 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs
Jun 09, 2025In this paper, we introduce a multi-robot system that integrates mapping, localization, and task and motion planning (TAMP) enabled by 3D scene graphs to execute complex instructions expressed in natural language. Our system builds a shared 3D scene graph incorporating an open-set object-based map, which is leveraged for multi-robot 3D scene graph fusion. This representation supports real-time, view-invariant relocalization (via the object-based map) and planning (via the 3D scene graph), allowing a team of robots to reason about their surroundings and execute complex tasks. Additionally, we introduce a planning approach that translates operator intent into Planning Domain Definition Language (PDDL) goals using a Large Language Model (LLM) by leveraging context from the shared 3D scene graph and robot capabilities. We provide an experimental assessment of the performance of our system on real-world tasks in large-scale, outdoor environments.
Large Language Models to the Rescue: Deadlock Resolution in Multi-Robot Systems
Apr 09, 2024



Multi-agent robotic systems are prone to deadlocks in an obstacle environment where the system can get stuck away from its desired location under a smooth low-level control policy. Without an external intervention, often in terms of a high-level command, it is not possible to guarantee that just a low-level control policy can resolve such deadlocks. Utilizing the generalizability and low data requirements of large language models (LLMs), this paper explores the possibility of using LLMs for deadlock resolution. We propose a hierarchical control framework where an LLM resolves deadlocks by assigning a leader and direction for the leader to move along. A graph neural network (GNN) based low-level distributed control policy executes the assigned plan. We systematically study various prompting techniques to improve LLM's performance in resolving deadlocks. In particular, as part of prompt engineering, we provide in-context examples for LLMs. We conducted extensive experiments on various multi-robot environments with up to 15 agents and 40 obstacles. Our results demonstrate that LLM-based high-level planners are effective in resolving deadlocks in MRS.
PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Preference Alignment
Feb 13, 2024



Prompt optimization aims to find the best prompt to a large language model (LLM) for a given task. LLMs have been successfully used to help find and improve prompt candidates for single-step tasks. However, realistic tasks for agents are multi-step and introduce new challenges: (1) Prompt content is likely to be more extensive and complex, making it more difficult for LLMs to analyze errors, (2) the impact of an individual step is difficult to evaluate, and (3) different people may have varied preferences about task execution. While humans struggle to optimize prompts, they are good at providing feedback about LLM outputs; we therefore introduce a new LLM-driven discrete prompt optimization framework that incorporates human-designed feedback rules about potential errors to automatically offer direct suggestions for improvement. Our framework is stylized as a genetic algorithm in which an LLM generates new candidate prompts from a parent prompt and its associated feedback; we use a learned heuristic function that predicts prompt performance to efficiently sample from these candidates. This approach significantly outperforms both human-engineered prompts and several other prompt optimization methods across eight representative multi-step tasks (an average 27.7% and 28.2% improvement to current best methods on GPT-3.5 and GPT-4, respectively). We further show that the score function for tasks can be modified to better align with individual preferences. We believe our work can serve as a benchmark for automatic prompt optimization for LLM-driven multi-step tasks. Datasets and Codes are available at https://github.com/yongchao98/PROMST. Project Page is available at https://yongchao98.github.io/MIT-REALM-PROMST.
Scalable Multi-Robot Collaboration with Large Language Models: Centralized or Decentralized Systems?
Sep 27, 2023



A flurry of recent work has demonstrated that pre-trained large language models (LLMs) can be effective task planners for a variety of single-robot tasks. The planning performance of LLMs is significantly improved via prompting techniques, such as in-context learning or re-prompting with state feedback, placing new importance on the token budget for the context window. An under-explored but natural next direction is to investigate LLMs as multi-robot task planners. However, long-horizon, heterogeneous multi-robot planning introduces new challenges of coordination while also pushing up against the limits of context window length. It is therefore critical to find token-efficient LLM planning frameworks that are also able to reason about the complexities of multi-robot coordination. In this work, we compare the task success rate and token efficiency of four multi-agent communication frameworks (centralized, decentralized, and two hybrid) as applied to four coordination-dependent multi-agent 2D task scenarios for increasing numbers of agents. We find that a hybrid framework achieves better task success rates across all four tasks and scales better to more agents. We further demonstrate the hybrid frameworks in 3D simulations where the vision-to-text problem and dynamical errors are considered. See our project website https://yongchao98.github.io/MIT-REALM-Multi-Robot/ for prompts, videos, and code.
AutoTAMP: Autoregressive Task and Motion Planning with LLMs as Translators and Checkers
Jun 10, 2023



