini exceeds its AR baseline, achieving state-of-the-art performance among all of 16B-scale no-think models.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
TableGPT-R1: Advancing Tabular Reasoning Through Reinforcement Learning
Dec 23, 2025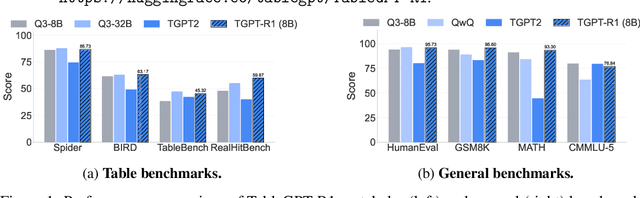
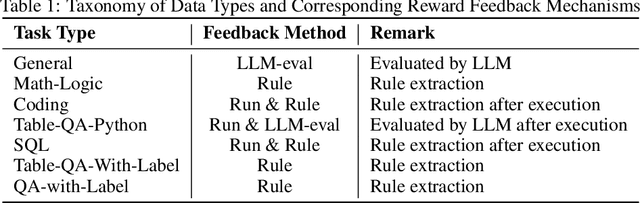
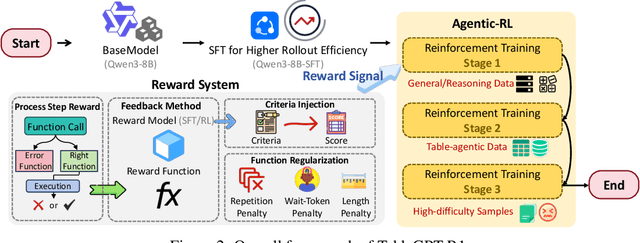
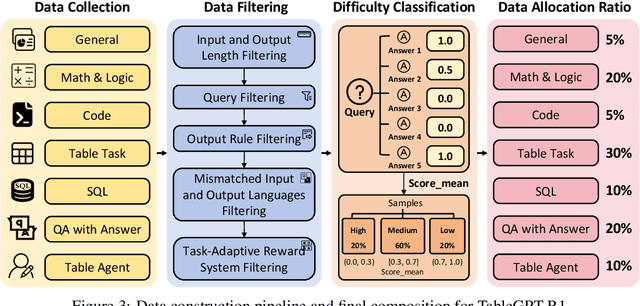
Tabular data serves as the backbone of modern data analysis and scientific research. While Large Language Models (LLMs) fine-tuned via Supervised Fine-Tuning (SFT) have significantly improved natural language interaction with such structured data, they often fall short in handling the complex, multi-step reasoning and robust code execution required for real-world table tasks. Reinforcement Learning (RL) offers a promising avenue to enhance these capabilities, yet its application in the tabular domain faces three critical hurdles: the scarcity of high-quality agentic trajectories with closed-loop code execution and environment feedback on diverse table structures, the extreme heterogeneity of feedback signals ranging from rigid SQL execution to open-ended data interpretation, and the risk of catastrophic forgetting of general knowledge during vertical specialization. To overcome these challenges and unlock advanced reasoning on complex tables, we introduce \textbf{TableGPT-R1}, a specialized tabular model built on a systematic RL framework. Our approach integrates a comprehensive data engineering pipeline that synthesizes difficulty-stratified agentic trajectories for both supervised alignment and RL rollouts, a task-adaptive reward system that combines rule-based verification with a criteria-injected reward model and incorporates process-level step reward shaping with behavioral regularization, and a multi-stage training framework that progressively stabilizes reasoning before specializing in table-specific tasks. Extensive evaluations demonstrate that TableGPT-R1 achieves state-of-the-art performance on authoritative benchmarks, significantly outperforming baseline models while retaining robust general capabilities. Our model is available at https://huggingface.co/tablegpt/TableGPT-R1.
