 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs
Jun 09, 2025In this paper, we introduce a multi-robot system that integrates mapping, localization, and task and motion planning (TAMP) enabled by 3D scene graphs to execute complex instructions expressed in natural language. Our system builds a shared 3D scene graph incorporating an open-set object-based map, which is leveraged for multi-robot 3D scene graph fusion. This representation supports real-time, view-invariant relocalization (via the object-based map) and planning (via the 3D scene graph), allowing a team of robots to reason about their surroundings and execute complex tasks. Additionally, we introduce a planning approach that translates operator intent into Planning Domain Definition Language (PDDL) goals using a Large Language Model (LLM) by leveraging context from the shared 3D scene graph and robot capabilities. We provide an experimental assessment of the performance of our system on real-world tasks in large-scale, outdoor environments.
Task and Motion Planning in Hierarchical 3D Scene Graphs
Mar 12, 2024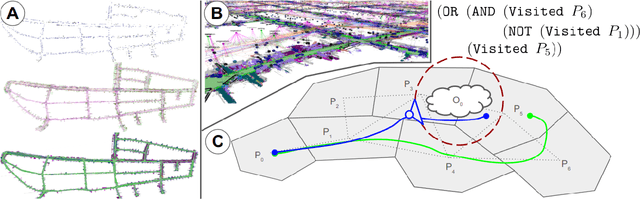
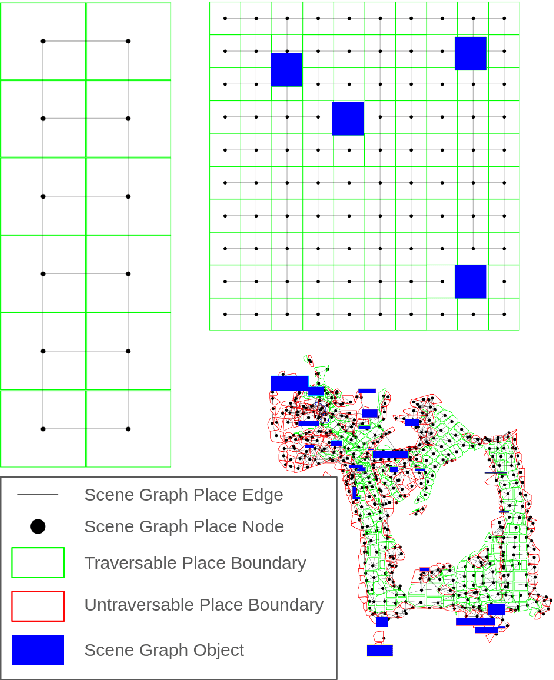
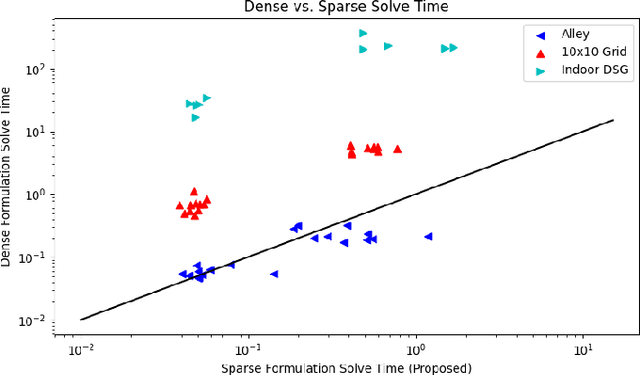
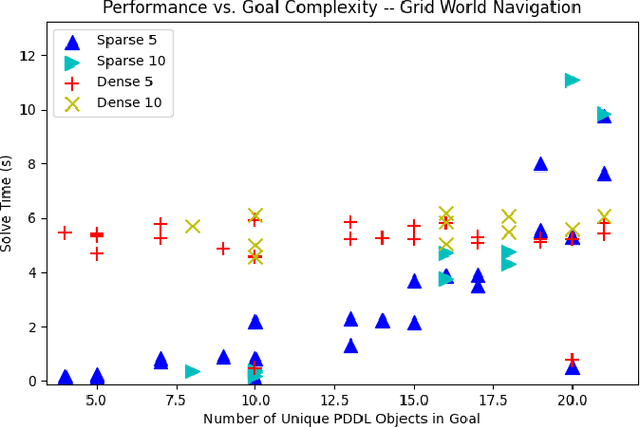
Recent work in the construction of 3D scene graphs has enabled mobile robots to build large-scale hybrid metric-semantic hierarchical representations of the world. These detailed models contain information that is useful for planning, however how to derive a planning domain from a 3D scene graph that enables efficient computation of executable plans is an open question. In this work, we present a novel approach for defining and solving Task and Motion Planning problems in large-scale environments using hierarchical 3D scene graphs. We identify a method for building sparse problem domains which enable scaling to large scenes, and propose a technique for incrementally adding objects to that domain during planning time to avoid wasting computation on irrelevant elements of the scene graph. We test our approach in two hand crafted domains as well as two scene graphs built from perception, including one constructed from the KITTI dataset. A video supplement is available at https://youtu.be/63xuCCaN0I4.
