 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally-Sampled Efficiently Adaptive State Lattices for Autonomous Ground Robot Navigation in Partially Observed Environments
Feb 13, 2026Due to sensor limitations, environments that off-road mobile robots operate in are often only partially observable. As the robots move throughout the environment and towards their goal, the optimal route is continuously revised as the sensors perceive new information. In traditional autonomous navigation architectures, a regional motion planner will consume the environment map and output a trajectory for the local motion planner to use as a reference. Due to the continuous revision of the regional plan guidance as a result of changing map information, the reference trajectories which are passed down to the local planner can differ significantly across sequential planning cycles. This rapidly changing guidance can result in unsafe navigation behavior, often requiring manual safety interventions during autonomous traversals in off-road environments. To remedy this problem, we propose Temporally-Sampled Efficiently Adaptive State Lattices (TSEASL), which is a regional planner arbitration architecture that considers updated and optimized versions of previously generated trajectories against the currently generated trajectory. When tested on a Clearpath Robotics Warthog Unmanned Ground Vehicle as well as real map data collected from the Warthog, results indicate that when running TSEASL, the robot did not require manual interventions in the same locations where the robot was running the baseline planner. Additionally, higher levels of planner stability were recorded with TSEASL over the baseline. The paper concludes with a discussion of further improvements to TSEASL in order to make it more generalizable to various off-road autonomy scenarios.
Terrain-Aware Kinodynamic Planning with Efficiently Adaptive State Lattices for Mobile Robot Navigation in Off-Road Environments
Apr 24, 2025To safely traverse non-flat terrain, robots must account for the influence of terrain shape in their planned motions. Terrain-aware motion planners use an estimate of the vehicle roll and pitch as a function of pose, vehicle suspension, and ground elevation map to weigh the cost of edges in the search space. Encoding such information in a traditional two-dimensional cost map is limiting because it is unable to capture the influence of orientation on the roll and pitch estimates from sloped terrain. The research presented herein addresses this problem by encoding kinodynamic information in the edges of a recombinant motion planning search space based on the Efficiently Adaptive State Lattice (EASL). This approach, which we describe as a Kinodynamic Efficiently Adaptive State Lattice (KEASL), differs from the prior representation in two ways. First, this method uses a novel encoding of velocity and acceleration constraints and vehicle direction at expanded nodes in the motion planning graph. Second, this approach describes additional steps for evaluating the roll, pitch, constraints, and velocities associated with poses along each edge during search in a manner that still enables the graph to remain recombinant. Velocities are computed using an iterative bidirectional method using Eulerian integration that more accurately estimates the duration of edges that are subject to terrain-dependent velocity limits. Real-world experiments on a Clearpath Robotics Warthog Unmanned Ground Vehicle were performed in a non-flat, unstructured environment. Results from 2093 planning queries from these experiments showed that KEASL provided a more efficient route than EASL in 83.72% of cases when EASL plans were adjusted to satisfy terrain-dependent velocity constraints. An analysis of relative runtimes and differences between planned routes is additionally presented.
* 8 page paper with 1 additional copyright page. Published at the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Resolving Ambiguity via Dialogue to Correct Unsynthesizable Controllers for Free-Flying Robots
Apr 11, 2023In situations such as habitat construction, station inspection, or cooperative exploration, incorrect assumptions about the environment or task across the team could lead to mission failure. Thus it is important to resolve any ambiguity about the mission between teammates before embarking on a commanded task. The safeguards guaranteed by formal methods can be used to synthesize correct-by-construction reactive controllers for a robot using Linear Temporal Logic. If a robot fails to synthesize a controller given an instruction, it is clear that there exists a logical inconsistency in the environmental assumptions and/or described interactions. These specifications however are typically crafted in a language unique to the verification framework, requiring the human collaborator to be fluent in the software tool used to construct it. Furthermore, if the controller fails to synthesize, it may prove difficult to easily repair the specification. Language is a natural medium to generate these specifications using modern symbol grounding techniques. Using language empowers non-expert humans to describe tasks to robot teammates while retaining the benefits of formal verification. Additionally, dialogue could be used to inform robots about the environment and/or resolve any ambiguities before mission execution. This paper introduces an architecture for natural language interaction using a symbolic representation that informs the construction of a specification in Linear Temporal Logic. The novel aspect of this approach is that it provides a mechanism for resolving synthesis failure by hypothesizing corrections to the specification that are verified through human-robot dialogue. Experiments involving the proposed architecture are demonstrated using a simulation of an Astrobee robot navigating in the International Space Station.
