 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIVC-Prune: Revealing the Implicit Visual Coordinates in LVLMs for Vision Token Pruning
Feb 03, 2026Large Vision-Language Models (LVLMs) achieve impressive performance across multiple tasks. A significant challenge, however, is their prohibitive inference cost when processing high-resolution visual inputs. While visual token pruning has emerged as a promising solution, existing methods that primarily focus on semantic relevance often discard tokens that are crucial for spatial reasoning. We address this gap through a novel insight into \emph{how LVLMs process spatial reasoning}. Specifically, we reveal that LVLMs implicitly establish visual coordinate systems through Rotary Position Embeddings (RoPE), where specific token positions serve as \textbf{implicit visual coordinates} (IVC tokens) that are essential for spatial reasoning. Based on this insight, we propose \textbf{IVC-Prune}, a training-free, prompt-aware pruning strategy that retains both IVC tokens and semantically relevant foreground tokens. IVC tokens are identified by theoretically analyzing the mathematical properties of RoPE, targeting positions at which its rotation matrices approximate identity matrix or the $90^\circ$ rotation matrix. Foreground tokens are identified through a robust two-stage process: semantic seed discovery followed by contextual refinement via value-vector similarity. Extensive evaluations across four representative LVLMs and twenty diverse benchmarks show that IVC-Prune reduces visual tokens by approximately 50\% while maintaining $\geq$ 99\% of the original performance and even achieving improvements on several benchmarks. Source codes are available at https://github.com/FireRedTeam/IVC-Prune.
Complex Locomotion Skill Learning via Differentiable Physics
Jun 06, 2022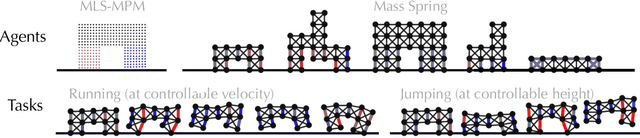



Differentiable physics enables efficient gradient-based optimizations of neural network (NN) controllers. However, existing work typically only delivers NN controllers with limited capability and generalizability. We present a practical learning framework that outputs unified NN controllers capable of tasks with significantly improved complexity and diversity. To systematically improve training robustness and efficiency, we investigated a suite of improvements over the baseline approach, including periodic activation functions, and tailored loss functions. In addition, we find our adoption of batching and an Adam optimizer effective in training complex locomotion tasks. We evaluate our framework on differentiable mass-spring and material point method (MPM) simulations, with challenging locomotion tasks and multiple robot designs. Experiments show that our learning framework, based on differentiable physics, delivers better results than reinforcement learning and converges much faster. We demonstrate that users can interactively control soft robot locomotion and switch among multiple goals with specified velocity, height, and direction instructions using a unified NN controller trained in our system.