 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Modern Large Language Models on Low-Resource and Morphologically Rich Languages:A Cross-Lingual Benchmark Across Cantonese, Japanese, and Turkish
Nov 05, 2025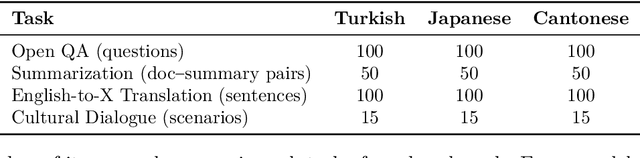
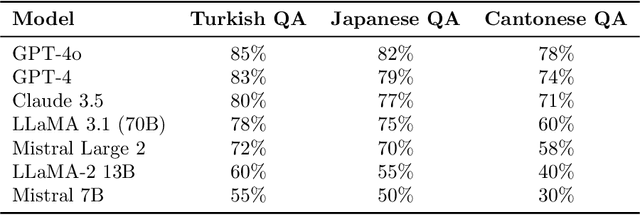
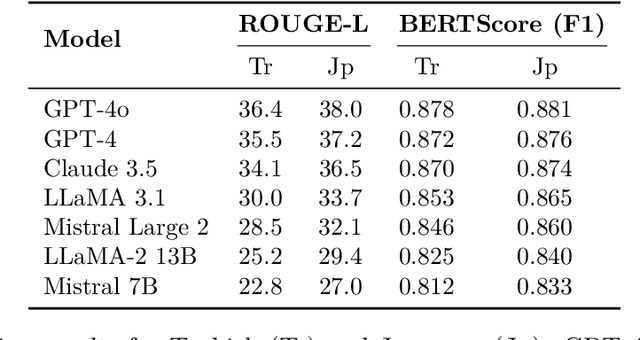
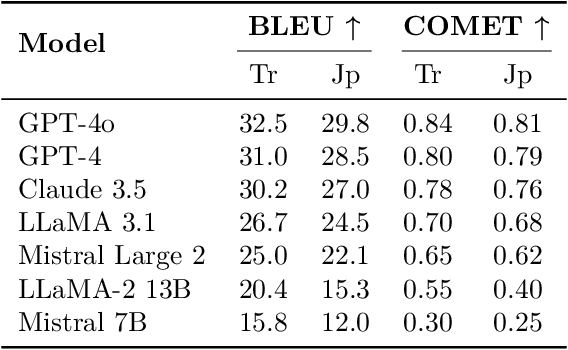
Large language models (LLMs) have achieved impressive results in high-resource languages like English, yet their effectiveness in low-resource and morphologically rich languages remains underexplored. In this paper, we present a comprehensive evaluation of seven cutting-edge LLMs -- including GPT-4o, GPT-4, Claude~3.5~Sonnet, LLaMA~3.1, Mistral~Large~2, LLaMA-2~Chat~13B, and Mistral~7B~Instruct -- on a new cross-lingual benchmark covering \textbf{Cantonese, Japanese, and Turkish}. Our benchmark spans four diverse tasks: open-domain question answering, document summarization, English-to-X translation, and culturally grounded dialogue. We combine \textbf{human evaluations} (rating fluency, factual accuracy, and cultural appropriateness) with automated metrics (e.g., BLEU, ROUGE) to assess model performance. Our results reveal that while the largest proprietary models (GPT-4o, GPT-4, Claude~3.5) generally lead across languages and tasks, significant gaps persist in culturally nuanced understanding and morphological generalization. Notably, GPT-4o demonstrates robust multilingual performance even on cross-lingual tasks, and Claude~3.5~Sonnet achieves competitive accuracy on knowledge and reasoning benchmarks. However, all models struggle to some extent with the unique linguistic challenges of each language, such as Turkish agglutinative morphology and Cantonese colloquialisms. Smaller open-source models (LLaMA-2~13B, Mistral~7B) lag substantially in fluency and accuracy, highlighting the resource disparity. We provide detailed quantitative results, qualitative error analysis, and discuss implications for developing more culturally aware and linguistically generalizable LLMs. Our benchmark and evaluation data are released to foster reproducibility and further research.
