 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Decision-Making Under Uncertainty through Bi-Level Game Theory and Distributionally Robust Optimization
Nov 07, 2025In strategic scenarios where decision-makers operate at different hierarchical levels, traditional optimization methods are often inadequate for handling uncertainties from incomplete information or unpredictable external factors. To fill this gap, we introduce a mathematical framework that integrates bi-level game theory with distributionally robust optimization (DRO), particularly suited for complex network systems. Our approach leverages the hierarchical structure of bi-level games to model leader-follower interactions while incorporating distributional robustness to guard against worst-case probability distributions. To ensure computational tractability, the Karush-Kuhn-Tucker (KKT) conditions are used to transform the bi-level challenge into a more manageable single-level model, and the infinite-dimensional DRO problem is reformulated into a finite equivalent. We propose a generalized algorithm to solve this integrated model. Simulation results validate our framework's efficacy, demonstrating that under high uncertainty, the proposed model achieves up to a 22\% cost reduction compared to traditional stochastic methods while maintaining a service level of over 90\%. This highlights its potential to significantly improve decision quality and robustness in networked systems such as transportation and communication networks.
Clustering Enabled Few-Shot Load Forecasting
Feb 16, 2022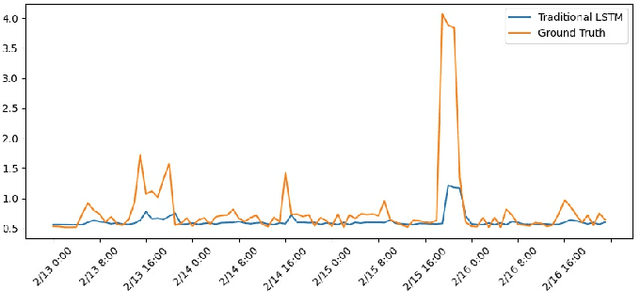
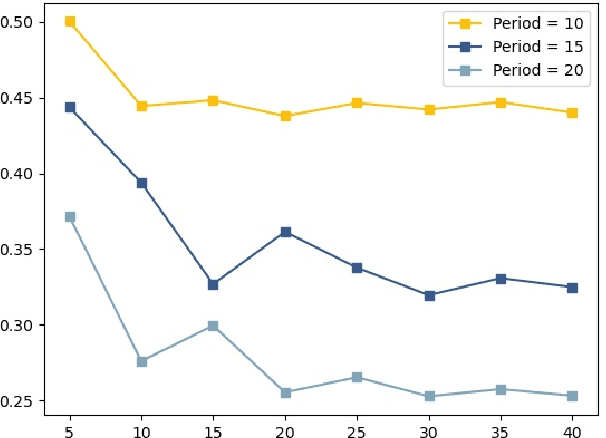
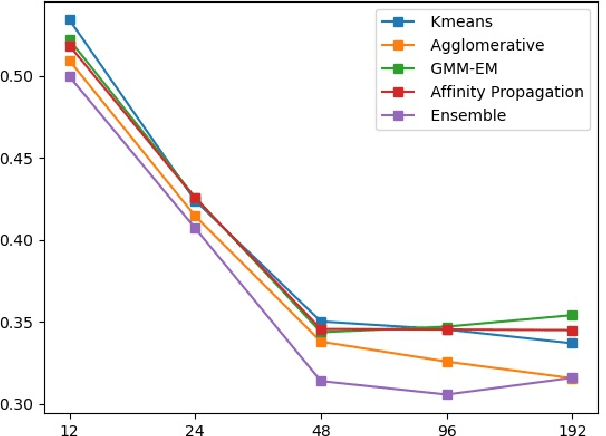
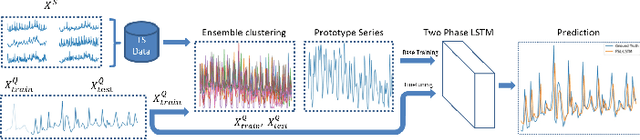
While the advanced machine learning algorithms are effective in load forecasting, they often suffer from low data utilization, and hence their superior performance relies on massive datasets. This motivates us to design machine learning algorithms with improved data utilization. Specifically, we consider the load forecasting for a new user in the system by observing only few shots (data points) of its energy consumption. This task is challenging since the limited samples are insufficient to exploit the temporal characteristics, essential for load forecasting. Nonetheless, we notice that there are not too many temporal characteristics for residential loads due to the limited kinds of human lifestyle. Hence, we propose to utilize the historical load profile data from existing users to conduct effective clustering, which mitigates the challenges brought by the limited samples. Specifically, we first design a feature extraction clustering method for categorizing historical data. Then, inheriting the prior knowledge from the clustering results, we propose a two-phase Long Short Term Memory (LSTM) model to conduct load forecasting for new users. The proposed method outperforms the traditional LSTM model, especially when the training sample size fails to cover a whole period (i.e., 24 hours in our task). Extensive case studies on two real-world datasets and one synthetic dataset verify the effectiveness and efficiency of our method.