For effective human-robot interaction, robots need to understand, plan, and execute complex, long-horizon tasks described by natural language. The recent and remarkable advances in large language models (LLMs) have shown promise for translating natural language into robot action sequences for complex tasks. However, many existing approaches either translate the natural language directly into robot trajectories, or factor the inference process by decomposing language into task sub-goals, then relying on a motion planner to execute each sub-goal. When complex environmental and temporal constraints are involved, inference over planning tasks must be performed jointly with motion plans using traditional task-and-motion planning (TAMP) algorithms, making such factorization untenable. Rather than using LLMs to directly plan task sub-goals, we instead perform few-shot translation from natural language task descriptions to an intermediary task representation that can then be consumed by a TAMP algorithm to jointly solve the task and motion plan. To improve translation, we automatically detect and correct both syntactic and semantic errors via autoregressive re-prompting, resulting in significant improvements in task completion. We show that our approach outperforms several methods using LLMs as planners in complex task domains.
Resolving Ambiguity via Dialogue to Correct Unsynthesizable Controllers for Free-Flying Robots
Apr 11, 2023In situations such as habitat construction, station inspection, or cooperative exploration, incorrect assumptions about the environment or task across the team could lead to mission failure. Thus it is important to resolve any ambiguity about the mission between teammates before embarking on a commanded task. The safeguards guaranteed by formal methods can be used to synthesize correct-by-construction reactive controllers for a robot using Linear Temporal Logic. If a robot fails to synthesize a controller given an instruction, it is clear that there exists a logical inconsistency in the environmental assumptions and/or described interactions. These specifications however are typically crafted in a language unique to the verification framework, requiring the human collaborator to be fluent in the software tool used to construct it. Furthermore, if the controller fails to synthesize, it may prove difficult to easily repair the specification. Language is a natural medium to generate these specifications using modern symbol grounding techniques. Using language empowers non-expert humans to describe tasks to robot teammates while retaining the benefits of formal verification. Additionally, dialogue could be used to inform robots about the environment and/or resolve any ambiguities before mission execution. This paper introduces an architecture for natural language interaction using a symbolic representation that informs the construction of a specification in Linear Temporal Logic. The novel aspect of this approach is that it provides a mechanism for resolving synthesis failure by hypothesizing corrections to the specification that are verified through human-robot dialogue. Experiments involving the proposed architecture are demonstrated using a simulation of an Astrobee robot navigating in the International Space Station.
Robot-Initiated Specification Repair through Grounded Language Interaction
Oct 03, 2017
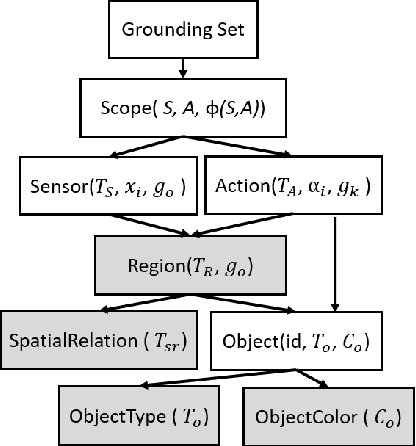
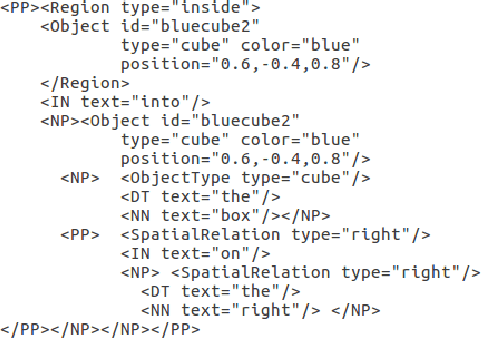

Robots are required to execute increasingly complex instructions in dynamic environments, which can lead to a disconnect between the user's intent and the robot's representation of the instructions. In this paper we present a natural language instruction grounding framework which uses formal synthesis to enable the robot to identify necessary environment assumptions for the task to be successful. These assumptions are then expressed via natural language questions referencing objects in the environment. The user is prompted to confirm or reject the assumption. We demonstrate our approach on two tabletop pick-and-place tasks.