 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-guided Adaptive Perception with Hierarchical Symbolic Representations for Mobile Manipulators
Paper and Code
Sep 21, 2019
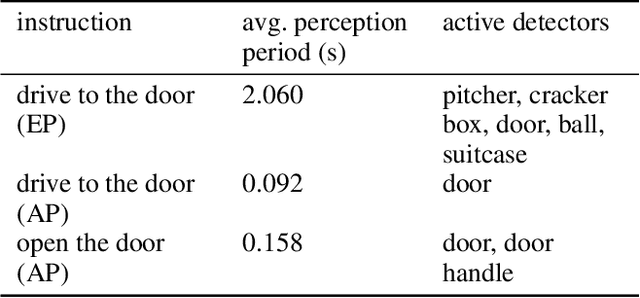
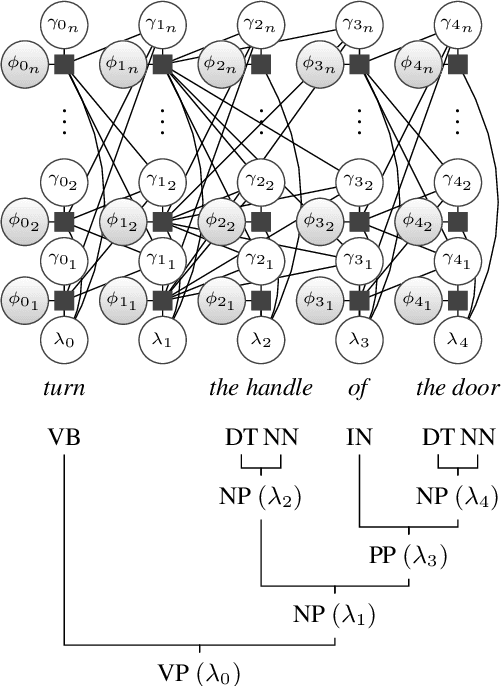

Language is an effective medium for bi-directional communication in human-robot teams. To infer the meaning of many instructions, robots need to construct a model of their surroundings that describe the spatial, semantic, and metric properties of objects from observations and prior information about the environment. Recent algorithms condition the expression of object detectors in a robot's perception pipeline on language to generate a minimal representation of the environment necessary to efficiently determine the meaning of the instruction. We expand on this work by introducing the ability to express hierarchies between detectors. This assists in the development of environment models suitable for more sophisticated tasks that may require modeling of kinematics, dynamics, and/or affordances between objects. To achieve this, a novel extension of symbolic representations for language-guided adaptive perception is proposed that reasons over single-layer object detector hierarchies. Differences in perception performance and environment representations between adaptive perception and a suitable exhaustive baseline are explored through physical experiments on a mobile manipulator.