 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBelief Roadmaps with Uncertain Landmark Evanescence
Jan 29, 2025



We would like a robot to navigate to a goal location while minimizing state uncertainty. To aid the robot in this endeavor, maps provide a prior belief over the location of objects and regions of interest. To localize itself within the map, a robot identifies mapped landmarks using its sensors. However, as the time between map creation and robot deployment increases, portions of the map can become stale, and landmarks, once believed to be permanent, may disappear. We refer to the propensity of a landmark to disappear as landmark evanescence. Reasoning about landmark evanescence during path planning, and the associated impact on localization accuracy, requires analyzing the presence or absence of each landmark, leading to an exponential number of possible outcomes of a given motion plan. To address this complexity, we develop BRULE, an extension of the Belief Roadmap. During planning, we replace the belief over future robot poses with a Gaussian mixture which is able to capture the effects of landmark evanescence. Furthermore, we show that belief updates can be made efficient, and that maintaining a random subset of mixture components is sufficient to find high quality solutions. We demonstrate performance in simulated and real-world experiments. Software is available at https://bit.ly/BRULE.
Language Understanding for Field and Service Robots in a Priori Unknown Environments
May 21, 2021
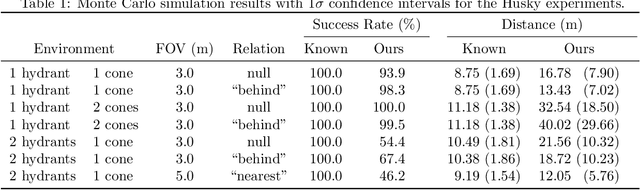

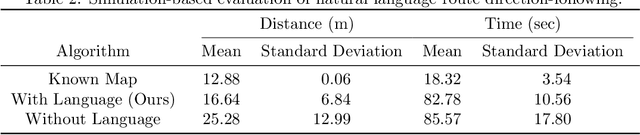
Contemporary approaches to perception, planning, estimation, and control have allowed robots to operate robustly as our remote surrogates in uncertain, unstructured environments. There is now an opportunity for robots to operate not only in isolation, but also with and alongside humans in our complex environments. Natural language provides an efficient and flexible medium through which humans can communicate with collaborative robots. Through significant progress in statistical methods for natural language understanding, robots are now able to interpret a diverse array of free-form navigation, manipulation, and mobile manipulation commands. However, most contemporary approaches require a detailed prior spatial-semantic map of the robot's environment that models the space of possible referents of the utterance. Consequently, these methods fail when robots are deployed in new, previously unknown, or partially observed environments, particularly when mental models of the environment differ between the human operator and the robot. This paper provides a comprehensive description of a novel learning framework that allows field and service robots to interpret and correctly execute natural language instructions in a priori unknown, unstructured environments. Integral to our approach is its use of language as a "sensor" -- inferring spatial, topological, and semantic information implicit in natural language utterances and then exploiting this information to learn a distribution over a latent environment model. We incorporate this distribution in a probabilistic language grounding model and infer a distribution over a symbolic representation of the robot's action space. We use imitation learning to identify a belief space policy that reasons over the environment and behavior distributions. We evaluate our framework through a variety of different navigation and mobile manipulation experiments.
