 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
NeuroPath: Neurobiology-Inspired Path Tracking and Reflection for Semantically Coherent Retrieval
Nov 18, 2025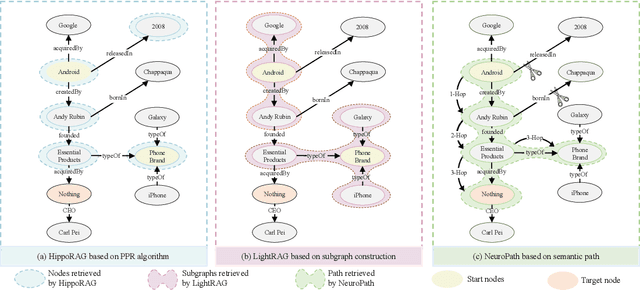
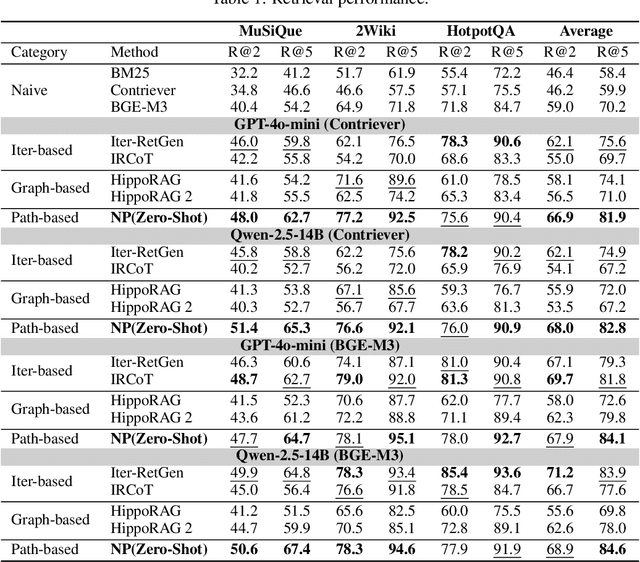
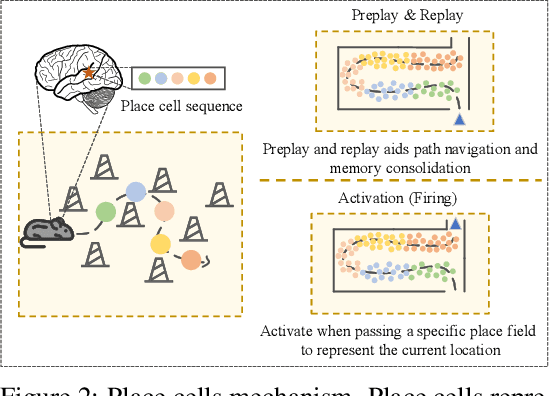
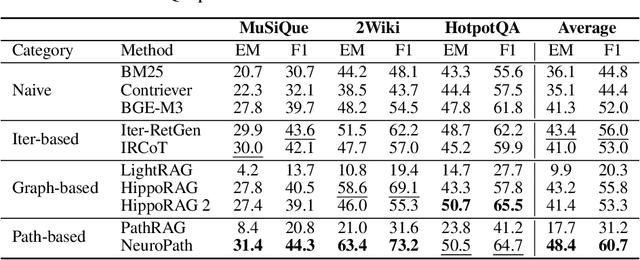
Retrieval-augmented generation (RAG) greatly enhances large language models (LLMs) performance in knowledge-intensive tasks. However, naive RAG methods struggle with multi-hop question answering due to their limited capacity to capture complex dependencies across documents. Recent studies employ graph-based RAG to capture document connections. However, these approaches often result in a loss of semantic coherence and introduce irrelevant noise during node matching and subgraph construction. To address these limitations, we propose NeuroPath, an LLM-driven semantic path tracking RAG framework inspired by the path navigational planning of place cells in neurobiology. It consists of two steps: Dynamic Path Tracking and Post-retrieval Completion. Dynamic Path Tracking performs goal-directed semantic path tracking and pruning over the constructed knowledge graph (KG), improving noise reduction and semantic coherence. Post-retrieval Completion further reinforces these benefits by conducting second-stage retrieval using intermediate reasoning and the original query to refine the query goal and complete missing information in the reasoning path. NeuroPath surpasses current state-of-the-art baselines on three multi-hop QA datasets, achieving average improvements of 16.3% on recall@2 and 13.5% on recall@5 over advanced graph-based RAG methods. Moreover, compared to existing iter-based RAG methods, NeuroPath achieves higher accuracy and reduces token consumption by 22.8%. Finally, we demonstrate the robustness of NeuroPath across four smaller LLMs (Llama3.1, GLM4, Mistral0.3, and Gemma3), and further validate its scalability across tasks of varying complexity. Code is available at https://github.com/KennyCaty/NeuroPath.