Multi-Task-oriented Nighttime Haze Imaging Enhancer for Vision-driven Measurement Systems
Feb 11, 2025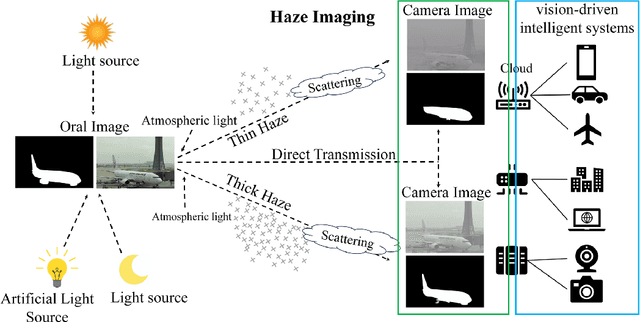
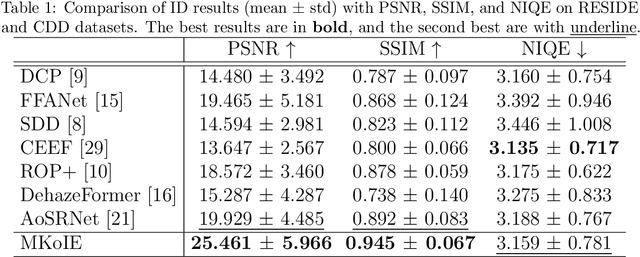
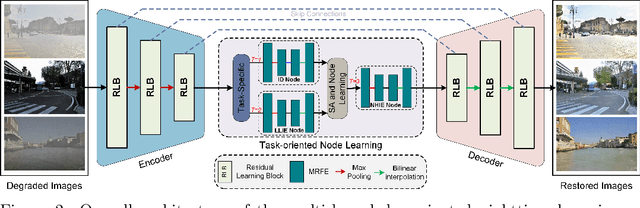
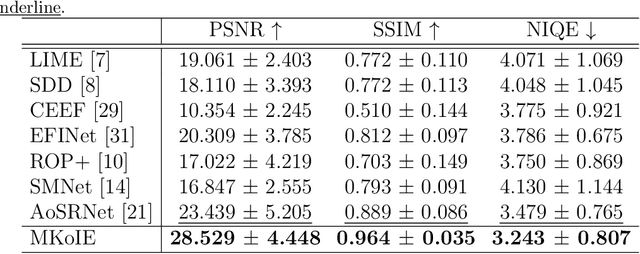
Salient object detection (SOD) plays a critical role in vision-driven measurement systems (VMS), facilitating the detection and segmentation of key visual elements in an image. However, adverse imaging conditions such as haze during the day, low light, and haze at night severely degrade image quality, and complicating the SOD process. To address these challenges, we propose a multi-task-oriented nighttime haze imaging enhancer (MToIE), which integrates three tasks: daytime dehazing, low-light enhancement, and nighttime dehazing. The MToIE incorporates two key innovative components: First, the network employs a task-oriented node learning mechanism to handle three specific degradation types: day-time haze, low light, and night-time haze conditions, with an embedded self-attention module enhancing its performance in nighttime imaging. In addition, multi-receptive field enhancement module that efficiently extracts multi-scale features through three parallel depthwise separable convolution branches with different dilation rates, capturing comprehensive spatial information with minimal computational overhead. To ensure optimal image reconstruction quality and visual characteristics, we suggest a hybrid loss function. Extensive experiments on different types of weather/imaging conditions illustrate that MToIE surpasses existing methods, significantly enhancing the accuracy and reliability of vision systems across diverse imaging scenarios. The code is available at https://github.com/Ai-Chen-Lab/MToIE.
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Nov 04, 2024The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact.
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
Aug 07, 2023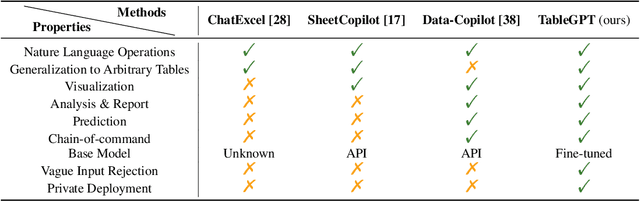



Tables are prevalent in real-world databases, requiring significant time and effort for humans to analyze and manipulate. The advancements in large language models (LLMs) have made it possible to interact with tables using natural language input, bringing this capability closer to reality. In this paper, we present TableGPT, a unified fine-tuned framework that enables LLMs to understand and operate on tables using external functional commands. It introduces the capability to seamlessly interact with tables, enabling a wide range of functionalities such as question answering, data manipulation (e.g., insert, delete, query, and modify operations), data visualization, analysis report generation, and automated prediction. TableGPT aims to provide convenience and accessibility to users by empowering them to effortlessly leverage tabular data. At the core of TableGPT lies the novel concept of global tabular representations, which empowers LLMs to gain a comprehensive understanding of the entire table beyond meta-information. By jointly training LLMs on both table and text modalities, TableGPT achieves a deep understanding of tabular data and the ability to perform complex operations on tables through chain-of-command instructions. Importantly, TableGPT offers the advantage of being a self-contained system rather than relying on external API interfaces. Moreover, it supports efficient data process flow, query rejection (when appropriate) and private deployment, enabling faster domain data fine-tuning and ensuring data privacy, which enhances the framework's adaptability to specific use cases.