Actor-Action Video Classification CSC 249/449 Spring 2020 Challenge Report
Aug 18, 2020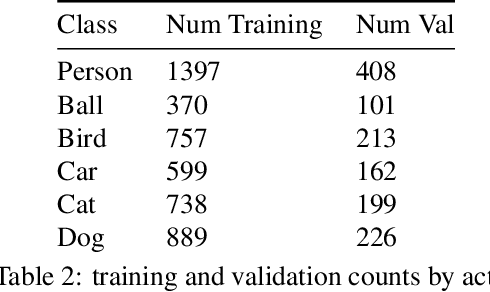
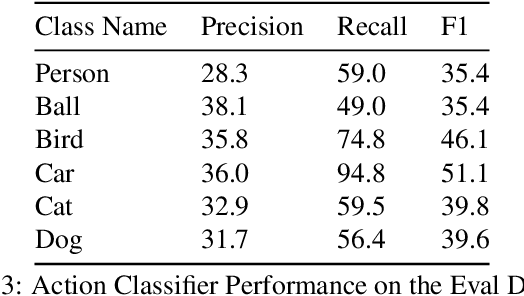
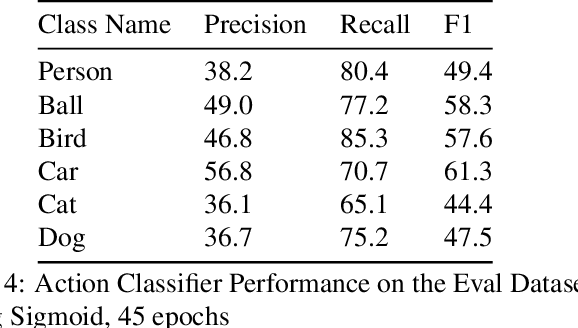
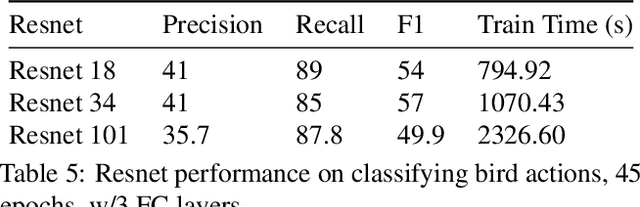
This technical report summarizes submissions and compiles from Actor-Action video classification challenge held as a final project in CSC 249/449 Machine Vision course (Spring 2020) at University of Rochester
Language-guided Semantic Mapping and Mobile Manipulation in Partially Observable Environments
Oct 22, 2019
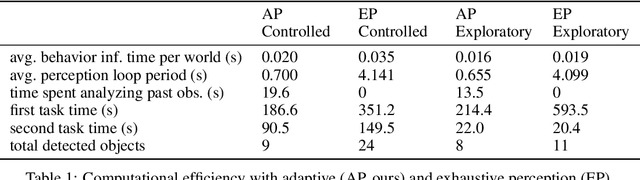

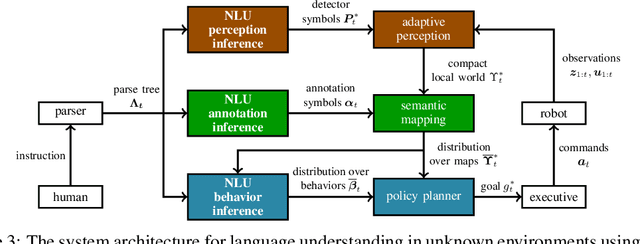
Recent advances in data-driven models for grounded language understanding have enabled robots to interpret increasingly complex instructions. Two fundamental limitations of these methods are that most require a full model of the environment to be known a priori, and they attempt to reason over a world representation that is flat and unnecessarily detailed, which limits scalability. Recent semantic mapping methods address partial observability by exploiting language as a sensor to infer a distribution over topological, metric and semantic properties of the environment. However, maintaining a distribution over highly detailed maps that can support grounding of diverse instructions is computationally expensive and hinders real-time human-robot collaboration. We propose a novel framework that learns to adapt perception according to the task in order to maintain compact distributions over semantic maps. Experiments with a mobile manipulator demonstrate more efficient instruction following in a priori unknown environments.