Hierarchical Graph Topic Modeling with Topic Tree-based Transformer
Feb 17, 2025Textual documents are commonly connected in a hierarchical graph structure where a central document links to others with an exponentially growing connectivity. Though Hyperbolic Graph Neural Networks (HGNNs) excel at capturing such graph hierarchy, they cannot model the rich textual semantics within documents. Moreover, text contents in documents usually discuss topics of different specificity. Hierarchical Topic Models (HTMs) discover such latent topic hierarchy within text corpora. However, most of them focus on the textual content within documents, and ignore the graph adjacency across interlinked documents. We thus propose a Hierarchical Graph Topic Modeling Transformer to integrate both topic hierarchy within documents and graph hierarchy across documents into a unified Transformer. Specifically, to incorporate topic hierarchy within documents, we design a topic tree and infer a hierarchical tree embedding for hierarchical topic modeling. To preserve both topic and graph hierarchies, we design our model in hyperbolic space and propose Hyperbolic Doubly Recurrent Neural Network, which models ancestral and fraternal tree structure. Both hierarchies are inserted into each Transformer layer to learn unified representations. Both supervised and unsupervised experiments verify the effectiveness of our model.
Low-Rank Adaptation for Foundation Models: A Comprehensive Review
Dec 31, 2024The rapid advancement of foundation modelslarge-scale neural networks trained on diverse, extensive datasetshas revolutionized artificial intelligence, enabling unprecedented advancements across domains such as natural language processing, computer vision, and scientific discovery. However, the substantial parameter count of these models, often reaching billions or trillions, poses significant challenges in adapting them to specific downstream tasks. Low-Rank Adaptation (LoRA) has emerged as a highly promising approach for mitigating these challenges, offering a parameter-efficient mechanism to fine-tune foundation models with minimal computational overhead. This survey provides the first comprehensive review of LoRA techniques beyond large Language Models to general foundation models, including recent techniques foundations, emerging frontiers and applications of low-rank adaptation across multiple domains. Finally, this survey discusses key challenges and future research directions in theoretical understanding, scalability, and robustness. This survey serves as a valuable resource for researchers and practitioners working with efficient foundation model adaptation.
Towards Pattern-aware Data Augmentation for Temporal Knowledge Graph Completion
Dec 31, 2024Predicting missing facts for temporal knowledge graphs (TKGs) is a fundamental task, called temporal knowledge graph completion (TKGC). One key challenge in this task is the imbalance in data distribution, where facts are unevenly spread across entities and timestamps. This imbalance can lead to poor completion performance or long-tail entities and timestamps, and unstable training due to the introduction of false negative samples. Unfortunately, few previous studies have investigated how to mitigate these effects. Moreover, for the first time, we found that existing methods suffer from model preferences, revealing that entities with specific properties (e.g., recently active) are favored by different models. Such preferences will lead to error accumulation and further exacerbate the effects of imbalanced data distribution, but are overlooked by previous studies. To alleviate the impacts of imbalanced data and model preferences, we introduce Booster, the first data augmentation strategy for TKGs. The unique requirements here lie in generating new samples that fit the complex semantic and temporal patterns within TKGs, and identifying hard-learning samples specific to models. Therefore, we propose a hierarchical scoring algorithm based on triadic closures within TKGs. By incorporating both global semantic patterns and local time-aware structures, the algorithm enables pattern-aware validation for new samples. Meanwhile, we propose a two-stage training approach to identify samples that deviate from the model's preferred patterns. With a well-designed frequency-based filtering strategy, this approach also helps to avoid the misleading of false negatives. Experiments justify that Booster can seamlessly adapt to existing TKGC models and achieve up to an 8.7% performance improvement.
GraphTool-Instruction: Revolutionizing Graph Reasoning in LLMs through Decomposed Subtask Instruction
Dec 11, 2024



Large language models (LLMs) have been demonstrated to possess the capabilities to understand fundamental graph properties and address various graph reasoning tasks. Existing methods fine-tune LLMs to understand and execute graph reasoning tasks by specially designed task instructions. However, these Text-Instruction methods generally exhibit poor performance. Inspired by tool learning, researchers propose Tool-Instruction methods to solve various graph problems by special tool calling (e.g., function, API and model), achieving significant improvements in graph reasoning tasks. Nevertheless, current Tool-Instruction approaches focus on the tool information and ignore the graph structure information, which leads to significantly inferior performance on small-scale LLMs (less than 13B). To tackle this issue, we propose GraphTool-Instruction, an innovative Instruction-tuning approach that decomposes the graph reasoning task into three distinct subtasks (i.e., graph extraction, tool name identification and tool parameter extraction), and design specialized instructions for each subtask. Our GraphTool-Instruction can be used as a plug-and-play prompt for different LLMs without fine-tuning. Moreover, building on GraphTool-Instruction, we develop GTools, a dataset that includes twenty graph reasoning tasks, and create a graph reasoning LLM called GraphForge based on Llama3-8B. We conduct extensive experiments on twenty graph reasoning tasks with different graph types (e.g., graph size or graph direction), and we find that GraphTool-Instruction achieves SOTA compared to Text-Instruction and Tool-Instruction methods. Fine-tuned on GTools, GraphForge gets further improvement of over 30% compared to the Tool-Instruction enhanced GPT-3.5-turbo, and it performs comparably to the high-cost GPT-4o. Our codes and data are available at https://anonymous.4open.science/r/GraphTool-Instruction.