Parallelism Meets Adaptiveness: Scalable Documents Understanding in Multi-Agent LLM Systems
Jul 22, 2025Large language model (LLM) agents have shown increasing promise for collaborative task completion. However, existing multi-agent frameworks often rely on static workflows, fixed roles, and limited inter-agent communication, reducing their effectiveness in open-ended, high-complexity domains. This paper proposes a coordination framework that enables adaptiveness through three core mechanisms: dynamic task routing, bidirectional feedback, and parallel agent evaluation. The framework allows agents to reallocate tasks based on confidence and workload, exchange structured critiques to iteratively improve outputs, and crucially compete on high-ambiguity subtasks with evaluator-driven selection of the most suitable result. We instantiate these principles in a modular architecture and demonstrate substantial improvements in factual coverage, coherence, and efficiency over static and partially adaptive baselines. Our findings highlight the benefits of incorporating both adaptiveness and structured competition in multi-agent LLM systems.
R1-Code-Interpreter: Training LLMs to Reason with Code via Supervised and Reinforcement Learning
May 27, 2025



Despite advances in reasoning and planning of R1-like models, Large Language Models (LLMs) still struggle with tasks requiring precise computation, symbolic manipulation, optimization, and algorithmic reasoning, in which textual reasoning lacks the rigor of code execution. A key challenge is enabling LLMs to decide when to use textual reasoning versus code generation. While OpenAI trains models to invoke a Code Interpreter as needed, public research lacks guidance on aligning pre-trained LLMs to effectively leverage code and generalize across diverse tasks. We present R1-Code-Interpreter, an extension of a text-only LLM trained via multi-turn supervised fine-tuning (SFT) and reinforcement learning (RL) to autonomously generate multiple code queries during step-by-step reasoning. We curate 144 reasoning and planning tasks (107 for training, 37 for testing), each with over 200 diverse questions. We fine-tune Qwen-2.5 models (3B/7B/14B) using various SFT and RL strategies, investigating different answer formats, reasoning vs. non-reasoning models, cold vs. warm starts, GRPO vs. PPO, and masked vs. unmasked