 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROFIT: A Specialized Optimizer for Deep Fine Tuning
Dec 09, 2024

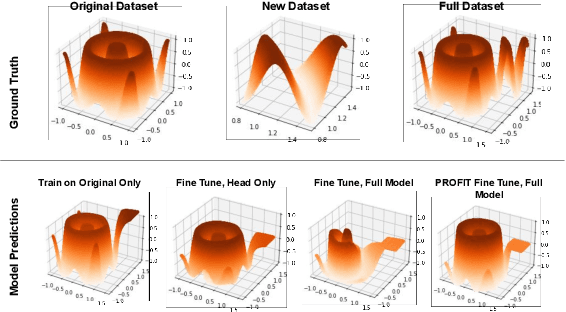
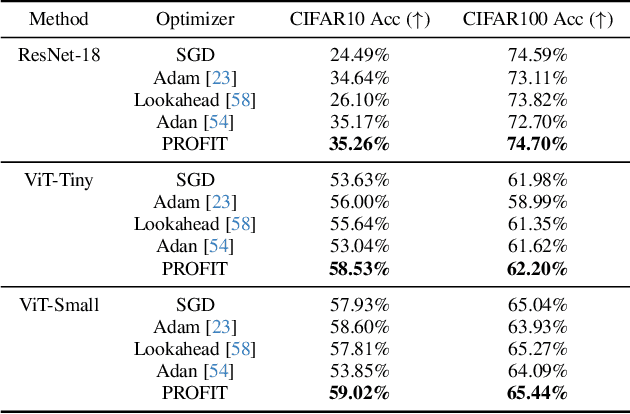
Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT (Proximally Restricted Optimizer For Iterative Training), one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
PROFIT: A PROximal FIne Tuning Optimizer for Multi-Task Learning
Dec 02, 2024Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT, one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
Language Understanding for Field and Service Robots in a Priori Unknown Environments
May 21, 2021
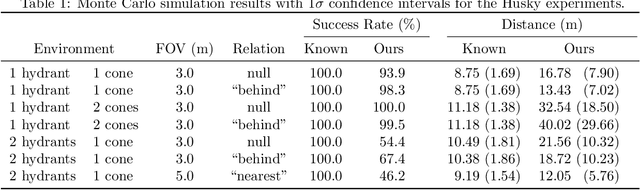

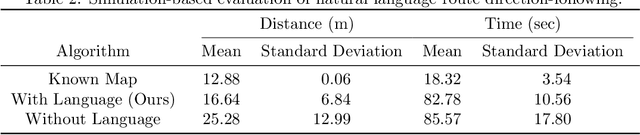
Contemporary approaches to perception, planning, estimation, and control have allowed robots to operate robustly as our remote surrogates in uncertain, unstructured environments. There is now an opportunity for robots to operate not only in isolation, but also with and alongside humans in our complex environments. Natural language provides an efficient and flexible medium through which humans can communicate with collaborative robots. Through significant progress in statistical methods for natural language understanding, robots are now able to interpret a diverse array of free-form navigation, manipulation, and mobile manipulation commands. However, most contemporary approaches require a detailed prior spatial-semantic map of the robot's environment that models the space of possible referents of the utterance. Consequently, these methods fail when robots are deployed in new, previously unknown, or partially observed environments, particularly when mental models of the environment differ between the human operator and the robot. This paper provides a comprehensive description of a novel learning framework that allows field and service robots to interpret and correctly execute natural language instructions in a priori unknown, unstructured environments. Integral to our approach is its use of language as a "sensor" -- inferring spatial, topological, and semantic information implicit in natural language utterances and then exploiting this information to learn a distribution over a latent environment model. We incorporate this distribution in a probabilistic language grounding model and infer a distribution over a symbolic representation of the robot's action space. We use imitation learning to identify a belief space policy that reasons over the environment and behavior distributions. We evaluate our framework through a variety of different navigation and mobile manipulation experiments.
Learning Models for Following Natural Language Directions in Unknown Environments
Mar 17, 2015
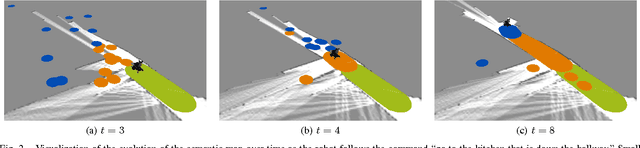
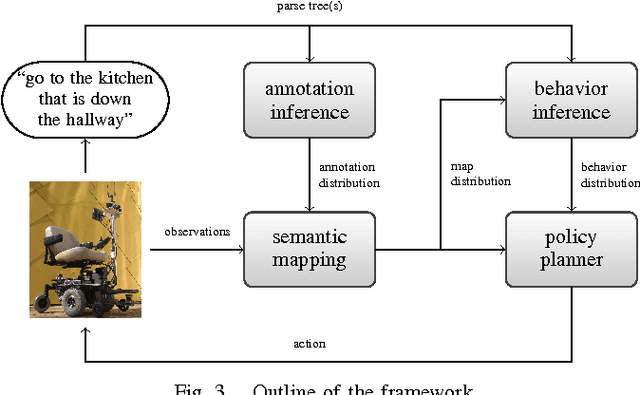
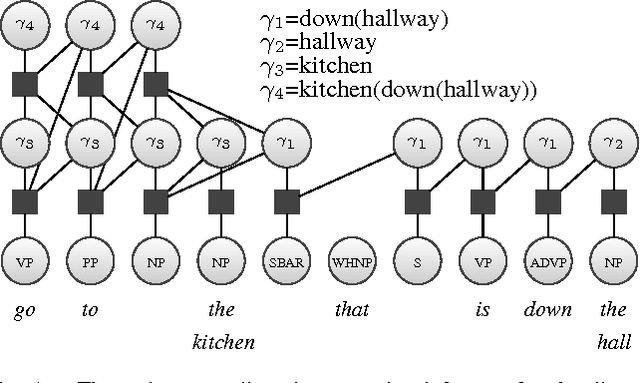
Natural language offers an intuitive and flexible means for humans to communicate with the robots that we will increasingly work alongside in our homes and workplaces. Recent advancements have given rise to robots that are able to interpret natural language manipulation and navigation commands, but these methods require a prior map of the robot's environment. In this paper, we propose a novel learning framework that enables robots to successfully follow natural language route directions without any previous knowledge of the environment. The algorithm utilizes spatial and semantic information that the human conveys through the command to learn a distribution over the metric and semantic properties of spatially extended environments. Our method uses this distribution in place of the latent world model and interprets the natural language instruction as a distribution over the intended behavior. A novel belief space planner reasons directly over the map and behavior distributions to solve for a policy using imitation learning. We evaluate our framework on a voice-commandable wheelchair. The results demonstrate that by learning and performing inference over a latent environment model, the algorithm is able to successfully follow natural language route directions within novel, extended environments.