 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHI-Series Algorithms A Hybrid of Substance Diffusion Algorithm and Collaborative Filtering
Mar 03, 2025



Recommendation systems face the challenge of balancing accuracy and diversity, as traditional collaborative filtering (CF) and network-based diffusion algorithms exhibit complementary limitations. While item-based CF (ItemCF) enhances diversity through item similarity, it compromises accuracy. Conversely, mass diffusion (MD) algorithms prioritize accuracy by favoring popular items but lack diversity. To address this trade-off, we propose the HI-series algorithms, hybrid models integrating ItemCF with diffusion-based approaches (MD, HHP, BHC, BD) through a nonlinear combination controlled by parameter $\epsilon$. This hybridization leverages ItemCF's diversity and MD's accuracy, extending to advanced diffusion models (HI-HHP, HI-BHC, HI-BD) for enhanced performance. Experiments on MovieLens, Netflix, and RYM datasets demonstrate that HI-series algorithms significantly outperform their base counterparts. In sparse data ($20\%$ training), HI-MD achieves a $0.8\%$-$4.4\%$ improvement in F1-score over MD while maintaining higher diversity (Diversity@20: 459 vs. 396 on MovieLens). For dense data ($80\%$ training), HI-BD improves F1-score by $2.3\%$-$5.2\%$ compared to BD, with diversity gains up to $18.6\%$. Notably, hybrid models consistently enhance novelty in sparse settings and exhibit robust parameter adaptability. The results validate that strategic hybridization effectively breaks the accuracy-diversity trade-off, offering a flexible framework for optimizing recommendation systems across data sparsity levels.
Resource Mention Extraction for MOOC Discussion Forums
Nov 21, 2018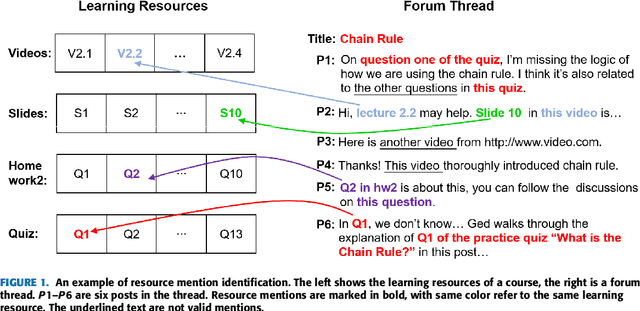
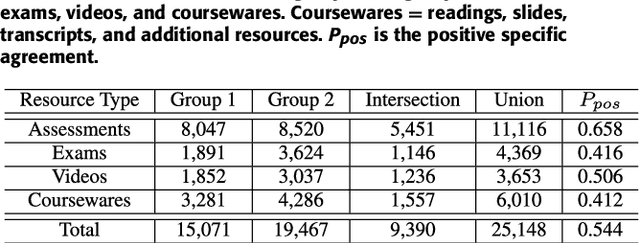

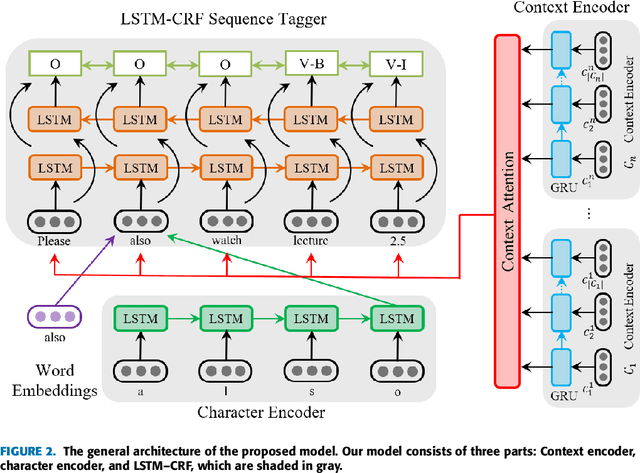
In discussions hosted on discussion forums for MOOCs, references to online learning resources are often of central importance. They contextualize the discussion, anchoring the discussion participants' presentation of the issues and their understanding. However they are usually mentioned in free text, without appropriate hyperlinking to their associated resource. Automated learning resource mention hyperlinking and categorization will facilitate discussion and searching within MOOC forums, and also benefit the contextualization of such resources across disparate views. We propose the novel problem of learning resource mention identification in MOOC forums. As this is a novel task with no publicly available data, we first contribute a large-scale labeled dataset, dubbed the Forum Resource Mention (FoRM) dataset, to facilitate our current research and future research on this task. We then formulate this task as a sequence tagging problem and investigate solution architectures to address the problem. Importantly, we identify two major challenges that hinder the application of sequence tagging models to the task: (1) the diversity of resource mention expression, and (2) long-range contextual dependencies. We address these challenges by incorporating character-level and thread context information into a LSTM-CRF model. First, we incorporate a character encoder to address the out-of-vocabulary problem caused by the diversity of mention expressions. Second, to address the context dependency challenge, we encode thread contexts using an RNN-based context encoder, and apply the attention mechanism to selectively leverage useful context information during sequence tagging. Experiments on FoRM show that the proposed method improves the baseline deep sequence tagging models notably, significantly bettering performance on instances that exemplify the two challenges.