code outputs. Unlike prior RL work on narrow domains, we find that Code Interpreter training is significantly harder due to high task diversity and expensive code execution, highlighting the critical role of the SFT stage. Our final model, R1-CI-14B, improves average accuracy on the 37 test tasks from 44.0\% to 64.1\%, outperforming GPT-4o (text-only: 58.6\%) and approaching GPT-4o with Code Interpreter (70.9\%), with the emergent self-checking behavior via code generation. Datasets, Codes, and Models are available at https://github.com/yongchao98/R1-Code-Interpreter and https://huggingface.co/yongchao98.
Code-as-Symbolic-Planner: Foundation Model-Based Robot Planning via Symbolic Code Generation
Mar 03, 2025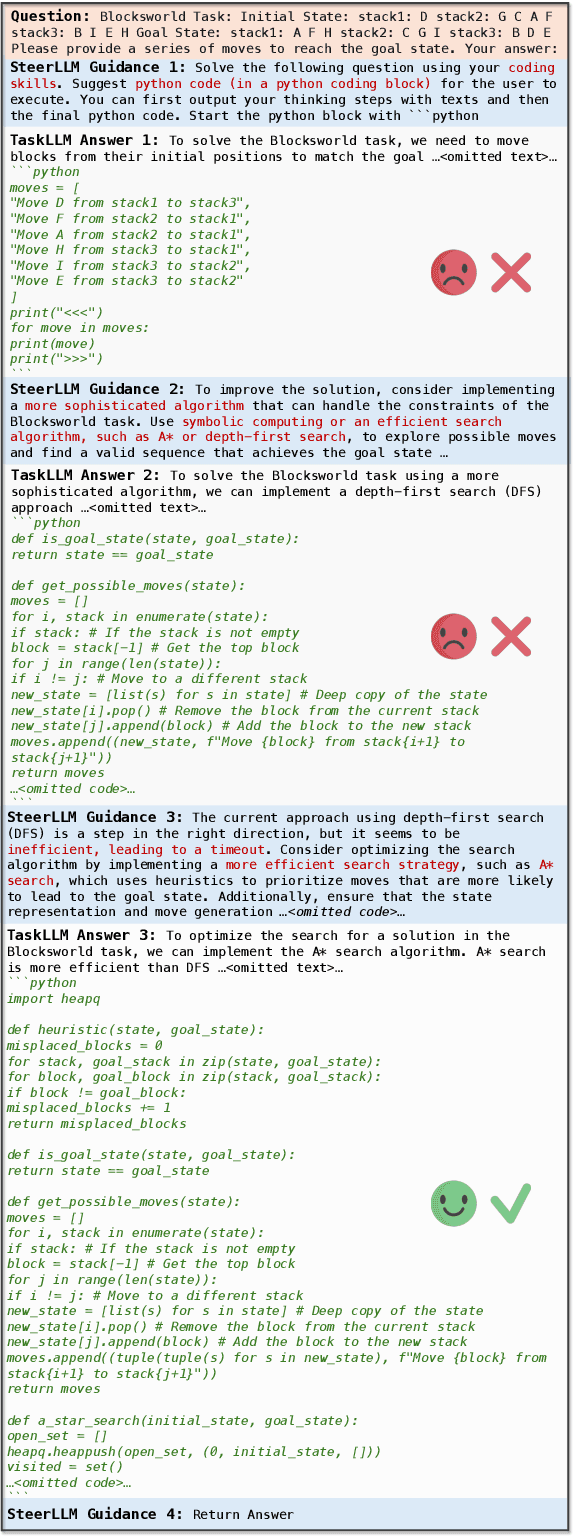
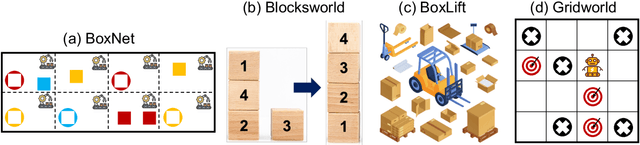
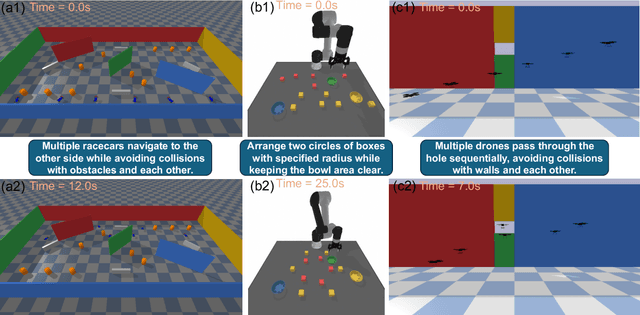
Recent works have shown great potentials of Large Language Models (LLMs) in robot task and motion planning (TAMP). Current LLM approaches generate text- or code-based reasoning chains with sub-goals and action plans. However, they do not fully leverage LLMs' symbolic computing and code generation capabilities. Many robot TAMP tasks involve complex optimization under multiple constraints, where pure textual reasoning is insufficient. While augmenting LLMs with predefined solvers and planners improves performance, it lacks generalization across tasks. Given LLMs' growing coding proficiency, we enhance their TAMP capabilities by steering them to generate code as symbolic planners for optimization and constraint verification. Unlike prior work that uses code to interface with robot action modules, we steer LLMs to generate code as solvers, planners, and checkers for TAMP tasks requiring symbolic computing, while still leveraging textual reasoning to incorporate common sense. With a multi-round guidance and answer evolution framework, the proposed Code-as-Symbolic-Planner improves success rates by average 24.1\% over best baseline methods across seven typical TAMP tasks and three popular LLMs. Code-as-Symbolic-Planner shows strong effectiveness and generalizability across discrete and continuous environments, 2D/3D simulations and real-world settings, as well as single- and multi-robot tasks with diverse requirements. See our project website https://yongchao98.github.io/Code-Symbol-Planner/ for prompts, videos, and code.