Aggressive Aerial Grasping using a Soft Drone with Onboard Perception
Aug 11, 2023Contrary to the stunning feats observed in birds of prey, aerial manipulation and grasping with flying robots still lack versatility and agility. Conventional approaches using rigid manipulators require precise positioning and are subject to large reaction forces at grasp, which limit performance at high speeds. The few reported examples of aggressive aerial grasping rely on motion capture systems, or fail to generalize across environments and grasp targets. We describe the first example of a soft aerial manipulator equipped with a fully onboard perception pipeline, capable of robustly localizing and grasping visually and morphologically varied objects. The proposed system features a novel passively closing tendon-actuated soft gripper that enables fast closure at grasp, while compensating for position errors, complying to the target-object morphology, and dampening reaction forces. The system includes an onboard perception pipeline that combines a neural-network-based semantic keypoint detector with a state-of-the-art robust 3D object pose estimator, whose estimate is further refined using a fixed-lag smoother. The resulting pose estimate is passed to a minimum-snap trajectory planner, tracked by an adaptive controller that fully compensates for the added mass of the grasped object. Finally, a finite-element-based controller determines optimal gripper configurations for grasping. Rigorous experiments confirm that our approach enables dynamic, aggressive, and versatile grasping. We demonstrate fully onboard vision-based grasps of a variety of objects, in both indoor and outdoor environments, and up to speeds of 2.0 m/s -- the fastest vision-based grasp reported in the literature. Finally, we take a major step in expanding the utility of our platform beyond stationary targets, by demonstrating motion-capture-based grasps of targets moving up to 0.3 m/s, with relative speeds up to 1.5 m/s.
Hydra-Multi: Collaborative Online Construction of 3D Scene Graphs with Multi-Robot Teams
Apr 26, 20233D scene graphs have recently emerged as an expressive high-level map representation that describes a 3D environment as a layered graph where nodes represent spatial concepts at multiple levels of abstraction (e.g., objects, rooms, buildings) and edges represent relations between concepts (e.g., inclusion, adjacency). This paper describes Hydra-Multi, the first multi-robot spatial perception system capable of constructing a multi-robot 3D scene graph online from sensor data collected by robots in a team. In