 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening Between the Lines: Decoding Podcast Narratives with Language Modeling
Nov 07, 2025



Podcasts have become a central arena for shaping public opinion, making them a vital source for understanding contemporary discourse. Their typically unscripted, multi-themed, and conversational style offers a rich but complex form of data. To analyze how podcasts persuade and inform, we must examine their narrative structures -- specifically, the narrative frames they employ. The fluid and conversational nature of podcasts presents a significant challenge for automated analysis. We show that existing large language models, typically trained on more structured text such as news articles, struggle to capture the subtle cues that human listeners rely on to identify narrative frames. As a result, current approaches fall short of accurately analyzing podcast narratives at scale. To solve this, we develop and evaluate a fine-tuned BERT model that explicitly links narrative frames to specific entities mentioned in the conversation, effectively grounding the abstract frame in concrete details. Our approach then uses these granular frame labels and correlates them with high-level topics to reveal broader discourse trends. The primary contributions of this paper are: (i) a novel frame-labeling methodology that more closely aligns with human judgment for messy, conversational data, and (ii) a new analysis that uncovers the systematic relationship between what is being discussed (the topic) and how it is being presented (the frame), offering a more robust framework for studying influence in digital media.
Subquadratic Algorithms and Hardness for Attention with Any Temperature
May 20, 2025