Privacy Preserving in Non-Intrusive Load Monitoring: A Differential Privacy Perspective
Nov 12, 2020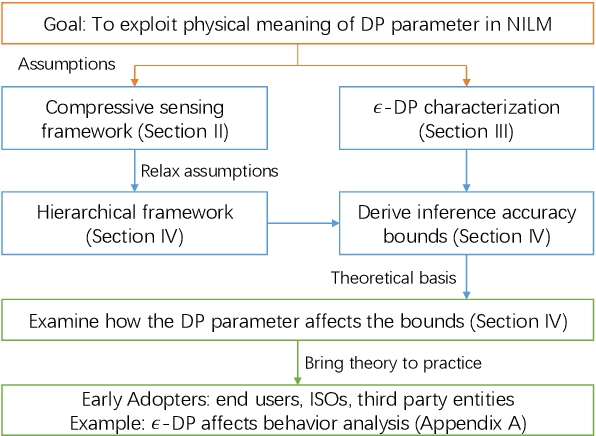
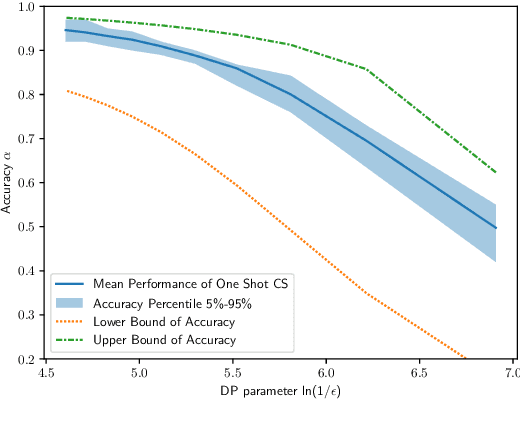
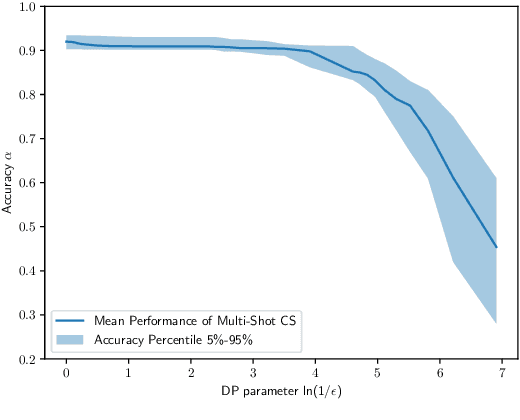
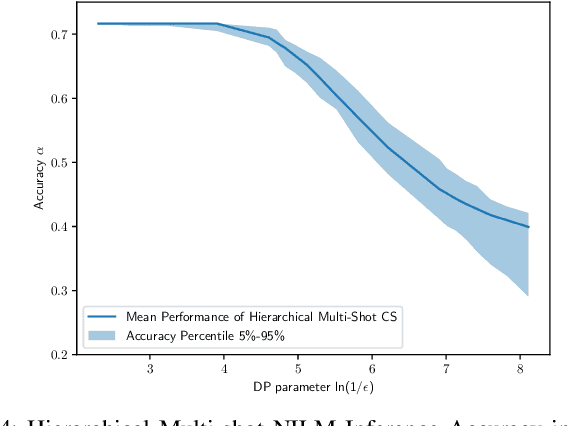
Smart meter devices enable a better understanding of the demand at the potential risk of private information leakage. One promising solution to mitigating such risk is to inject noises into the meter data to achieve a certain level of differential privacy. In this paper, we cast one-shot non-intrusive load monitoring (NILM) in the compressive sensing framework, and bridge the gap between theoretical accuracy of NILM inference and differential privacy's parameters. We then derive the valid theoretical bounds to offer insights on how the differential privacy parameters affect the NILM performance. Moreover, we generalize our conclusions by proposing the hierarchical framework to solve the multi-shot NILM problem. Numerical experiments verify our analytical results and offer better physical insights of differential privacy in various practical scenarios. This also demonstrates the significance of our work for the general privacy preserving mechanism design.