Language Understanding for Field and Service Robots in a Priori Unknown Environments
May 21, 2021
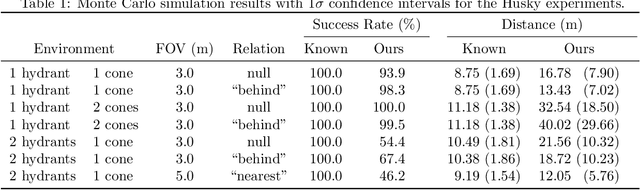

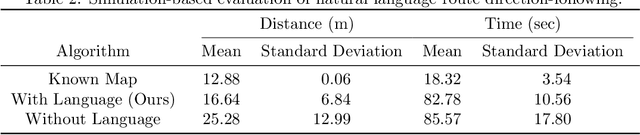
Contemporary approaches to perception, planning, estimation, and control have allowed robots to operate robustly as our remote surrogates in uncertain, unstructured environments. There is now an opportunity for robots to operate not only in isolation, but also with and alongside humans in our complex environments. Natural language provides an efficient and flexible medium through which humans can communicate with collaborative robots. Through significant progress in statistical methods for natural language understanding, robots are now able to interpret a diverse array of free-form navigation, manipulation, and mobile manipulation commands. However, most contemporary approaches require a detailed prior spatial-semantic map of the robot's environment that models the space of possible referents of the utterance. Consequently, these methods fail when robots are deployed in new, previously unknown, or partially observed environments, particularly when mental models of the environment differ between the human operator and the robot. This paper provides a comprehensive description of a novel learning framework that allows field and service robots to interpret and correctly execute natural language instructions in a priori unknown, unstructured environments. Integral to our approach is its use of language as a "sensor" -- inferring spatial, topological, and semantic information implicit in natural language utterances and then exploiting this information to learn a distribution over a latent environment model. We incorporate this distribution in a probabilistic language grounding model and infer a distribution over a symbolic representation of the robot's action space. We use imitation learning to identify a belief space policy that reasons over the environment and behavior distributions. We evaluate our framework through a variety of different navigation and mobile manipulation experiments.
Language-guided Semantic Mapping and Mobile Manipulation in Partially Observable Environments
Oct 22, 2019
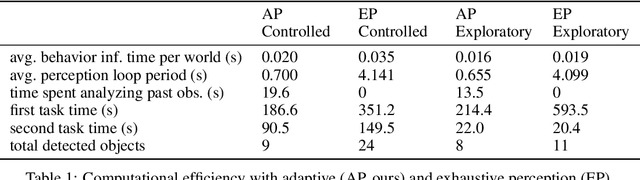

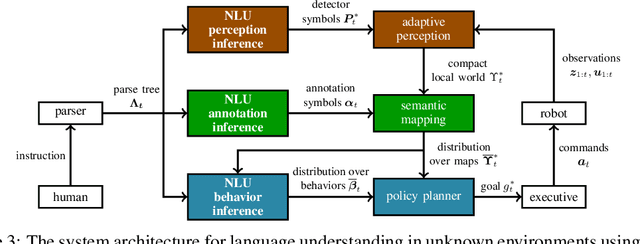
Recent advances in data-driven models for grounded language understanding have enabled robots to interpret increasingly complex instructions. Two fundamental limitations of these methods are that most require a full model of the environment to be known a priori, and they attempt to reason over a world representation that is flat and unnecessarily detailed, which limits scalability. Recent semantic mapping methods address partial observability by exploiting language as a sensor to infer a distribution over topological, metric and semantic properties of the environment. However, maintaining a distribution over highly detailed maps that can support grounding of diverse instructions is computationally expensive and hinders real-time human-robot collaboration. We propose a novel framework that learns to adapt perception according to the task in order to maintain compact distributions over semantic maps. Experiments with a mobile manipulator demonstrate more efficient instruction following in a priori unknown environments.