Despite the popularity of the Transformer architecture, the standard algorithm for computing Attention suffers from quadratic time complexity in context length $n$. Alman and Song [NeurIPS 2023] showed that when the head dimension $d = \Theta(\log n)$, subquadratic Attention is possible if and only if the inputs have small entries bounded by $B = o(\sqrt{\log n})$ in absolute values, under the Strong Exponential Time Hypothesis ($\mathsf{SETH}$). Equivalently, subquadratic Attention is possible if and only if the softmax is applied with high temperature for $d=\Theta(\log n)$. Running times of these algorithms depend exponentially on $B$ and thus they do not lead to even a polynomial-time algorithm outside the specific range of $B$. This naturally leads to the question: when can Attention be computed efficiently without strong assumptions on temperature? Are there fast attention algorithms that scale polylogarithmically with entry size $B$? In this work, we resolve this question and characterize when fast Attention for arbitrary temperatures is possible. First, for all constant $d = O(1)$, we give the first subquadratic $\tilde{O}(n^{2 - 1/d} \cdot \mathrm{polylog}(B))$ time algorithm for Attention with large $B$. Our result holds even for matrices with large head dimension if they have low rank. In this regime, we also give a similar running time for Attention gradient computation, and therefore for the full LLM training process. Furthermore, we show that any substantial improvement on our algorithm is unlikely. In particular, we show that even when $d = 2^{\Theta(\log^* n)}$, Attention requires $n^{2 - o(1)}$ time under $\mathsf{SETH}$. Finally, in the regime where $d = \mathrm{poly}(n)$, we show that the standard algorithm is optimal under popular fine-grained complexity assumptions.
A Diffusion Model for Simulation Ready Coronary Anatomy with Morpho-skeletal Control
Jul 23, 2024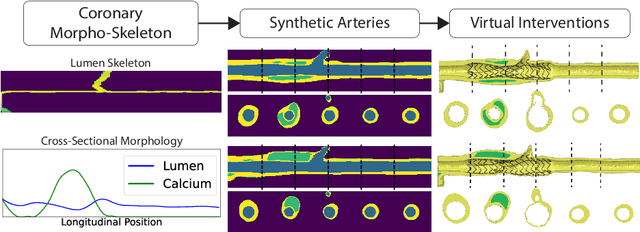
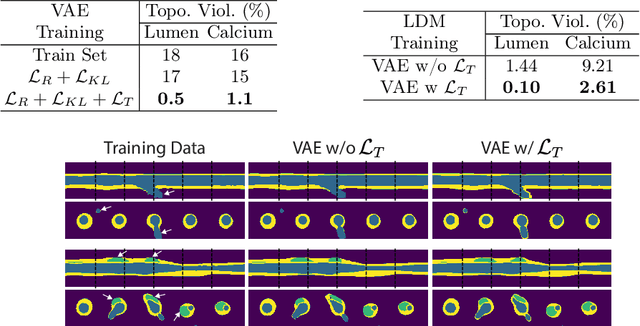
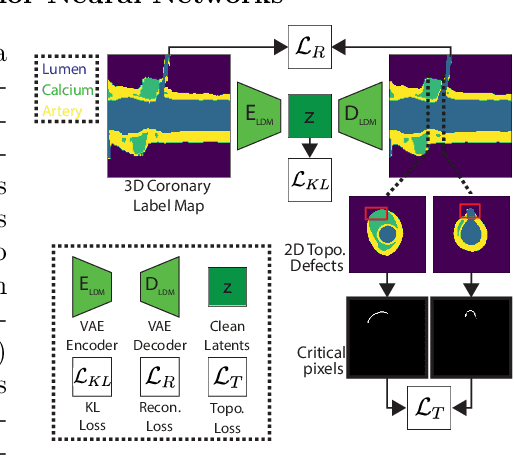
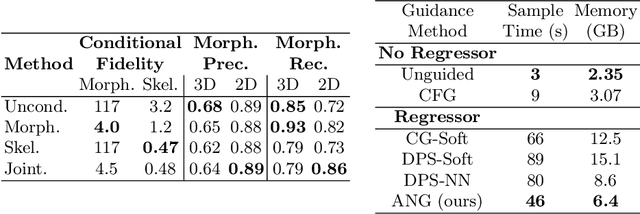
Virtual interventions enable the physics-based simulation of device deployment within coronary arteries. This framework allows for counterfactual reasoning by deploying the same device in different arterial anatomies. However, current methods to create such counterfactual arteries face a trade-off between controllability and realism. In this study, we investigate how Latent Diffusion Models (LDMs) can custom synthesize coronary anatomy for virtual intervention studies based on mid-level anatomic constraints such as topological validity, local morphological shape, and global skeletal structure. We also extend diffusion model guidance strategies to the context of morpho-skeletal conditioning and propose a novel guidance method for continuous attributes that adaptively updates the negative guiding condition throughout sampling. Our framework enables the generation and editing of coronary anatomy in a controllable manner, allowing device designers to derive mechanistic insights regarding anatomic variation and simulated device deployment.
Generation and De-Identification of Indian Clinical Discharge Summaries using LLMs
Jul 08, 2024
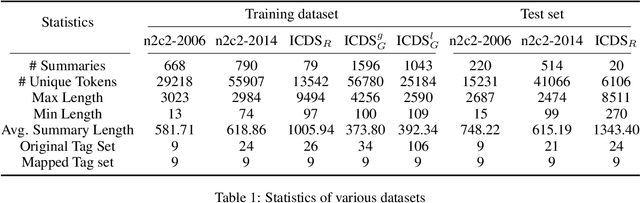