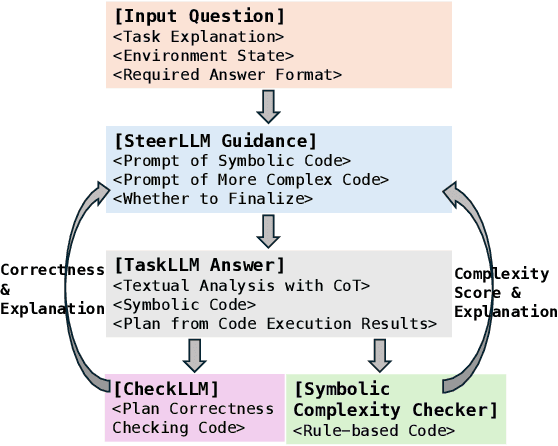
CodeSteer: Symbolic-Augmented Language Models via Code/Text Guidance
Feb 04, 2025
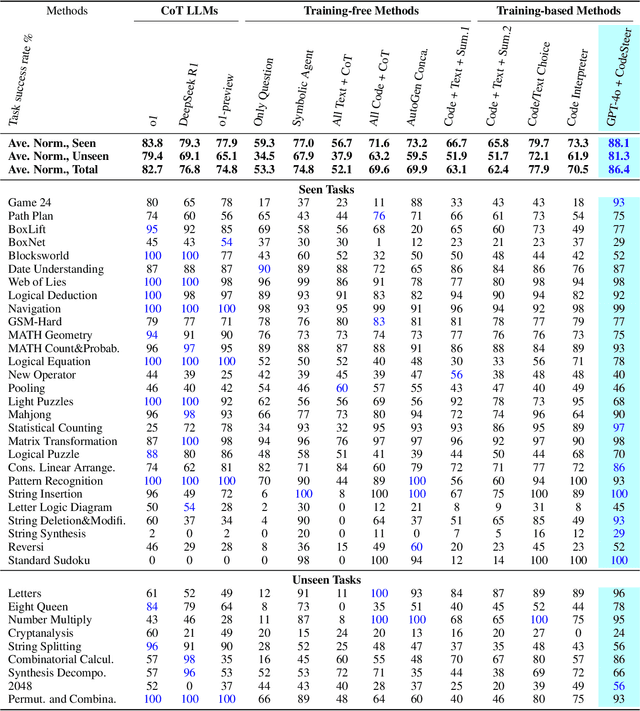
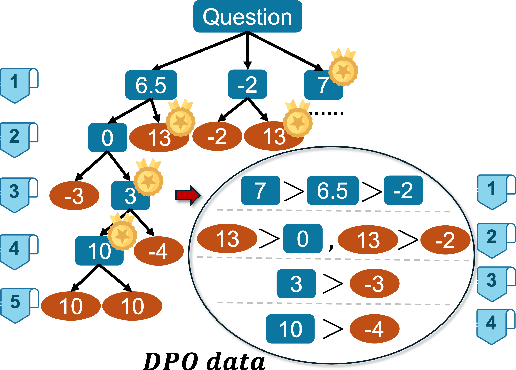

Existing methods fail to effectively steer Large Language Models (LLMs) between textual reasoning and code generation, leaving symbolic computing capabilities underutilized. We introduce CodeSteer, an effective method for guiding LLM code/text generation. We construct a comprehensive benchmark SymBench comprising 37 symbolic tasks with adjustable complexity and also synthesize datasets of 12k multi-round guidance/generation trajectories and 5.5k guidance comparison pairs. We fine-tune the Llama-3-8B model with a newly designed multi-round supervised fine-tuning (SFT) and direct preference optimization (DPO). The resulting model, CodeSteerLLM, augmented with the proposed symbolic and self-answer checkers, effectively guides the code/text generation of larger models. Augmenting GPT-4o with CodeSteer raises its average performance score from 53.3 to 86.4, even outperforming the existing best LLM OpenAI o1 (82.7), o1-preview (74.8), and DeepSeek R1 (76.8) across all 37 tasks (28 seen, 9 unseen). Trained for GPT-4o, CodeSteer demonstrates superior generalizability, providing an average 41.8 performance boost on Claude, Mistral, and GPT-3.5. CodeSteer-guided LLMs fully harness symbolic computing to maintain strong performance on highly complex tasks. Models, Datasets, and Codes are available at https://github.com/yongchao98/CodeSteer-v1.0.