Language-guided Adaptive Perception with Hierarchical Symbolic Representations for Mobile Manipulators
Sep 21, 2019
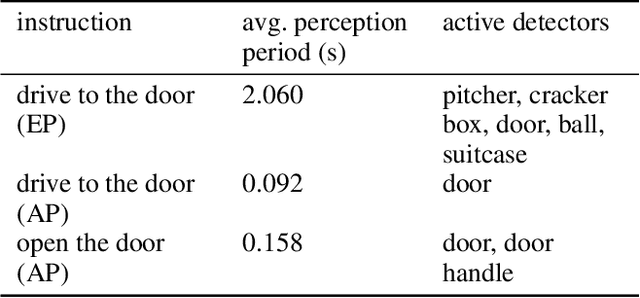
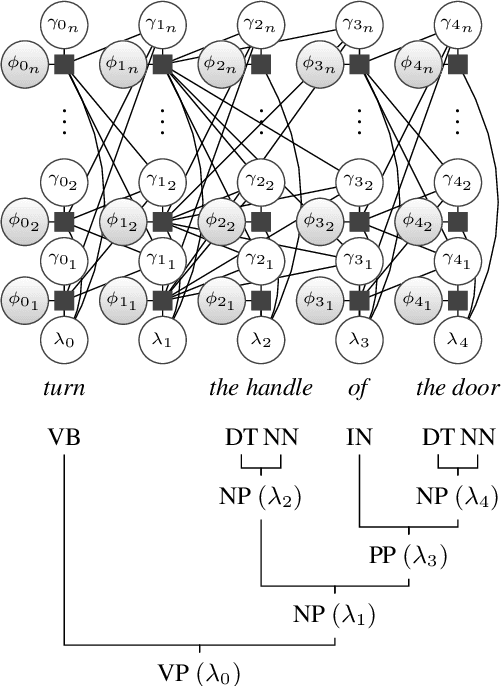

Language is an effective medium for bi-directional communication in human-robot teams. To infer the meaning of many instructions, robots need to construct a model of their surroundings that describe the spatial, semantic, and metric properties of objects from observations and prior information about the environment. Recent algorithms condition the expression of object detectors in a robot's perception pipeline on language to generate a minimal representation of the environment necessary to efficiently determine the meaning of the instruction. We expand on this work by introducing the ability to express hierarchies between detectors. This assists in the development of environment models suitable for more sophisticated tasks that may require modeling of kinematics, dynamics, and/or affordances between objects. To achieve this, a novel extension of symbolic representations for language-guided adaptive perception is proposed that reasons over single-layer object detector hierarchies. Differences in perception performance and environment representations between adaptive perception and a suitable exhaustive baseline are explored through physical experiments on a mobile manipulator.