The consequences of a healthcare data breach can be devastating for the patients, providers, and payers. The average financial impact of a data breach in recent months has been estimated to be close to USD 10 million. This is especially significant for healthcare organizations in India that are managing rapid digitization while still establishing data governance procedures that align with the letter and spirit of the law. Computer-based systems for de-identification of personal information are vulnerable to data drift, often rendering them ineffective in cross-institution settings. Therefore, a rigorous assessment of existing de-identification against local health datasets is imperative to support the safe adoption of digital health initiatives in India. Using a small set of de-identified patient discharge summaries provided by an Indian healthcare institution, in this paper, we report the nominal performance of de-identification algorithms (based on language models) trained on publicly available non-Indian datasets, pointing towards a lack of cross-institutional generalization. Similarly, experimentation with off-the-shelf de-identification systems reveals potential risks associated with the approach. To overcome data scarcity, we explore generating synthetic clinical reports (using publicly available and Indian summaries) by performing in-context learning over Large Language Models (LLMs). Our experiments demonstrate the use of generated reports as an effective strategy for creating high-performing de-identification systems with good generalization capabilities.
Probing the Limits and Capabilities of Diffusion Models for the Anatomic Editing of Digital Twins
Dec 30, 2023Numerical simulations can model the physical processes that govern cardiovascular device deployment. When such simulations incorporate digital twins; computational models of patient-specific anatomy, they can expedite and de-risk the device design process. Nonetheless, the exclusive use of patient-specific data constrains the anatomic variability which can be precisely or fully explored. In this study, we investigate the capacity of Latent Diffusion Models (LDMs) to edit digital twins to create anatomic variants, which we term digital siblings. Digital twins and their corresponding siblings can serve as the basis for comparative simulations, enabling the study of how subtle anatomic variations impact the simulated deployment of cardiovascular devices, as well as the augmentation of virtual cohorts for device assessment. However, while diffusion models have been characterized in their ability to edit natural images, their capacity to anatomically edit digital twins has yet to be studied. Using a case example centered on 3D digital twins of cardiac anatomy, we implement various methods for generating digital siblings and characterize them through morphological and topological analyses. We specifically edit digital twins to introduce anatomic variation at different spatial scales and within localized regions, demonstrating the existence of bias towards common anatomic features. We further show that such anatomic bias can be leveraged for virtual cohort augmentation through selective editing, partially alleviating issues related to dataset imbalance and lack of diversity. Our experimental framework thus delineates the limits and capabilities of using latent diffusion models in synthesizing anatomic variation for in silico trials.
NOIR: Neural Signal Operated Intelligent Robots for Everyday Activities
Nov 02, 2023



We present Neural Signal Operated Intelligent Robots (NOIR), a general-purpose, intelligent brain-robot interface system that enables humans to command robots to perform everyday activities through brain signals. Through this interface, humans communicate their intended objects of interest and actions to the robots using electroencephalography (EEG). Our novel system demonstrates success in an expansive array of 20 challenging, everyday household activities, including cooking, cleaning, personal care, and entertainment. The effectiveness of the system is improved by its synergistic integration of robot learning algorithms, allowing for NOIR to adapt to individual users and predict their intentions. Our work enhances the way humans interact with robots, replacing traditional channels of interaction with direct, neural communication. Project website: https://noir-corl.github.io/.
LESA: Linguistic Encapsulation and Semantic Amalgamation Based Generalised Claim Detection from Online Content
Jan 28, 2021
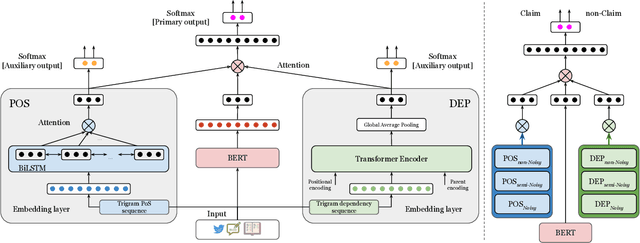
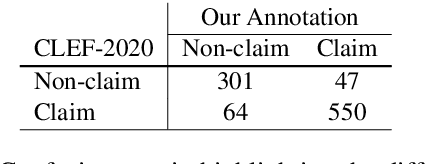

The conceptualization of a claim lies at the core of argument mining. The segregation of claims is complex, owing to the divergence in textual syntax and context across different distributions. Another pressing issue is the unavailability of labeled unstructured text for experimentation. In this paper, we propose LESA, a framework which aims at advancing headfirst into expunging the former issue by assembling a source-independent generalized model that captures syntactic features through part-of-speech and dependency embeddings, as well as contextual features through a fine-tuned language model. We resolve the latter issue by annotating a Twitter dataset which aims at providing a testing ground on a large unstructured dataset. Experimental results show that LESA improves upon the state-of-the-art performance across six benchmark claim datasets by an average of 3 claim-F1 points for in-domain experiments and by 2 claim-F1 points for general-domain experiments. On our dataset too, LESA outperforms existing baselines by 1 claim-F1 point on the in-domain experiments and 2 claim-F1 points on the general-domain experiments. We also release comprehensive data annotation guidelines compiled during the annotation phase (which was missing in the current literature).