Planning Anything with Rigor: General-Purpose Zero-Shot Planning with LLM-based Formalized Programming
Oct 15, 2024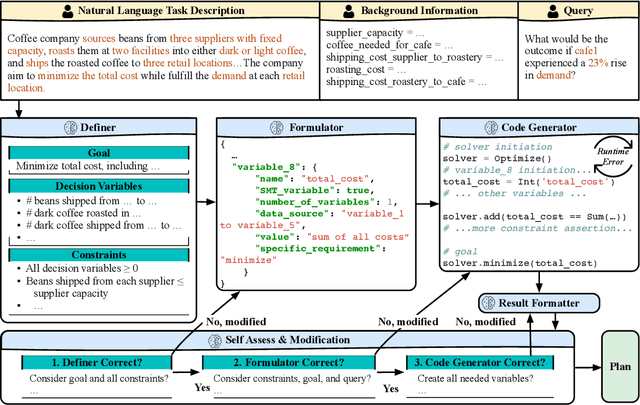
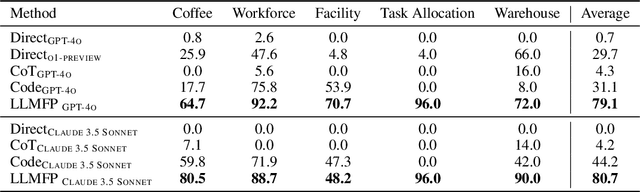

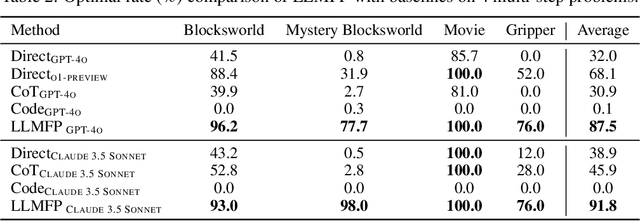
While large language models (LLMs) have recently demonstrated strong potential in solving planning problems, there is a trade-off between flexibility and complexity. LLMs, as zero-shot planners themselves, are still not capable of directly generating valid plans for complex planning problems such as multi-constraint or long-horizon tasks. On the other hand, many frameworks aiming to solve complex planning problems often rely on task-specific preparatory efforts, such as task-specific in-context examples and pre-defined critics/verifiers, which limits their cross-task generalization capability. In this paper, we tackle these challenges by observing that the core of many planning problems lies in optimization problems: searching for the optimal solution (best plan) with goals subject to constraints (preconditions and effects of decisions). With LLMs' commonsense, reasoning, and programming capabilities, this opens up the possibilities of a universal LLM-based approach to planning problems. Inspired by this observation, we propose LLMFP, a general-purpose framework that leverages LLMs to capture key information from planning problems and formally formulate and solve them as optimization problems from scratch, with no task-specific examples needed. We apply LLMFP to 9 planning problems, ranging from multi-constraint decision making to multi-step planning problems, and demonstrate that LLMFP achieves on average 83.7% and 86.8% optimal rate across 9 tasks for GPT-4o and Claude 3.5 Sonnet, significantly outperforming the best baseline (direct planning with OpenAI o1-preview) with 37.6% and 40.7% improvements. We also validate components of LLMFP with ablation experiments and analyzed the underlying success and failure reasons.