Adaptive spline fitting with particle swarm optimization
Jul 30, 2019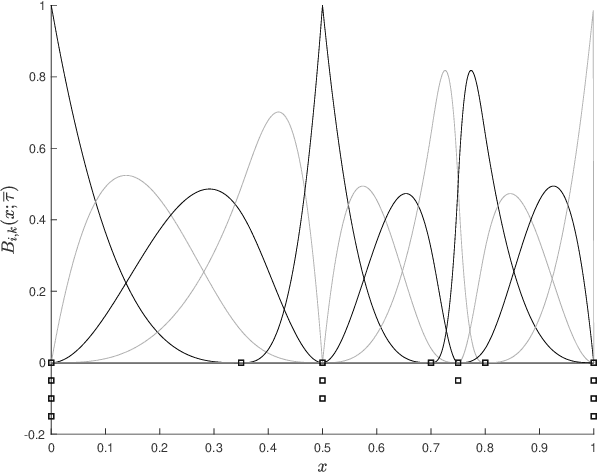
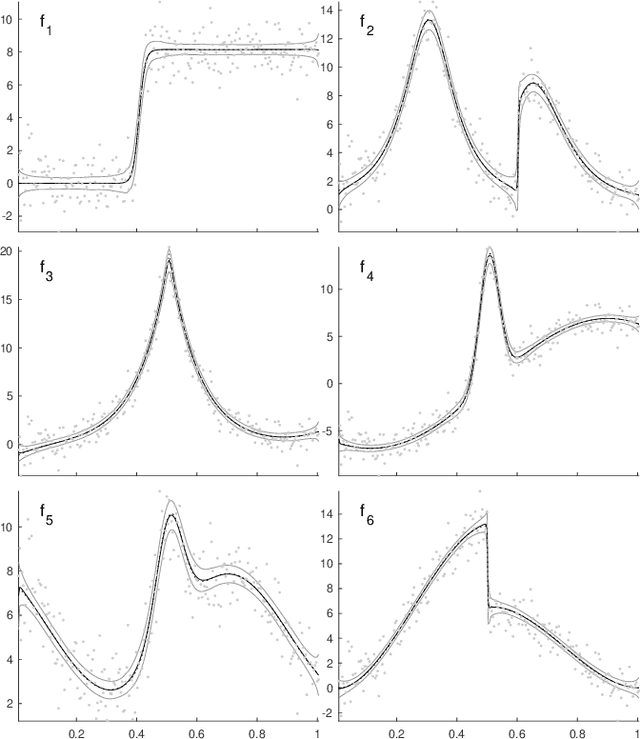
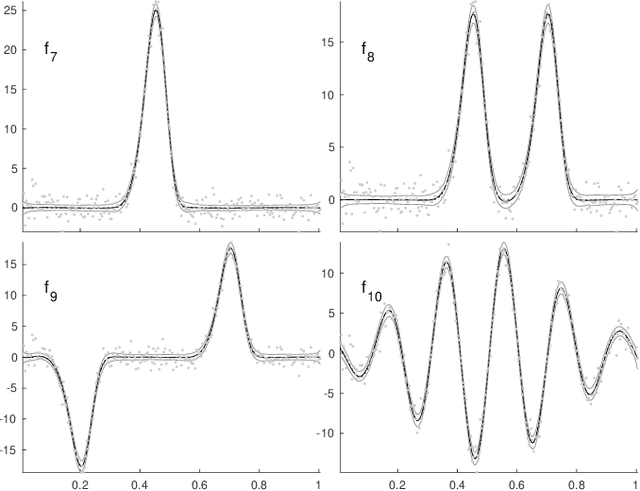
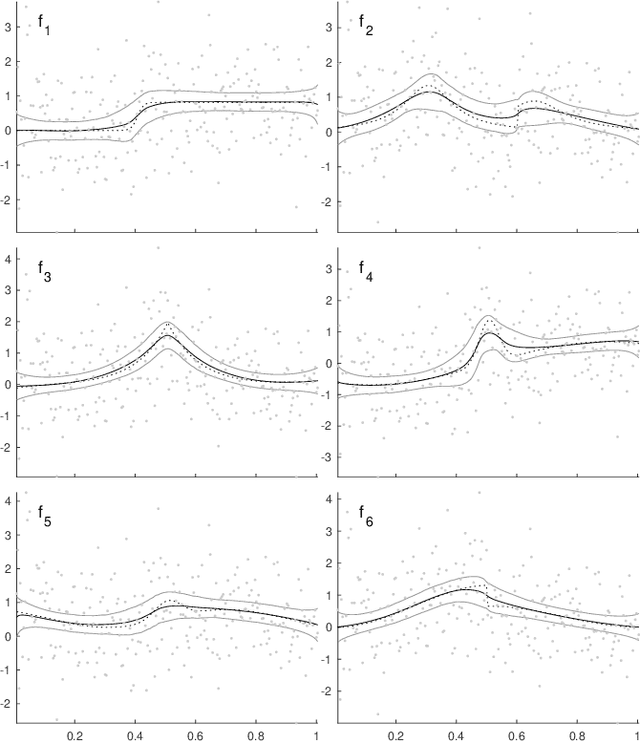
In fitting data with a spline, finding the optimal placement of knots can significantly improve the quality of the fit. However, the challenging high-dimensional and non-convex optimization problem associated with completely free knot placement has been a major roadblock in using this approach. We present a method that uses particle swarm optimization (PSO) combined with model selection to address this challenge. The problem of overfitting due to knot clustering that accompanies free knot placement is mitigated in this method by explicit regularization, resulting in a significantly improved performance on highly noisy data. The principal design choices available in the method are delineated and a statistically rigorous study of their effect on performance is carried out using simulated data and a wide variety of benchmark functions. Our results demonstrate that PSO-based free knot placement leads to a viable and flexible adaptive spline fitting approach that allows the fitting of both smooth and non-smooth functions.