Language-guided Adaptive Perception with Hierarchical Symbolic Representations for Mobile Manipulators
Sep 21, 2019
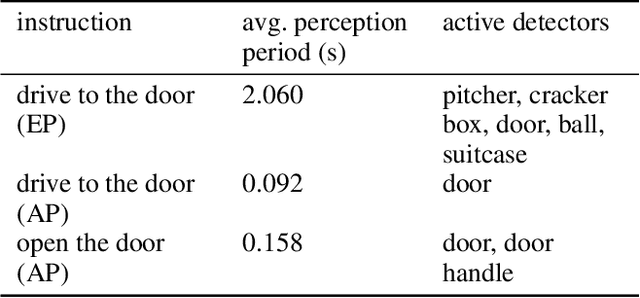
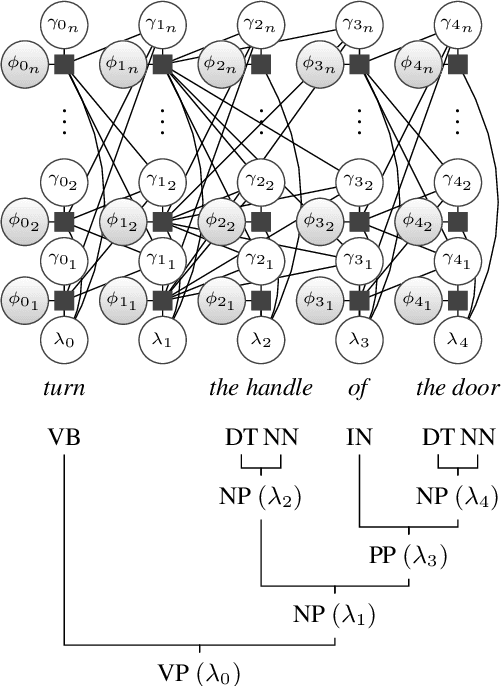

Language is an effective medium for bi-directional communication in human-robot teams. To infer the meaning of many instructions, robots need to construct a model of their surroundings that describe the spatial, semantic, and metric properties of objects from observations and prior information about the environment. Recent algorithms condition the expression of object detectors in a robot's perception pipeline on language to generate a minimal representation of the environment necessary to efficiently determine the meaning of the instruction. We expand on this work by introducing the ability to express hierarchies between detectors. This assists in the development of environment models suitable for more sophisticated tasks that may require modeling of kinematics, dynamics, and/or affordances between objects. To achieve this, a novel extension of symbolic representations for language-guided adaptive perception is proposed that reasons over single-layer object detector hierarchies. Differences in perception performance and environment representations between adaptive perception and a suitable exhaustive baseline are explored through physical experiments on a mobile manipulator.
Inferring Compact Representations for Efficient Natural Language Understanding of Robot Instructions
Mar 21, 2019
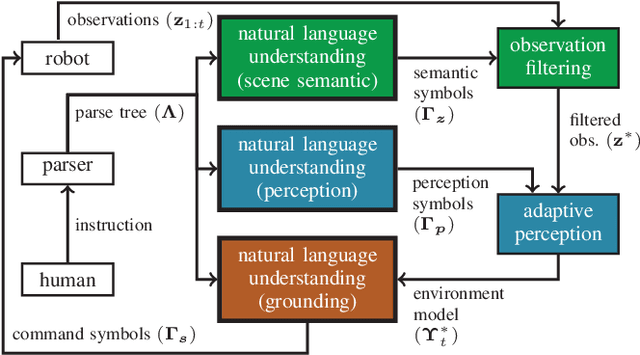


The speed and accuracy with which robots are able to interpret natural language is fundamental to realizing effective human-robot interaction. A great deal of attention has been paid to developing models and approximate inference algorithms that improve the efficiency of language understanding. However, existing methods still attempt to reason over a representation of the environment that is flat and unnecessarily detailed, which limits scalability. An open problem is then to develop methods capable of producing the most compact environment model sufficient for accurate and efficient natural language understanding. We propose a model that leverages environment-related information encoded within instructions to identify the subset of observations and perceptual classifiers necessary to perceive a succinct, instruction-specific environment representation. The framework uses three probabilistic graphical models trained from a corpus of annotated instructions to infer salient scene semantics, perceptual classifiers, and grounded symbols. Experimental results on two robots operating in different environments demonstrate that by exploiting the content and the structure of the instructions, our method learns compact environment representations that significantly improve the efficiency of natural language symbol grounding.
