 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMG-Agent: Toward Robust Missing Modality Generation with Decoupled Coarse-to-Fine Agentic Workflows
Feb 04, 2026Data incompleteness severely impedes the reliability of multimodal systems. Existing reconstruction methods face distinct bottlenecks: conventional parametric/generative models are prone to hallucinations due to over-reliance on internal memory, while retrieval-augmented frameworks struggle with retrieval rigidity. Critically, these end-to-end architectures are fundamentally constrained by Semantic-Detail Entanglement -- a structural conflict between logical reasoning and signal synthesis that compromises fidelity. In this paper, we present \textbf{\underline{O}}mni-\textbf{\underline{M}}odality \textbf{\underline{G}}eneration Agent (\textbf{OMG-Agent}), a novel framework that shifts the paradigm from static mapping to a dynamic coarse-to-fine Agentic Workflow. By mimicking a \textit{deliberate-then-act} cognitive process, OMG-Agent explicitly decouples the task into three synergistic stages: (1) an MLLM-driven Semantic Planner that resolves input ambiguity via Progressive Contextual Reasoning, creating a deterministic structured semantic plan; (2) a non-parametric Evidence Retriever that grounds abstract semantics in external knowledge; and (3) a Retrieval-Injected Executor that utilizes retrieved evidence as flexible feature prompts to overcome rigidity and synthesize high-fidelity details. Extensive experiments on multiple benchmarks demonstrate that OMG-Agent consistently surpasses state-of-the-art methods, maintaining robustness under extreme missingness, e.g., a $2.6$-point gain on CMU-MOSI at $70$\% missing rates.
MuAP: Multi-step Adaptive Prompt Learning for Vision-Language Model with Missing Modality
Sep 07, 2024



Recently, prompt learning has garnered considerable attention for its success in various Vision-Language (VL) tasks. However, existing prompt-based models are primarily focused on studying prompt generation and prompt strategies with complete modality settings, which does not accurately reflect real-world scenarios where partial modality information may be missing. In this paper, we present the first comprehensive investigation into prompt learning behavior when modalities are incomplete, revealing the high sensitivity of prompt-based models to missing modalities. To this end, we propose a novel Multi-step Adaptive Prompt Learning (MuAP) framework, aiming to generate multimodal prompts and perform multi-step prompt tuning, which adaptively learns knowledge by iteratively aligning modalities. Specifically, we generate multimodal prompts for each modality and devise prompt strategies to integrate them into the Transformer model. Subsequently, we sequentially perform prompt tuning from single-stage and alignment-stage, allowing each modality-prompt to be autonomously and adaptively learned, thereby mitigating the imbalance issue caused by only textual prompts that are learnable in previous works. Extensive experiments demonstrate the effectiveness of our MuAP and this model achieves significant improvements compared to the state-of-the-art on all benchmark datasets
G-SAP: Graph-based Structure-Aware Prompt Learning over Heterogeneous Knowledge for Commonsense Reasoning