Large Language Models Can Plan Your Travels Rigorously with Formal Verification Tools
Apr 18, 2024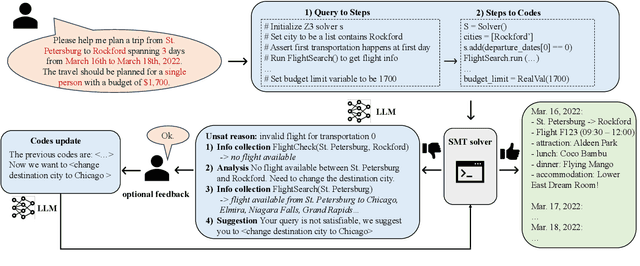
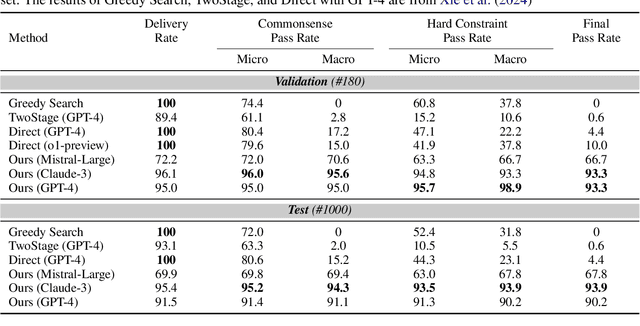

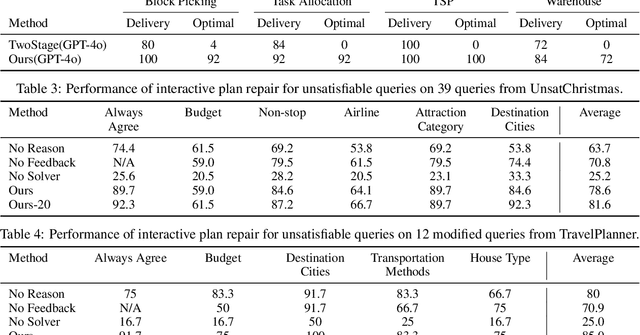
The recent advancements of Large Language Models (LLMs), with their abundant world knowledge and capabilities of tool-using and reasoning, fostered many LLM planning algorithms. However, LLMs have not shown to be able to accurately solve complex combinatorial optimization problems. In Xie et al. (2024), the authors proposed TravelPlanner, a U.S. domestic travel planning benchmark, and showed that LLMs themselves cannot make travel plans that satisfy user requirements with a best success rate of 0.6%. In this work, we propose a framework that enables LLMs to formally formulate and solve the travel planning problem as a satisfiability modulo theory (SMT) problem and use SMT solvers interactively and automatically solve the combinatorial search problem. The SMT solvers guarantee the satisfiable of input constraints and the LLMs can enable a language-based interaction with our framework. When the input constraints cannot be satisfiable, our LLM-based framework will interactively offer suggestions to users to modify their travel requirements via automatic reasoning using the SMT solvers. We evaluate our framework with TravelPlanner and achieve a success rate of 97%. We also create a separate dataset that contain international travel benchmarks and use both dataset to evaluate the effectiveness of our interactive planning framework when the initial user queries cannot be satisfied. Our framework could generate valid plans with an average success rate of 78.6% for our dataset and 85.0% for TravelPlanner according to diverse humans preferences.
PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Preference Alignment
Feb 13, 2024



Prompt optimization aims to find the best prompt to a large language model (LLM) for a given task. LLMs have been successfully used to help find and improve prompt candidates for single-step tasks. However, realistic tasks for agents are multi-step and introduce new challenges: (1) Prompt content is likely to be more extensive and complex, making it more difficult for LLMs to analyze errors, (2) the impact of an individual step is difficult to evaluate, and (3) different people may have varied preferences about task execution. While humans struggle to optimize prompts, they are good at providing feedback about LLM outputs; we therefore introduce a new LLM-driven discrete prompt optimization framework that incorporates human-designed feedback rules about potential errors to automatically offer direct suggestions for improvement. Our framework is stylized as a genetic algorithm in which an LLM generates new candidate prompts from a parent prompt and its associated feedback; we use a learned heuristic function that predicts prompt performance to efficiently sample from these candidates. This approach significantly outperforms both human-engineered prompts and several other prompt optimization methods across eight representative multi-step tasks (an average 27.7% and 28.2% improvement to current best methods on GPT-3.5 and GPT-4, respectively). We further show that the score function for tasks can be modified to better align with individual preferences. We believe our work can serve as a benchmark for automatic prompt optimization for LLM-driven multi-step tasks. Datasets and Codes are available at https://github.com/yongchao98/PROMST. Project Page is available at https://yongchao98.github.io/MIT-REALM-PROMST.