Adaptive Grasp Control through Multi-Modal Interactions for Assistive Prosthetic Devices
Oct 18, 2018
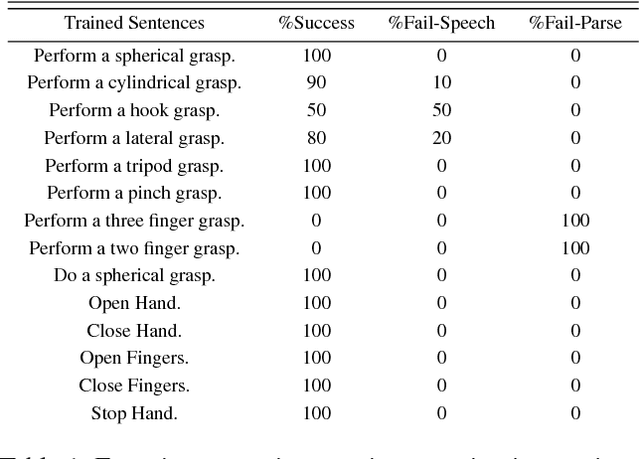
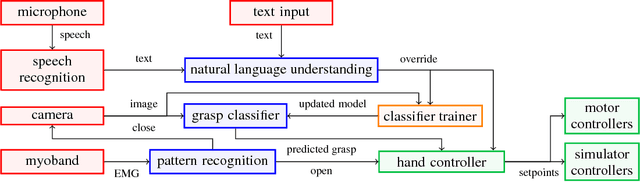

The hand is one of the most complex and important parts of the human body. The dexterity provided by its multiple degrees of freedom enables us to perform many of the tasks of daily living which involve grasping and manipulating objects of interest. Contemporary prosthetic devices for people with transradial amputations or wrist disarticulation vary in complexity, from passive prosthetics to complex devices that are body or electrically driven. One of the important challenges in developing smart prosthetic hands is to create devices which are able to mimic all activities that a person might perform and address the needs of a wide variety of users. The approach explored here is to develop algorithms that permit a device to adapt its behavior to the preferences of the operator through interactions with the wearer. This device uses multiple sensing modalities including muscle activity from a myoelectric armband, visual information from an on-board camera, tactile input through a touchscreen interface, and speech input from an embedded microphone. Presented within this paper are the design, software and controls of a platform used to evaluate this architecture as well as results from experiments deigned to quantify the performance.
Learning Models for Following Natural Language Directions in Unknown Environments
Mar 17, 2015
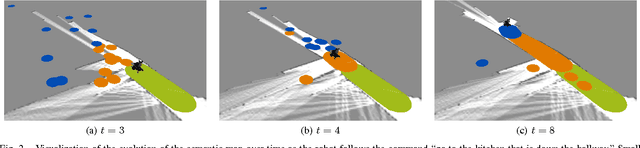
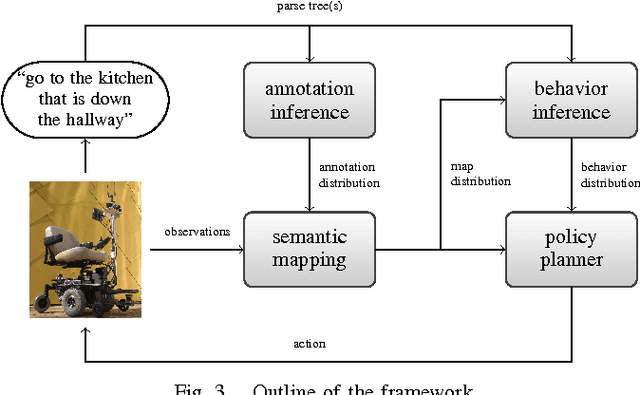
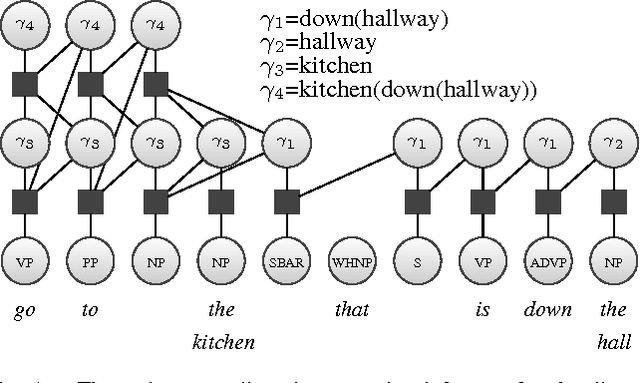
Natural language offers an intuitive and flexible means for humans to communicate with the robots that we will increasingly work alongside in our homes and workplaces. Recent advancements have given rise to robots that are able to interpret natural language manipulation and navigation commands, but these methods require a prior map of the robot's environment. In this paper, we propose a novel learning framework that enables robots to successfully follow natural language route directions without any previous knowledge of the environment. The algorithm utilizes spatial and semantic information that the human conveys through the command to learn a distribution over the metric and semantic properties of spatially extended environments. Our method uses this distribution in place of the latent world model and interprets the natural language instruction as a distribution over the intended behavior. A novel belief space planner reasons directly over the map and behavior distributions to solve for a policy using imitation learning. We evaluate our framework on a voice-commandable wheelchair. The results demonstrate that by learning and performing inference over a latent environment model, the algorithm is able to successfully follow natural language route directions within novel, extended environments.