Counterfactual Evaluation of Ads Ranking Models through Domain Adaptation
Sep 29, 2024We propose a domain-adapted reward model that works alongside an Offline A/B testing system for evaluating ranking models. This approach effectively measures reward for ranking model changes in large-scale Ads recommender systems, where model-free methods like IPS are not feasible. Our experiments demonstrate that the proposed technique outperforms both the vanilla IPS method and approaches using non-generalized reward models.
Online Detection of Anomalies in Temporal Knowledge Graphs with Interpretability
Aug 01, 2024Temporal knowledge graphs (TKGs) are valuable resources for capturing evolving relationships among entities, yet they are often plagued by noise, necessitating robust anomaly detection mechanisms. Existing dynamic graph anomaly detection approaches struggle to capture the rich semantics introduced by node and edge categories within TKGs, while TKG embedding methods lack interpretability, undermining the credibility of anomaly detection. Moreover, these methods falter in adapting to pattern changes and semantic drifts resulting from knowledge updates. To tackle these challenges, we introduce AnoT, an efficient TKG summarization method tailored for interpretable online anomaly detection in TKGs. AnoT begins by summarizing a TKG into a novel rule graph, enabling flexible inference of complex patterns in TKGs. When new knowledge emerges, AnoT maps it onto a node in the rule graph and traverses the rule graph recursively to derive the anomaly score of the knowledge. The traversal yields reachable nodes that furnish interpretable evidence for the validity or the anomalous of the new knowledge. Overall, AnoT embodies a detector-updater-monitor architecture, encompassing a detector for offline TKG summarization and online scoring, an updater for real-time rule graph updates based on emerging knowledge, and a monitor for estimating the approximation error of the rule graph. Experimental results on four real-world datasets demonstrate that AnoT surpasses existing methods significantly in terms of accuracy and interoperability. All of the raw datasets and the implementation of AnoT are provided in https://github.com/zjs123/ANoT.
DTGB: A Comprehensive Benchmark for Dynamic Text-Attributed Graphs
Jun 17, 2024



Dynamic text-attributed graphs (DyTAGs) are prevalent in various real-world scenarios, where each node and edge are associated with text descriptions, and both the graph structure and text descriptions evolve over time. Despite their broad applicability, there is a notable scarcity of benchmark datasets tailored to DyTAGs, which hinders the potential advancement in many research fields. To address this gap, we introduce Dynamic Text-attributed Graph Benchmark (DTGB), a collection of large-scale, time-evolving graphs from diverse domains, with nodes and edges enriched by dynamically changing text attributes and categories. To facilitate the use of DTGB, we design standardized evaluation procedures based on four real-world use cases: future link prediction, destination node retrieval, edge classification, and textual relation generation. These tasks require models to understand both dynamic graph structures and natural language, highlighting the unique challenges posed by DyTAGs. Moreover, we conduct extensive benchmark experiments on DTGB, evaluating 7 popular dynamic graph learning algorithms and their variants of adapting to text attributes with LLM embeddings, along with 6 powerful large language models (LLMs). Our results show the limitations of existing models in handling DyTAGs. Our analysis also demonstrates the utility of DTGB in investigating the incorporation of structural and textual dynamics. The proposed DTGB fosters research on DyTAGs and their broad applications. It offers a comprehensive benchmark for evaluating and advancing models to handle the interplay between dynamic graph structures and natural language. The dataset and source code are available at https://github.com/zjs123/DTGB.
Complex Locomotion Skill Learning via Differentiable Physics
Jun 06, 2022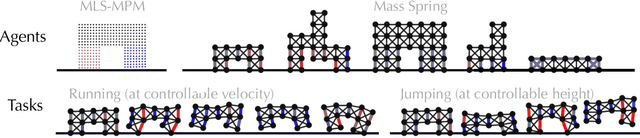



Differentiable physics enables efficient gradient-based optimizations of neural network (NN) controllers. However, existing work typically only delivers NN controllers with limited capability and generalizability. We present a practical learning framework that outputs unified NN controllers capable of tasks with significantly improved complexity and diversity. To systematically improve training robustness and efficiency, we investigated a suite of improvements over the baseline approach, including periodic activation functions, and tailored loss functions. In addition, we find our adoption of batching and an Adam optimizer effective in training complex locomotion tasks. We evaluate our framework on differentiable mass-spring and material point method (MPM) simulations, with challenging locomotion tasks and multiple robot designs. Experiments show that our learning framework, based on differentiable physics, delivers better results than reinforcement learning and converges much faster. We demonstrate that users can interactively control soft robot locomotion and switch among multiple goals with specified velocity, height, and direction instructions using a unified NN controller trained in our system.