Effective End-to-End Learning Framework for Economic Dispatch
Feb 22, 2020
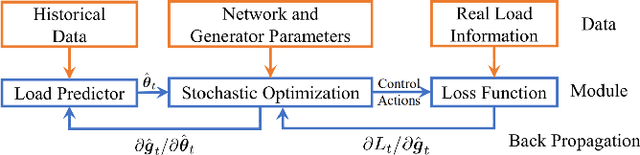
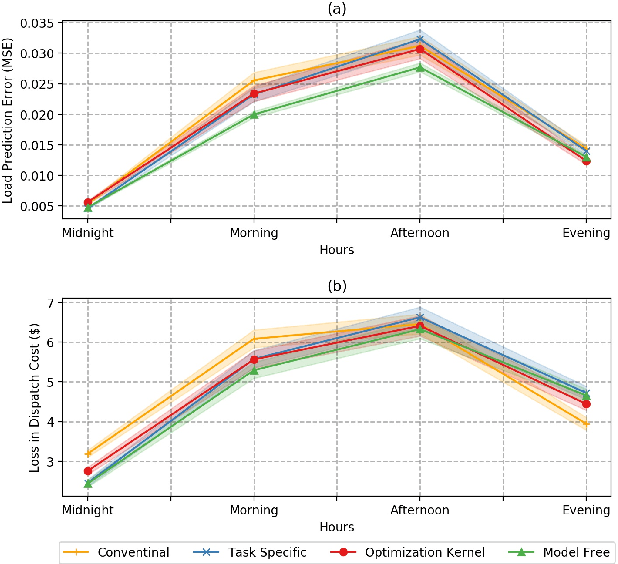
Conventional wisdom to improve the effectiveness of economic dispatch is to design the load forecasting method as accurately as possible. However, this approach can be problematic due to the temporal and spatial correlations between system cost and load prediction errors. This motivates us to adopt the notion of end-to-end machine learning and to propose a task-specific learning criteria to conduct economic dispatch. Specifically, to maximize the data utilization, we design an efficient optimization kernel for the learning process. We provide both theoretical analysis and empirical insights to highlight the effectiveness and efficiency of the proposed learning framework.
Robust Data-driven Profile-based Pricing Schemes
Dec 12, 2019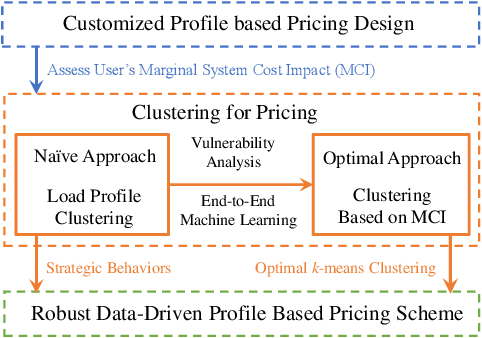
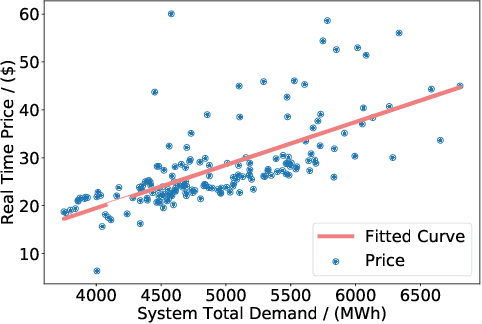
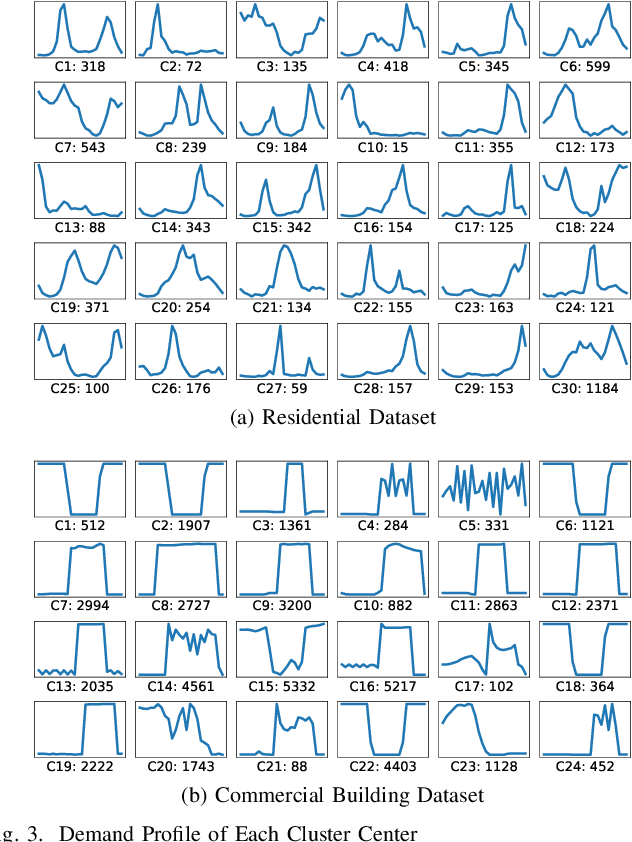
To enable an efficient electricity market, a good pricing scheme is of vital importance. Among many practical schemes, customized pricing is commonly believed to be able to best exploit the flexibility in the demand side. However, due to the large volume of consumers in the electricity sector, such task is simply too overwhelming. In this paper, we first compare two data driven schemes: one based on load profile and the other based on user's marginal system cost. Vulnerability analysis shows that the former approach