 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective End-to-End Learning Framework for Economic Dispatch
Feb 22, 2020
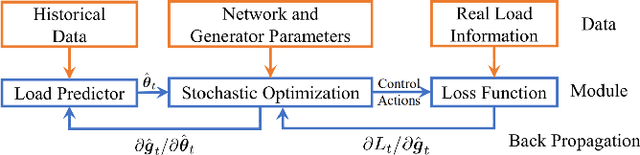
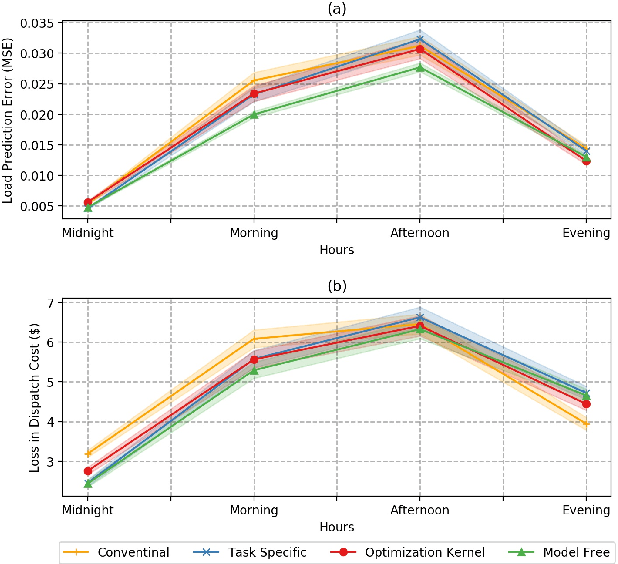
Conventional wisdom to improve the effectiveness of economic dispatch is to design the load forecasting method as accurately as possible. However, this approach can be problematic due to the temporal and spatial correlations between system cost and load prediction errors. This motivates us to adopt the notion of end-to-end machine learning and to propose a task-specific learning criteria to conduct economic dispatch. Specifically, to maximize the data utilization, we design an efficient optimization kernel for the learning process. We provide both theoretical analysis and empirical insights to highlight the effectiveness and efficiency of the proposed learning framework.
A Data-driven Storage Control Framework for Dynamic Pricing
Dec 01, 2019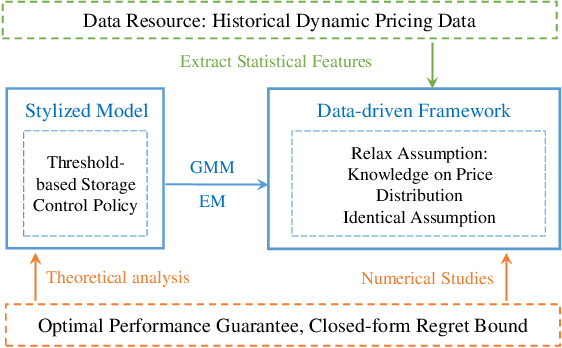
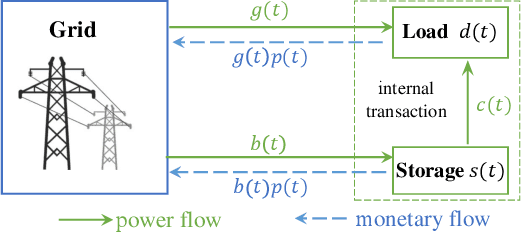
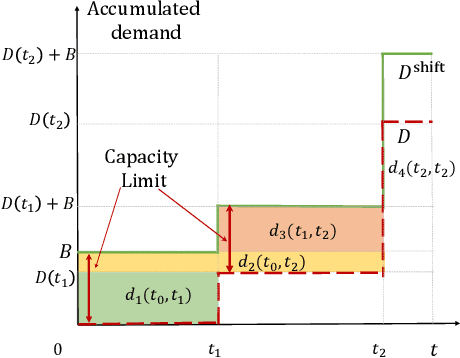
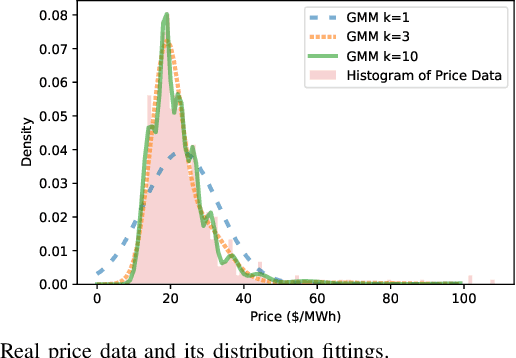
Dynamic pricing is both an opportunity and a challenge to the demand side. It is an opportunity as it better reflects the real time market conditions and hence enables an active demand side. However, demand's active participation does not necessarily lead to benefits. The challenge conventionally comes from the limited flexible resources and limited intelligent devices in demand side. The decreasing cost of storage system and the widely deployed smart meters inspire us to design a data-driven storage control framework for dynamic prices. We first establish a stylized model by assuming the knowledge and structure of dynamic price distributions, and design the optimal storage control policy. Based on Gaussian Mixture Model, we propose a practical data-driven control framework, which helps relax the assumptions in the stylized model. Numerical studies illustrate the remarkable performance of the proposed data-driven framework.