Pruning with Compensation: Efficient Channel Pruning for Deep Convolutional Neural Networks
Aug 31, 2021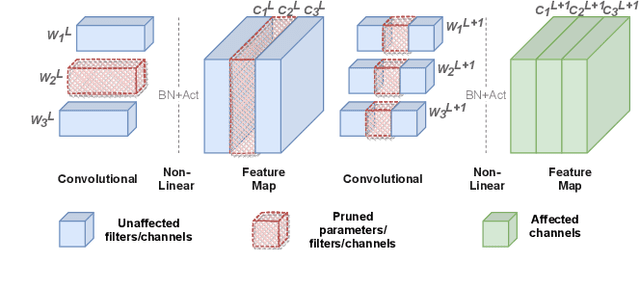
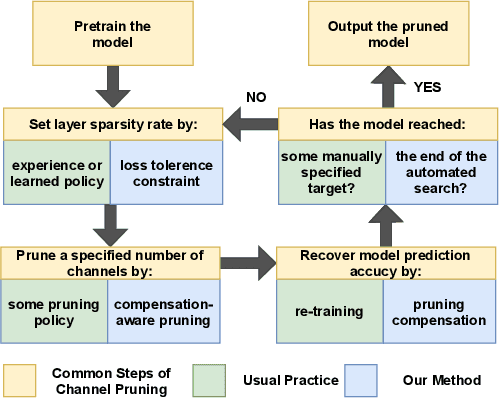
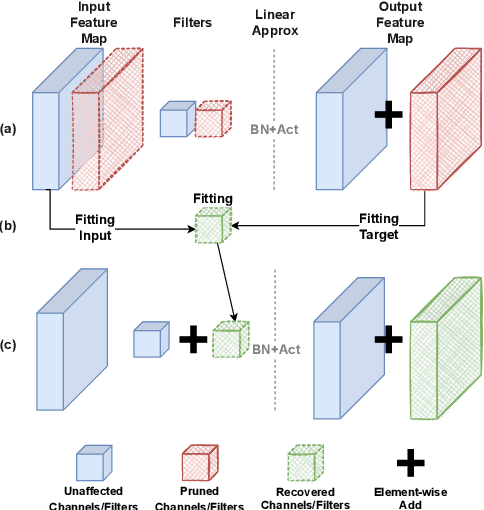
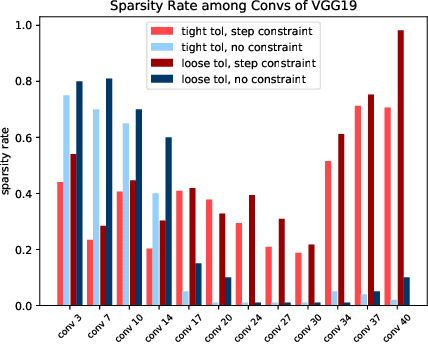
Channel pruning is a promising technique to compress the parameters of deep convolutional neural networks(DCNN) and to speed up the inference. This paper aims to address the long-standing inefficiency of channel pruning. Most channel pruning methods recover the prediction accuracy by re-training the pruned model from the remaining parameters or random initialization. This re-training process is heavily dependent on the sufficiency of computational resources, training data, and human interference(tuning the training strategy). In this paper, a highly efficient pruning method is proposed to significantly reduce the cost of pruning DCNN. The main contributions of our method include: 1) pruning compensation, a fast and data-efficient substitute of re-training to minimize the post-pruning reconstruction loss of features, 2) compensation-aware pruning(CaP), a novel pruning algorithm to remove redundant or less-weighted channels by minimizing the loss of information, and 3) binary structural search with step constraint to minimize human interference. On benchmarks including CIFAR-10/100 and ImageNet, our method shows competitive pruning performance among the state-of-the-art retraining-based pruning methods and, more importantly, reduces the processing time by 95% and data usage by 90%.