may lead to loopholes in the electricity market while the latter one is able to guarantee the robustness, which yields our robust data-driven pricing scheme. Although k-means clustering is in general NP-hard, surprisingly, by exploiting the structure of our problem, we design an efficient yet optimal k-means clustering algorithm to implement our proposed scheme.
A Data-driven Storage Control Framework for Dynamic Pricing
Dec 01, 2019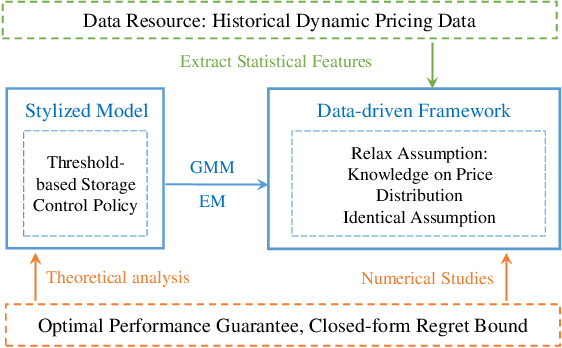
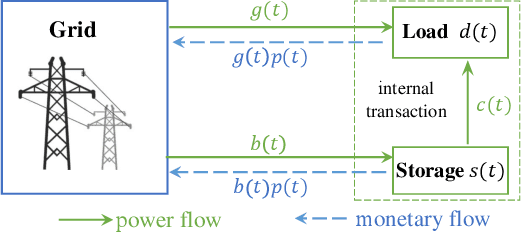
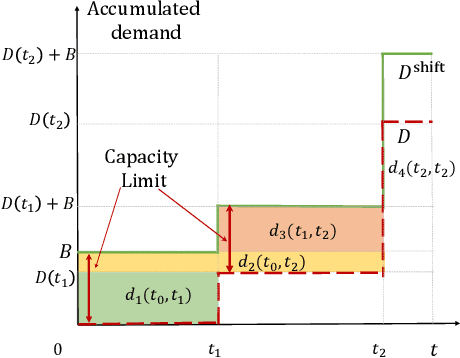
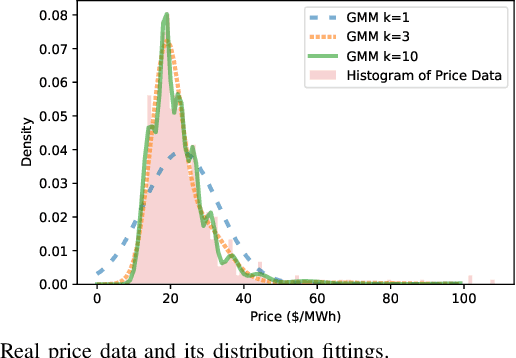
Dynamic pricing is both an opportunity and a challenge to the demand side. It is an opportunity as it better reflects the real time market conditions and hence enables an active demand side. However, demand's active participation does not necessarily lead to benefits. The challenge conventionally comes from the limited flexible resources and limited intelligent devices in demand side. The decreasing cost of storage system and the widely deployed smart meters inspire us to design a data-driven storage control framework for dynamic prices. We first establish a stylized model by assuming the knowledge and structure of dynamic price distributions, and design the optimal storage control policy. Based on Gaussian Mixture Model, we propose a practical data-driven control framework, which helps relax the assumptions in the stylized model. Numerical studies illustrate the remarkable performance of the proposed data-driven framework.
