 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random: Automatic Inner-loop Optimization in Dataset Distillation
Oct 06, 2025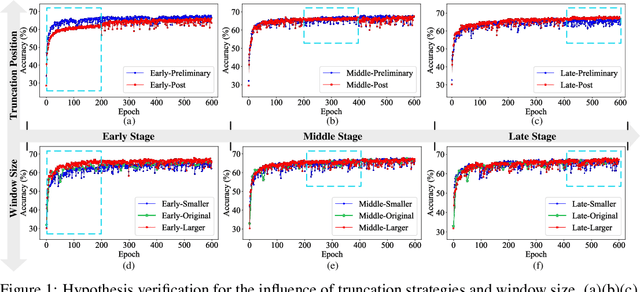
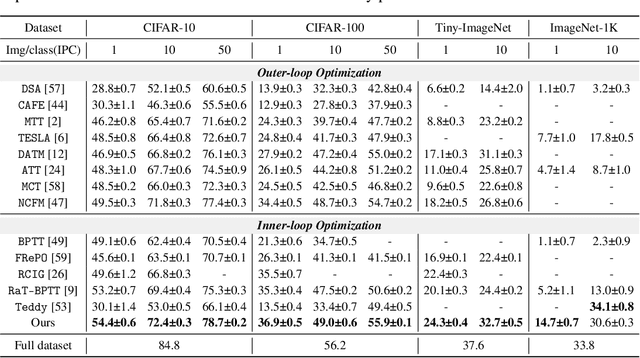
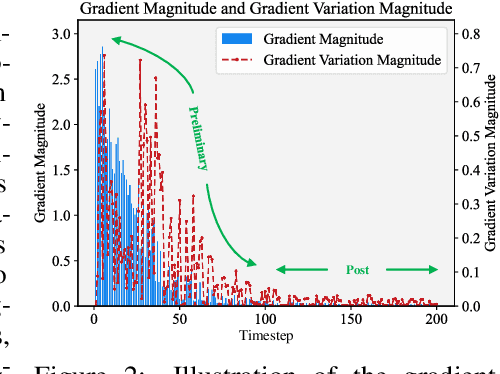
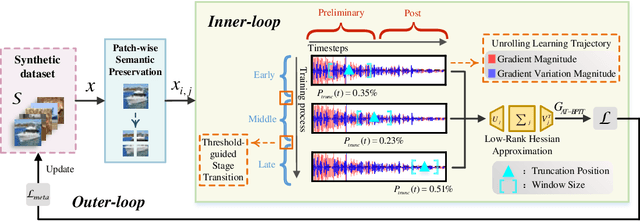
The growing demand for efficient deep learning has positioned dataset distillation as a pivotal technique for compressing training dataset while preserving model performance. However, existing inner-loop optimization methods for dataset distillation typically rely on random truncation strategies, which lack flexibility and often yield suboptimal results. In this work, we observe that neural networks exhibit distinct learning dynamics across different training stages-early, middle, and late-making random truncation ineffective. To address this limitation, we propose Automatic Truncated Backpropagation Through Time (AT-BPTT), a novel framework that dynamically adapts both truncation positions and window sizes according to intrinsic gradient behavior. AT-BPTT introduces three key components: (1) a probabilistic mechanism for stage-aware timestep selection, (2) an adaptive window sizing strategy based on gradient variation, and (3) a low-rank Hessian approximation to reduce computational overhead. Extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet-1K show that AT-BPTT achieves state-of-the-art performance, improving accuracy by an average of 6.16% over baseline methods. Moreover, our approach accelerates inner-loop optimization by 3.9x while saving 63% memory cost.
Towards Pattern-aware Data Augmentation for Temporal Knowledge Graph Completion
Dec 31, 2024Predicting missing facts for temporal knowledge graphs (TKGs) is a fundamental task, called temporal knowledge graph completion (TKGC). One key challenge in this task is the imbalance in data distribution, where facts are unevenly spread across entities and timestamps. This imbalance can lead to poor completion performance or long-tail entities and timestamps, and unstable training due to the introduction of false negative samples. Unfortunately, few previous studies have investigated how to mitigate these effects. Moreover, for the first time, we found that existing methods suffer from model preferences, revealing that entities with specific properties (e.g., recently active) are favored by different models. Such preferences will lead to error accumulation and further exacerbate the effects of imbalanced data distribution, but are overlooked by previous studies. To alleviate the impacts of imbalanced data and model preferences, we introduce Booster, the first data augmentation strategy for TKGs. The unique requirements here lie in generating new samples that fit the complex semantic and temporal patterns within TKGs, and identifying hard-learning samples specific to models. Therefore, we propose a hierarchical scoring algorithm based on triadic closures within TKGs. By incorporating both global semantic patterns and local time-aware structures, the algorithm enables pattern-aware validation for new samples. Meanwhile, we propose a two-stage training approach to identify samples that deviate from the model's preferred patterns. With a well-designed frequency-based filtering strategy, this approach also helps to avoid the misleading of false negatives. Experiments justify that Booster can seamlessly adapt to existing TKGC models and achieve up to an 8.7% performance improvement.
Label-template based Few-Shot Text Classification with Contrastive Learning
Dec 13, 2024



As an algorithmic framework for learning to learn, meta-learning provides a promising solution for few-shot text classification. However, most existing research fail to give enough attention to class labels. Traditional basic framework building meta-learner based on prototype networks heavily relies on inter-class variance, and it is easily influenced by noise. To address these limitations, we proposes a simple and effective few-shot text classification framework. In particular, the corresponding label templates are embed into input sentences to fully utilize the potential value of class labels, guiding the pre-trained model to generate more discriminative text representations through the semantic information conveyed by labels. With the continuous influence of label semantics, supervised contrastive learning is utilized to model the interaction information between support samples and query samples. Furthermore, the averaging mechanism is replaced with an attention mechanism to highlight vital semantic information. To verify the proposed scheme, four typical datasets are employed to assess the performance of different methods. Experimental results demonstrate that our method achieves substantial performance enhancements and outperforms existing state-of-the-art models on few-shot text classification tasks.