Tool Breakage Detection using Deep Learning
Aug 16, 2018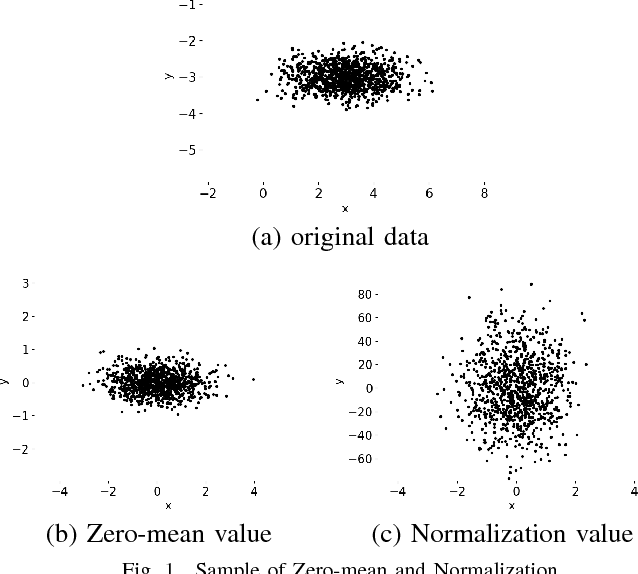
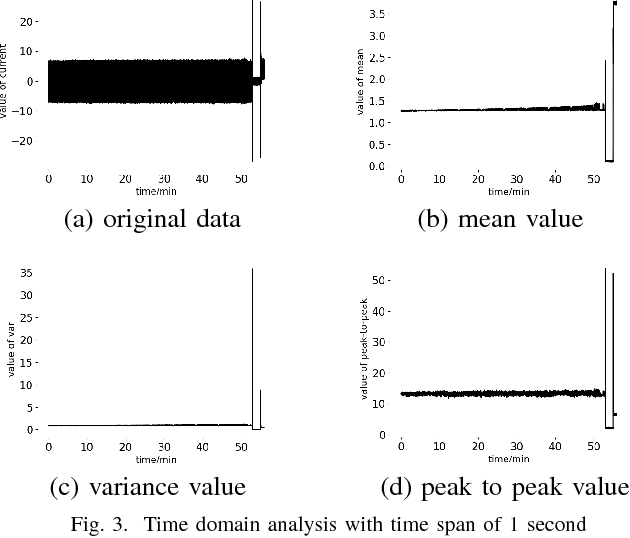
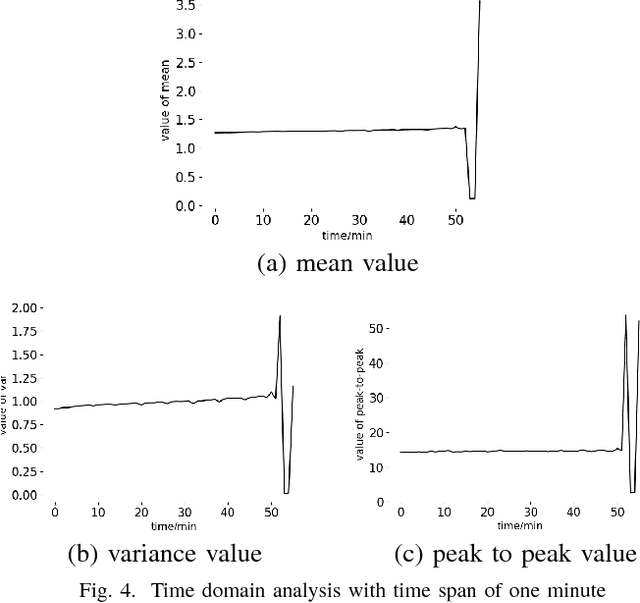
In manufacture, steel and other metals are mainly cut and shaped during the fabrication process by computer numerical control (CNC) machines. To keep high productivity and efficiency of the fabrication process, engineers need to monitor the real-time process of CNC machines, and the lifetime management of machine tools. In a real manufacturing process, breakage of machine tools usually happens without any indication, this problem seriously affects the fabrication process for many years. Previous studies suggested many different approaches for monitoring and detecting the breakage of machine tools. However, there still exists a big gap between academic experiments and the complex real fabrication processes such as the high demands of real-time detections, the difficulty in data acquisition and transmission. In this work, we use the spindle current approach to detect the breakage of machine tools, which has the high performance of real-time monitoring, low cost, and easy to install. We analyze the features of the current of a milling machine spindle through tools wearing processes, and then we predict the status of tool breakage by a convolutional neural network(CNN). In addition, we use a BP neural network to understand the reliability of the CNN. The results show that our CNN approach can detect tool breakage with an accuracy of 93%, while the best performance of BP is 80%.