Conductor Galloping Prediction on Imbalanced Datasets: SVM with Smart Sampling
Nov 09, 2019
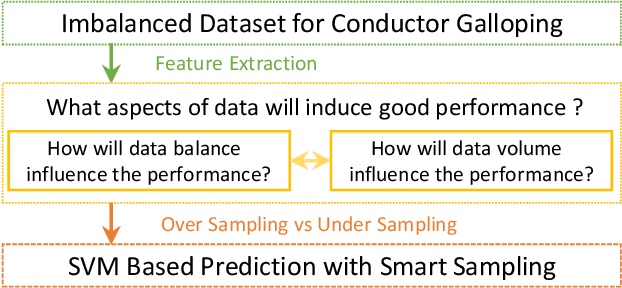
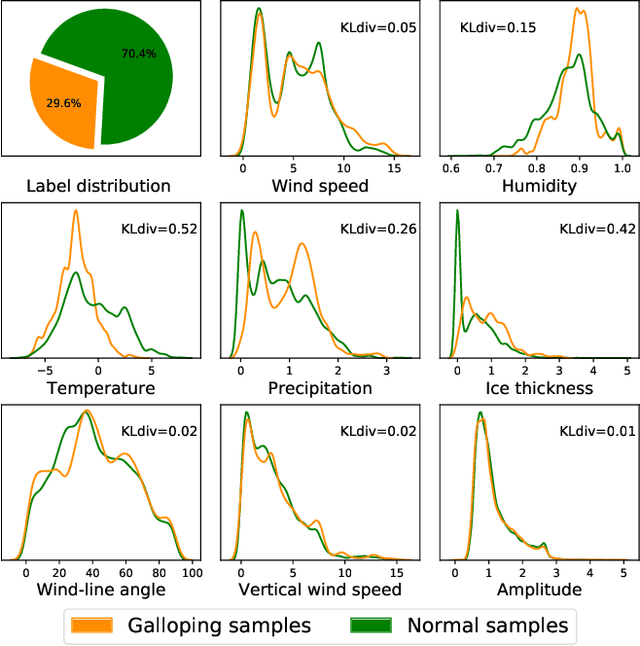
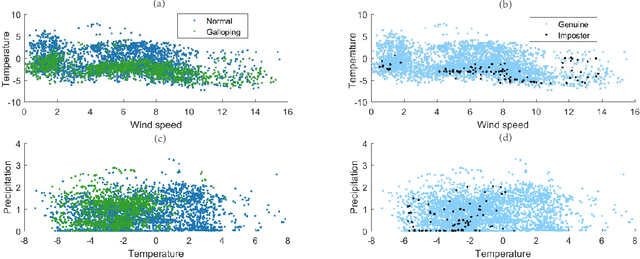
Conductor galloping is the high-amplitude, low-frequency oscillation of overhead power lines due to wind. Such movements may lead to severe damages to transmission lines, and hence pose significant risks to the power system operation. In this paper, we target to design a prediction framework for conductor galloping. The difficulty comes from imbalanced dataset as galloping happens rarely. By examining the impacts of data balance and data volume on the prediction performance, we propose to employ proper sample adjustment methods to achieve better performance. Numerical study suggests that using only three features, together with over sampling, the SVM based prediction framework achieves an F_1-score of 98.9%.
Joint Modeling and Registration of Cell Populations in Cohorts of High-Dimensional Flow Cytometric Data
May 31, 2013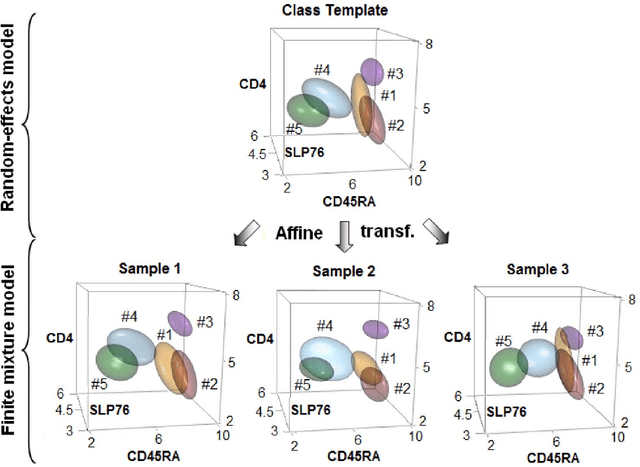
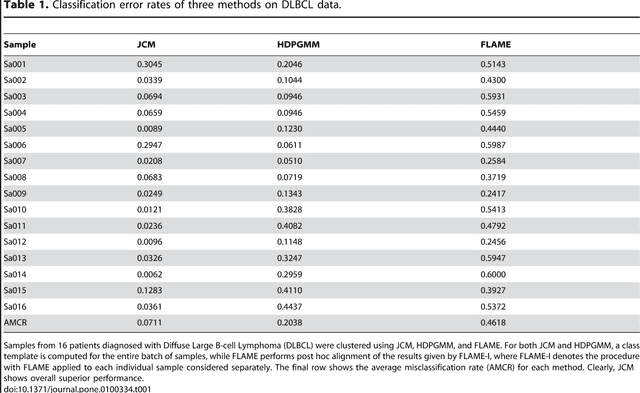
In systems biomedicine, an experimenter encounters different potential sources of variation in data such as individual samples, multiple experimental conditions, and multi-variable network-level responses. In multiparametric cytometry, which is often used for analyzing patient samples, such issues are critical. While computational methods can identify cell populations in individual samples, without the ability to automatically match them across samples, it is difficult to compare and characterize the populations in typical experiments, such as those responding to various stimulations or distinctive of particular patients or time-points, especially when there are many samples. Joint Clustering and Matching (JCM) is a multi-level framework for simultaneous modeling and registration of populations across a cohort. JCM models every population with a robust multivariate probability distribution. Simultaneously, JCM fits a random-effects model to construct an overall batch template -- used for registering populations across samples, and classifying new samples. By tackling systems-level variation, JCM supports practical biomedical applications involving large cohorts.