 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022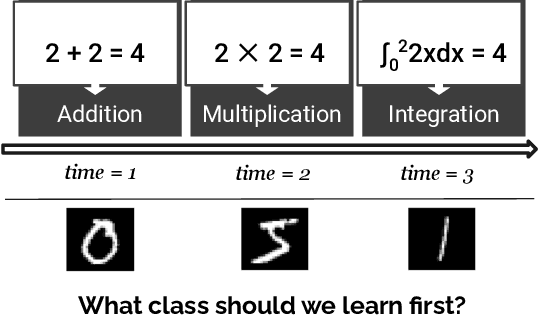
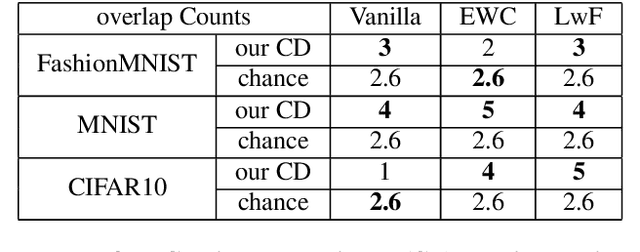
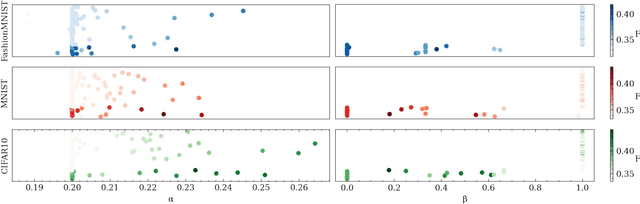
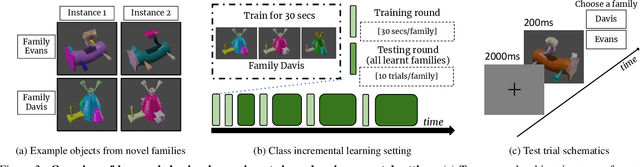
Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.
DESYR: Definition and Syntactic Representation Based Claim Detection on the Web
Aug 19, 2021
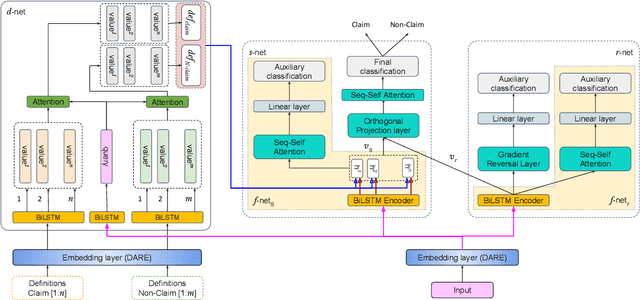
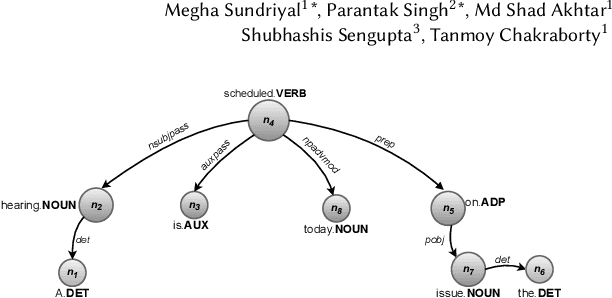

The formulation of a claim rests at the core of argument mining. To demarcate between a claim and a non-claim is arduous for both humans and machines, owing to latent linguistic variance between the two and the inadequacy of extensive definition-based formalization. Furthermore, the increase in the usage of online social media has resulted in an explosion of unsolicited information on the web presented as informal text. To account for the aforementioned, in this paper, we proposed DESYR. It is a framework that intends on annulling the said issues for informal web-based text by leveraging a combination of hierarchical representation learning (dependency-inspired Poincare embedding), definition-based alignment, and feature projection. We do away with fine-tuning computer-heavy language models in favor of fabricating a more domain-centric but lighter approach. Experimental results indicate that DESYR builds upon the state-of-the-art system across four benchmark claim datasets, most of which were constructed with informal texts. We see an increase of 3 claim-F1 points on the LESA-Twitter dataset, an increase of 1 claim-F1 point and 9 macro-F1 points on the Online Comments(OC) dataset, an increase of 24 claim-F1 points and 17 macro-F1 points on the Web Discourse(WD) dataset, and an increase of 8 claim-F1 points and 5 macro-F1 points on the Micro Texts(MT) dataset. We also perform an extensive analysis of the results. We make a 100-D pre-trained version of our Poincare-variant along with the source code.
LESA: Linguistic Encapsulation and Semantic Amalgamation Based Generalised Claim Detection from Online Content
Jan 28, 2021
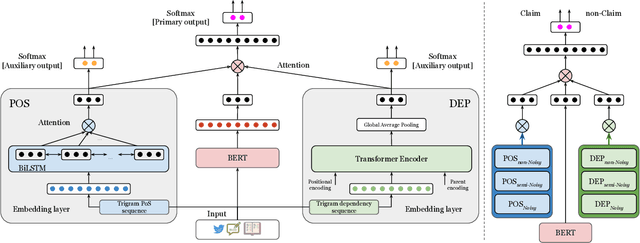
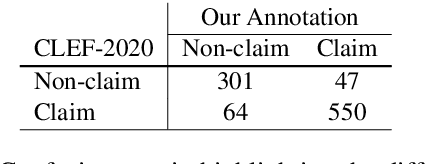

The conceptualization of a claim lies at the core of argument mining. The segregation of claims is complex, owing to the divergence in textual syntax and context across different distributions. Another pressing issue is the unavailability of labeled unstructured text for experimentation. In this paper, we propose LESA, a framework which aims at advancing headfirst into expunging the former issue by assembling a source-independent generalized model that captures syntactic features through part-of-speech and dependency embeddings, as well as contextual features through a fine-tuned language model. We resolve the latter issue by annotating a Twitter dataset which aims at providing a testing ground on a large unstructured dataset. Experimental results show that LESA improves upon the state-of-the-art performance across six benchmark claim datasets by an average of 3 claim-F1 points for in-domain experiments and by 2 claim-F1 points for general-domain experiments. On our dataset too, LESA outperforms existing baselines by 1 claim-F1 point on the in-domain experiments and 2 claim-F1 points on the general-domain experiments. We also release comprehensive data annotation guidelines compiled during the annotation phase (which was missing in the current literature).