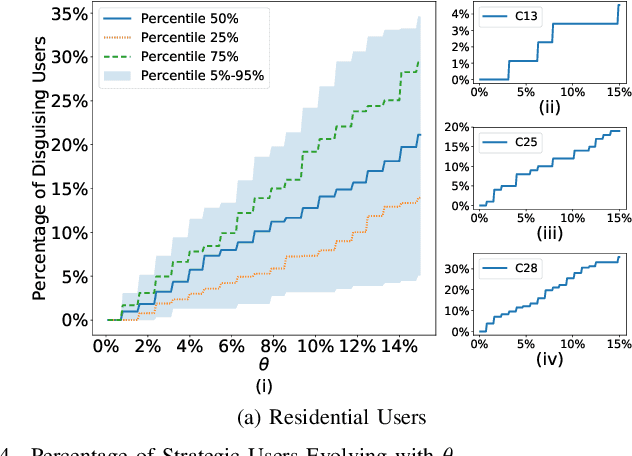
Vulnerability Analysis for Data Driven Pricing Schemes
Nov 18, 2019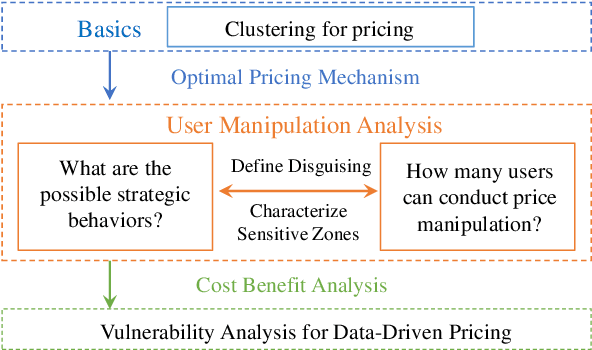
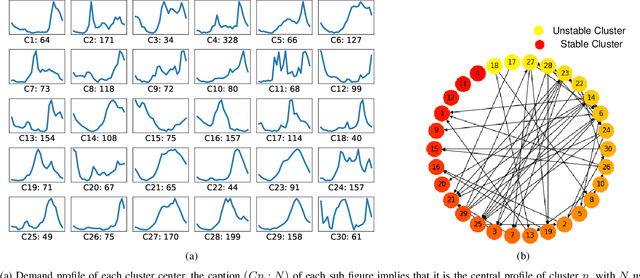
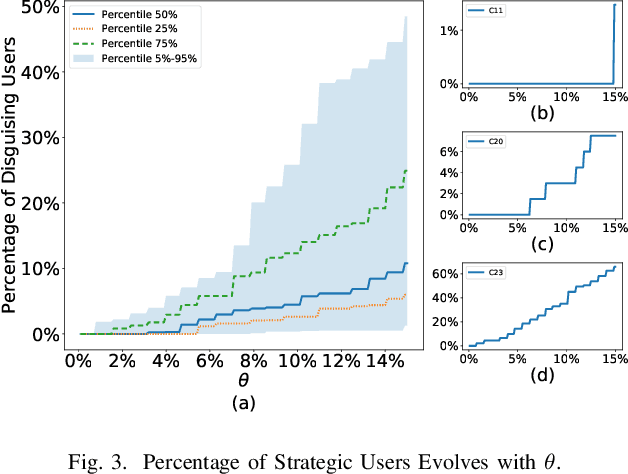
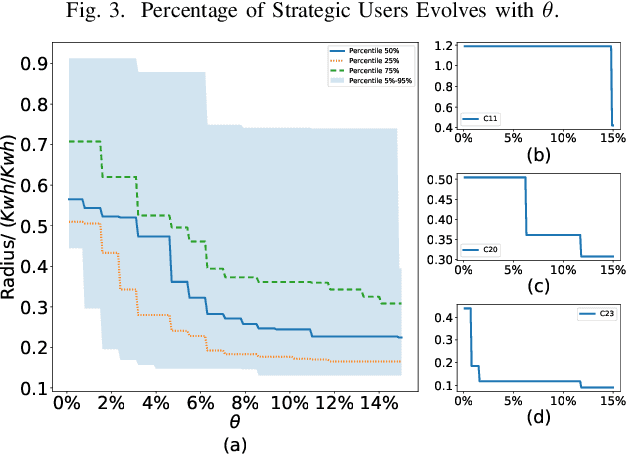
Data analytics and machine learning techniques are being rapidly adopted into the power system, including power system control as well as electricity market design. In this paper, from an adversarial machine learning point of view, we examine the vulnerability of data-driven electricity market design. More precisely, we follow the idea that consumer's load profile should uniquely determine its electricity rate, which yields a clustering oriented pricing scheme. We first identify the strategic behaviors of malicious users by defining a notion of disguising. Based on this notion, we characterize the sensitivity zones to evaluate the percentage of malicious users in each cluster. Based on a thorough cost benefit analysis, we conclude with the vulnerability analysis.