May 09, 2024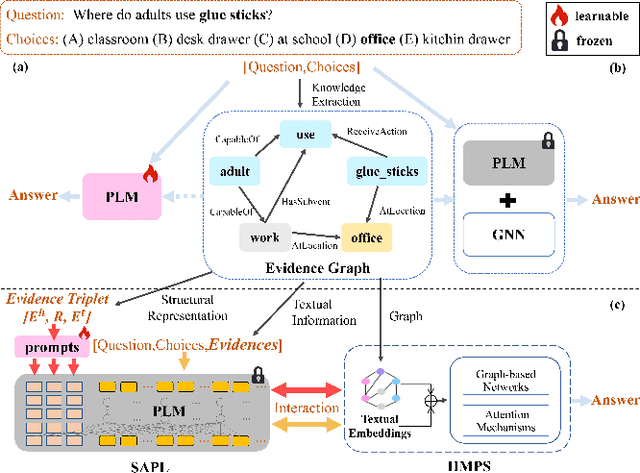
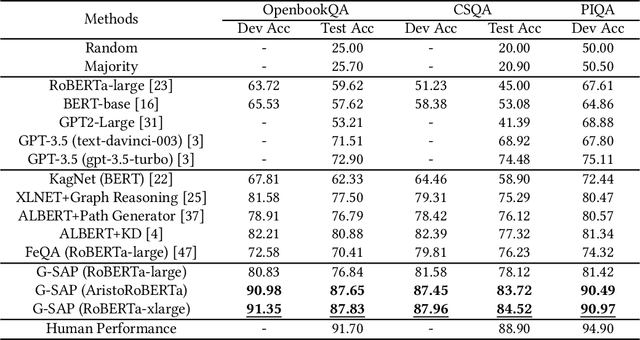
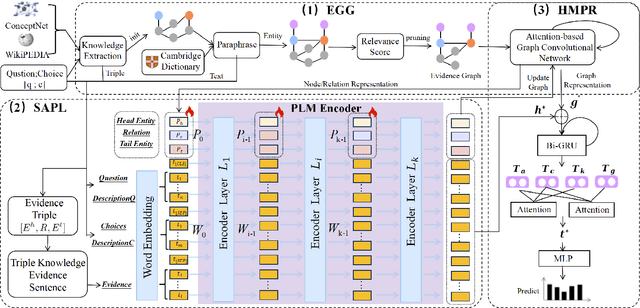
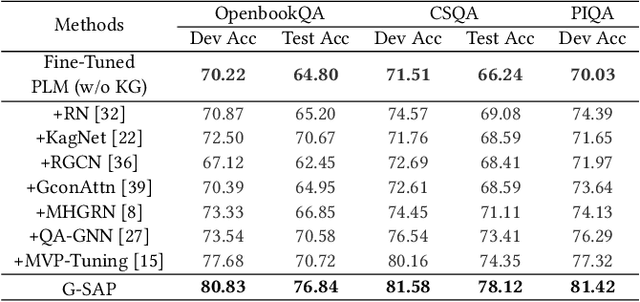
Commonsense question answering has demonstrated considerable potential across various applications like assistants and social robots. Although fully fine-tuned pre-trained Language Models(LM) have achieved remarkable performance in commonsense reasoning, their tendency to excessively prioritize textual information hampers the precise transfer of structural knowledge and undermines interpretability. Some studies have explored combining LMs with Knowledge Graphs(KGs) by coarsely fusing the two modalities to perform Graph Neural Network(GNN)-based reasoning that lacks a profound interaction between heterogeneous modalities. In this paper, we propose a novel Graph-based Structure-Aware Prompt Learning Model for commonsense reasoning, named G-SAP, aiming to maintain a balance between heterogeneous knowledge and enhance the cross-modal interaction within the LM+GNNs model. In particular, an evidence graph is constructed by integrating multiple knowledge sources, i.e. ConceptNet, Wikipedia, and Cambridge Dictionary to boost the performance. Afterward, a structure-aware frozen PLM is employed to fully incorporate the structured and textual information from the evidence graph, where the generation of prompts is driven by graph entities and relations. Finally, a heterogeneous message-passing reasoning module is used to facilitate deep interaction of knowledge between the LM and graph-based networks. Empirical validation, conducted through extensive experiments on three benchmark datasets, demonstrates the notable performance of the proposed model. The results reveal a significant advancement over the existing models, especially, with 6.12% improvement over the SoTA LM+GNNs model on the OpenbookQA dataset.
Multi-modal Representation Learning for Social Post Location Inference
Jun 11, 2023



Inferring geographic locations via social posts is essential for many practical location-based applications such as product marketing, point-of-interest recommendation, and infector tracking for COVID-19. Unlike image-based location retrieval or social-post text embedding-based location inference, the combined effect of multi-modal information (i.e., post images, text, and hashtags) for social post positioning receives less attention. In this work, we collect real datasets of social posts with images, texts, and hashtags from Instagram and propose a novel Multi-modal Representation Learning Framework (MRLF) capable of fusing different modalities of social posts for location inference. MRLF integrates a multi-head attention mechanism to enhance location-salient information extraction while significantly improving location inference compared with single domain-based methods. To overcome the noisy user-generated textual content, we introduce a novel attention-based character-aware module that considers the relative dependencies between characters of social post texts and hashtags for flexible multi-model information fusion. The experimental results show that MRLF can make accurate location predictions and open a new door to understanding the multi-modal data of social posts for online inference tasks.