particular, we develop a centralized system capable of constructing a joint 3D scene graph by taking incremental inputs from multiple robots, effectively finding the relative transforms between the robots' frames, and incorporating loop closure detections to correctly reconcile the scene graph nodes from different robots. We evaluate Hydra-Multi on simulated and real scenarios and show it is able to reconstruct accurate 3D scene graphs online. We also demonstrate Hydra-Multi's capability of supporting heterogeneous teams by fusing different map representations built by robots with different sensor suites.
Multi-robot Task Assignment for Aerial Tracking with Viewpoint Constraints
May 31, 2022
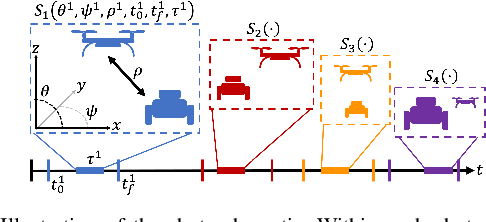
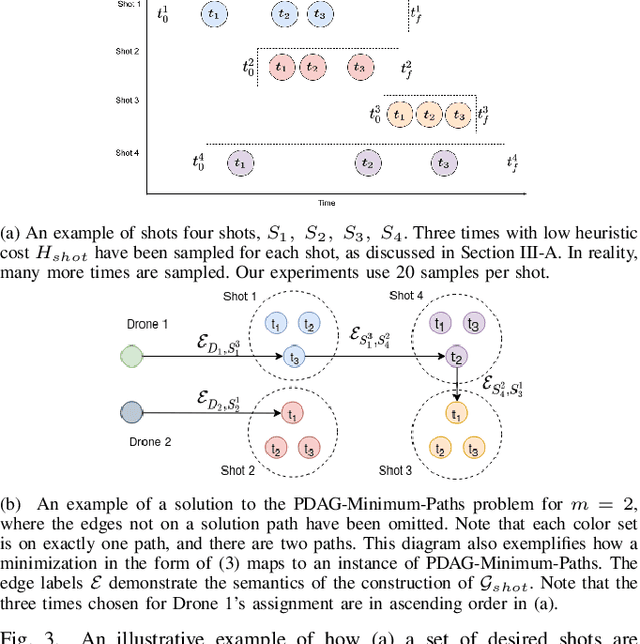
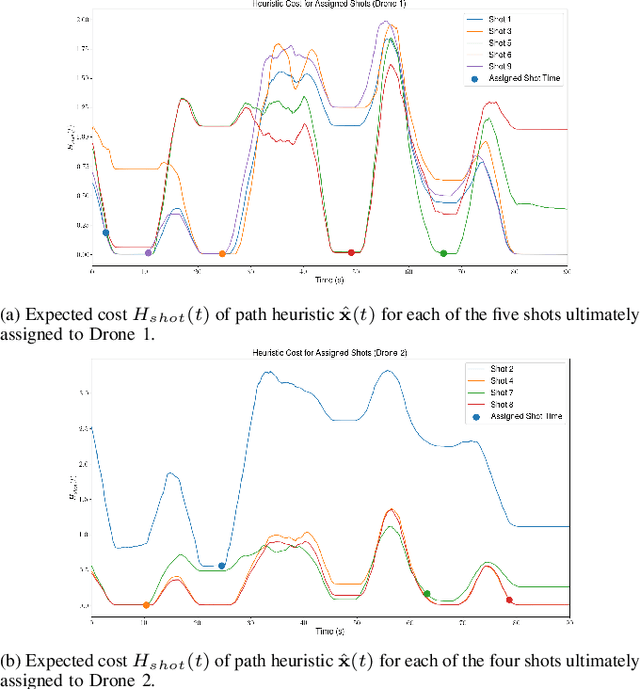
We address the problem of assigning a team of drones to autonomously capture a set desired shots of a dynamic target in the presence of obstacles. We present a two-stage planning pipeline that generates offline an assignment of drone to shots and locally optimizes online the viewpoint. Given desired shot parameters, the high-level planner uses a visibility heuristic to predict good times for capturing each shot and uses an Integer Linear Program to compute drone assignments. An online Model Predictive Control algorithm uses the assignments as reference to capture the shots. The algorithm is validated in hardware with a pair of drones and a remote controlled car.
Free-Space Ellipsoid Graphs for Multi-Agent Target Monitoring
May 31, 2022

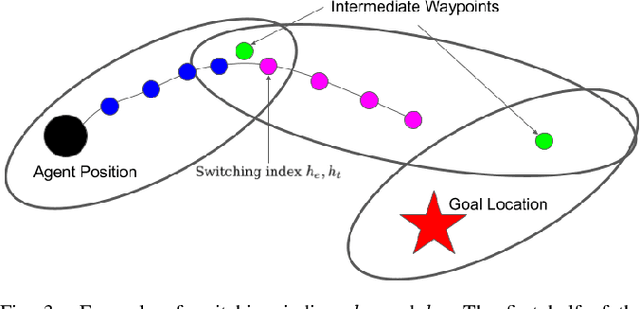
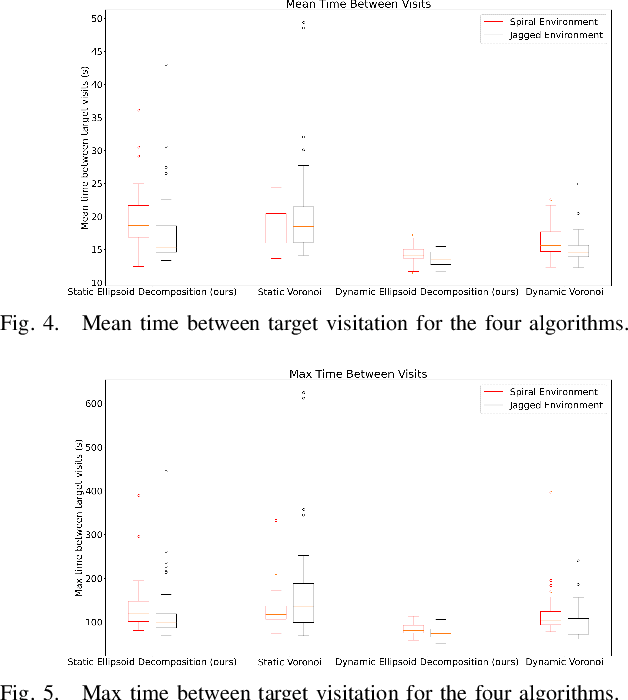
We apply a novel framework for decomposing and reasoning about free space in an environment to a multi-agent persistent monitoring problem. Our decomposition method represents free space as a collection of ellipsoids associated with a weighted connectivity graph. The same ellipsoids used for reasoning about connectivity and distance during high level planning can be used as state constraints in a Model Predictive Control algorithm to enforce collision-free motion. This structure allows for streamlined implementation in distributed multi-agent tasks in 2D and 3D environments. We illustrate its effectiveness for a team of tracking agents tasked with monitoring a group of target agents. Our algorithm uses the ellipsoid decomposition as a primitive for the coordination, path planning, and control of the tracking agents. Simulations with four tracking agents monitoring fifteen dynamic targets in obstacle-rich environments demonstrate the performance of our algorithm.