Conductor Galloping Prediction on Imbalanced Datasets: SVM with Smart Sampling
Nov 09, 2019
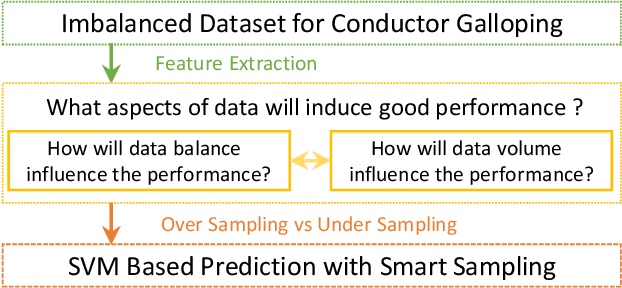
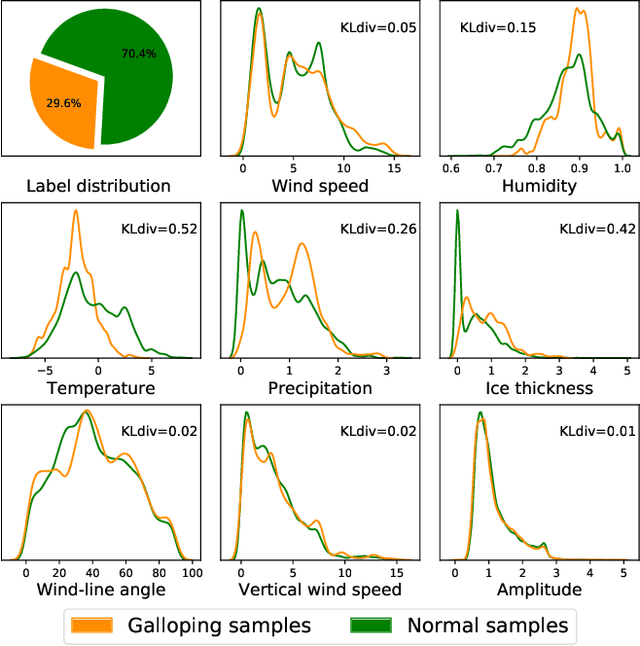
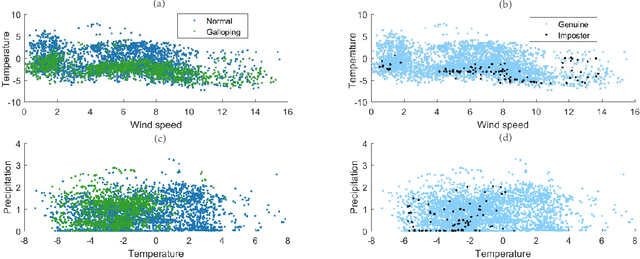
Conductor galloping is the high-amplitude, low-frequency oscillation of overhead power lines due to wind. Such movements may lead to severe damages to transmission lines, and hence pose significant risks to the power system operation. In this paper, we target to design a prediction framework for conductor galloping. The difficulty comes from imbalanced dataset as galloping happens rarely. By examining the impacts of data balance and data volume on the prediction performance, we propose to employ proper sample adjustment methods to achieve better performance. Numerical study suggests that using only three features, together with over sampling, the SVM based prediction framework achieves an F_1-score of 98.9%.