 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation
May 15, 2024



The systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction. Project website: https://behavior-vision-suite.github.io/
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024



We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
Language-Informed Visual Concept Learning
Dec 06, 2023Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
NOIR: Neural Signal Operated Intelligent Robots for Everyday Activities
Nov 02, 2023



We present Neural Signal Operated Intelligent Robots (NOIR), a general-purpose, intelligent brain-robot interface system that enables humans to command robots to perform everyday activities through brain signals. Through this interface, humans communicate their intended objects of interest and actions to the robots using electroencephalography (EEG). Our novel system demonstrates success in an expansive array of 20 challenging, everyday household activities, including cooking, cleaning, personal care, and entertainment. The effectiveness of the system is improved by its synergistic integration of robot learning algorithms, allowing for NOIR to adapt to individual users and predict their intentions. Our work enhances the way humans interact with robots, replacing traditional channels of interaction with direct, neural communication. Project website: https://noir-corl.github.io/.
Primitive Skill-based Robot Learning from Human Evaluative Feedback
Aug 02, 2023Reinforcement learning (RL) algorithms face significant challenges when dealing with long-horizon robot manipulation tasks in real-world environments due to sample inefficiency and safety issues. To overcome these challenges, we propose a novel framework, SEED, which leverages two approaches: reinforcement learning from human feedback (RLHF) and primitive skill-based reinforcement learning. Both approaches are particularly effective in addressing sparse reward issues and the complexities involved in long-horizon tasks. By combining them, SEED reduces the human effort required in RLHF and increases safety in training robot manipulation with RL in real-world settings. Additionally, parameterized skills provide a clear view of the agent's high-level intentions, allowing humans to evaluate skill choices before they are executed. This feature makes the training process even safer and more efficient. To evaluate the performance of SEED, we conducted extensive experiments on five manipulation tasks with varying levels of complexity. Our results show that SEED significantly outperforms state-of-the-art RL algorithms in sample efficiency and safety. In addition, SEED also exhibits a substantial reduction of human effort compared to other RLHF methods. Further details and video results can be found at https://seediros23.github.io/.
Joint Modeling and Registration of Cell Populations in Cohorts of High-Dimensional Flow Cytometric Data
May 31, 2013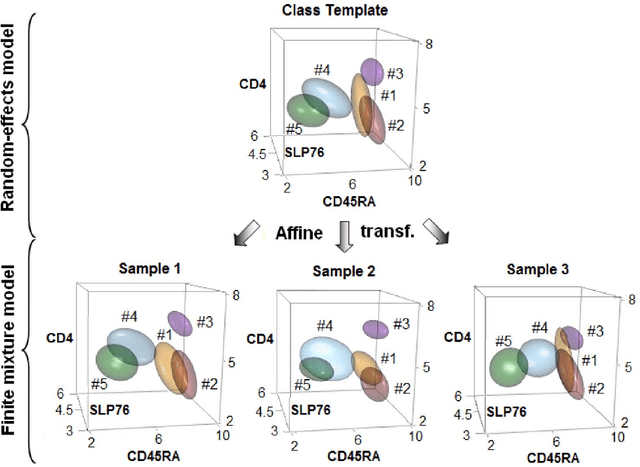
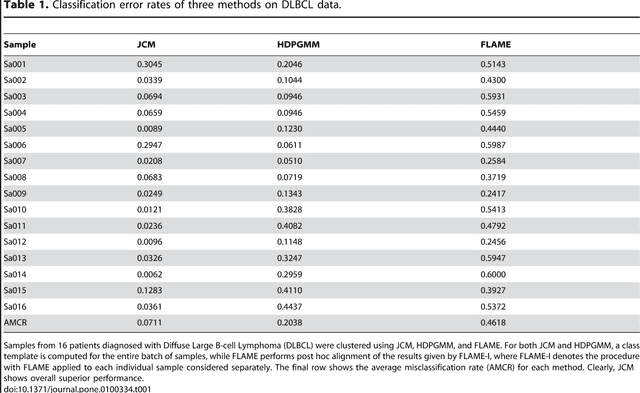
In systems biomedicine, an experimenter encounters different potential sources of variation in data such as individual samples, multiple experimental conditions, and multi-variable network-level responses. In multiparametric cytometry, which is often used for analyzing patient samples, such issues are critical. While computational methods can identify cell populations in individual samples, without the ability to automatically match them across samples, it is difficult to compare and characterize the populations in typical experiments, such as those responding to various stimulations or distinctive of particular patients or time-points, especially when there are many samples. Joint Clustering and Matching (JCM) is a multi-level framework for simultaneous modeling and registration of populations across a cohort. JCM models every population with a robust multivariate probability distribution. Simultaneously, JCM fits a random-effects model to construct an overall batch template -- used for registering populations across samples, and classifying new samples. By tackling systems-level variation, JCM supports practical biomedical applications involving large cohorts.