NOIR: Neural Signal Operated Intelligent Robots for Everyday Activities
Nov 02, 2023



We present Neural Signal Operated Intelligent Robots (NOIR), a general-purpose, intelligent brain-robot interface system that enables humans to command robots to perform everyday activities through brain signals. Through this interface, humans communicate their intended objects of interest and actions to the robots using electroencephalography (EEG). Our novel system demonstrates success in an expansive array of 20 challenging, everyday household activities, including cooking, cleaning, personal care, and entertainment. The effectiveness of the system is improved by its synergistic integration of robot learning algorithms, allowing for NOIR to adapt to individual users and predict their intentions. Our work enhances the way humans interact with robots, replacing traditional channels of interaction with direct, neural communication. Project website: https://noir-corl.github.io/.
Gesture-Informed Robot Assistance via Foundation Models
Sep 07, 2023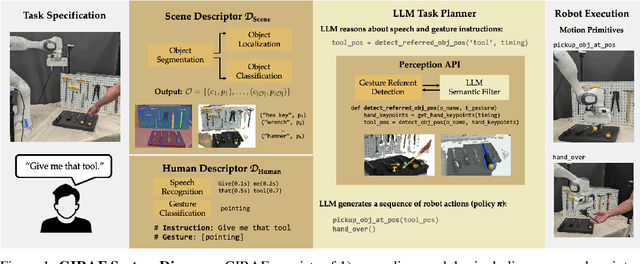

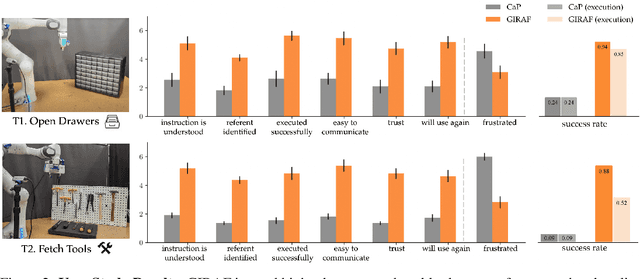
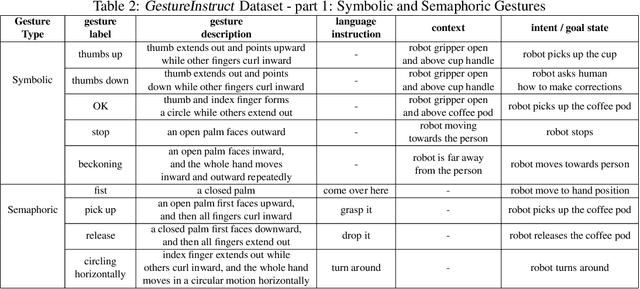
Gestures serve as a fundamental and significant mode of non-verbal communication among humans. Deictic gestures (such as pointing towards an object), in particular, offer valuable means of efficiently expressing intent in situations where language is inaccessible, restricted, or highly specialized. As a result, it is essential for robots to comprehend gestures in order to infer human intentions and establish more effective coordination with them. Prior work often rely on a rigid hand-coded library of gestures along with their meanings. However, interpretation of gestures is often context-dependent, requiring more flexibility and common-sense reasoning. In this work, we propose a framework, GIRAF, for more flexibly interpreting gesture and language instructions by leveraging the power of large language models. Our framework is able to accurately infer human intent and contextualize the meaning of their gestures for more effective human-robot collaboration. We instantiate the framework for interpreting deictic gestures in table-top manipulation tasks and demonstrate that it is both effective and preferred by users, achieving 70% higher success rates than the baseline. We further demonstrate GIRAF's ability on reasoning about diverse types of gestures by curating a GestureInstruct dataset consisting of 36 different task scenarios. GIRAF achieved 81% success rate on finding the correct plan for tasks in GestureInstruct. Website: https://tinyurl.com/giraf23