 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Psychology of Falsehood: A Human-Centric Survey of Misinformation Detection
Sep 19, 2025Misinformation remains one of the most significant issues in the digital age. While automated fact-checking has emerged as a viable solution, most current systems are limited to evaluating factual accuracy. However, the detrimental effect of misinformation transcends simple falsehoods; it takes advantage of how individuals perceive, interpret, and emotionally react to information. This underscores the need to move beyond factuality and adopt more human-centered detection frameworks. In this survey, we explore the evolving interplay between traditional fact-checking approaches and psychological concepts such as cognitive biases, social dynamics, and emotional responses. By analyzing state-of-the-art misinformation detection systems through the lens of human psychology and behavior, we reveal critical limitations of current methods and identify opportunities for improvement. Additionally, we outline future research directions aimed at creating more robust and adaptive frameworks, such as neuro-behavioural models that integrate technological factors with the complexities of human cognition and social influence. These approaches offer promising pathways to more effectively detect and mitigate the societal harms of misinformation.
The CLEF-2025 CheckThat! Lab: Subjectivity, Fact-Checking, Claim Normalization, and Retrieval
Mar 19, 2025The CheckThat! lab aims to advance the development of innovative technologies designed to identify and counteract online disinformation and manipulation efforts across various languages and platforms. The first five editions focused on key tasks in the information verification pipeline, including check-worthiness, evidence retrieval and pairing, and verification. Since the 2023 edition, the lab has expanded its scope to address auxiliary tasks that support research and decision-making in verification. In the 2025 edition, the lab revisits core verification tasks while also considering auxiliary challenges. Task 1 focuses on the identification of subjectivity (a follow-up from CheckThat! 2024), Task 2 addresses claim normalization, Task 3 targets fact-checking numerical claims, and Task 4 explores scientific web discourse processing. These tasks present challenging classification and retrieval problems at both the document and span levels, including multilingual settings.
Crowd Intelligence for Early Misinformation Prediction on Social Media
Aug 08, 2024



Misinformation spreads rapidly on social media, causing serious damage by influencing public opinion, promoting dangerous behavior, or eroding trust in reliable sources. It spreads too fast for traditional fact-checking, stressing the need for predictive methods. We introduce CROWDSHIELD, a crowd intelligence-based method for early misinformation prediction. We hypothesize that the crowd's reactions to misinformation reveal its accuracy. Furthermore, we hinge upon exaggerated assertions/claims and replies with particular positions/stances on the source post within a conversation thread. We employ Q-learning to capture the two dimensions -- stances and claims. We utilize deep Q-learning due to its proficiency in navigating complex decision spaces and effectively learning network properties. Additionally, we use a transformer-based encoder to develop a comprehensive understanding of both content and context. This multifaceted approach helps ensure the model pays attention to user interaction and stays anchored in the communication's content. We propose MIST, a manually annotated misinformation detection Twitter corpus comprising nearly 200 conversation threads with more than 14K replies. In experiments, CROWDSHIELD outperformed ten baseline systems, achieving an improvement of ~4% macro-F1 score. We conduct an ablation study and error analysis to validate our proposed model's performance. The source code and dataset are available at https://github.com/LCS2-IIITD/CrowdShield.git.
Overview of the CLAIMSCAN-2023: Uncovering Truth in Social Media through Claim Detection and Identification of Claim Spans
Oct 30, 2023



A significant increase in content creation and information exchange has been made possible by the quick development of online social media platforms, which has been very advantageous. However, these platforms have also become a haven for those who disseminate false information, propaganda, and fake news. Claims are essential in forming our perceptions of the world, but sadly, they are frequently used to trick people by those who spread false information. To address this problem, social media giants employ content moderators to filter out fake news from the actual world. However, the sheer volume of information makes it difficult to identify fake news effectively. Therefore, it has become crucial to automatically identify social media posts that make such claims, check their veracity, and differentiate between credible and false claims. In response, we presented CLAIMSCAN in the 2023 Forum for Information Retrieval Evaluation (FIRE'2023). The primary objectives centered on two crucial tasks: Task A, determining whether a social media post constitutes a claim, and Task B, precisely identifying the words or phrases within the post that form the claim. Task A received 40 registrations, demonstrating a strong interest and engagement in this timely challenge. Meanwhile, Task B attracted participation from 28 teams, highlighting its significance in the digital era of misinformation.
Lost in Translation, Found in Spans: Identifying Claims in Multilingual Social Media
Oct 27, 2023
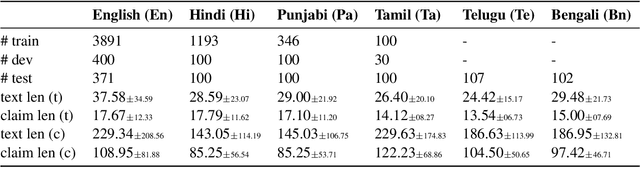
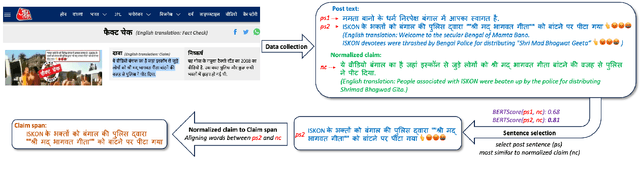
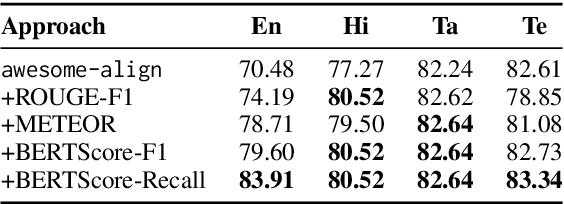
Claim span identification (CSI) is an important step in fact-checking pipelines, aiming to identify text segments that contain a checkworthy claim or assertion in a social media post. Despite its importance to journalists and human fact-checkers, it remains a severely understudied problem, and the scarce research on this topic so far has only focused on English. Here we aim to bridge this gap by creating a novel dataset, X-CLAIM, consisting of 7K real-world claims collected from numerous social media platforms in five Indian languages and English. We report strong baselines with state-of-the-art encoder-only language models (e.g., XLM-R) and we demonstrate the benefits of training on multiple languages over alternative cross-lingual transfer methods such as zero-shot transfer, or training on translated data, from a high-resource language such as English. We evaluate generative large language models from the GPT series using prompting methods on the X-CLAIM dataset and we find that they underperform the smaller encoder-only language models for low-resource languages.
From Chaos to Clarity: Claim Normalization to Empower Fact-Checking
Oct 22, 2023



With the proliferation of social media platforms, users are exposed to vast information, including posts containing misleading claims. However, the pervasive noise inherent in these posts presents a challenge in identifying precise and prominent claims that require verification. Extracting the core assertions from such posts is arduous and time-consuming. We introduce a novel task called Claim Normalization (aka ClaimNorm) that aims to decompose complex and noisy social media posts into more straightforward and understandable forms, termed normalized claims. We propose CACN, a pioneering approach that leverages chain-of-thought and claim check-worthiness estimation, mimicking human reasoning processes, to comprehend intricate claims. Moreover, we capitalize on large language models' powerful in-context learning abilities to provide guidance and improve the claim normalization process. To evaluate the effectiveness of our proposed model, we meticulously compile a comprehensive real-world dataset, CLAN, comprising more than 6k instances of social media posts alongside their respective normalized claims. Experimentation demonstrates that CACN outperforms several baselines across various evaluation measures. A rigorous error analysis validates CACN's capabilities and pitfalls.
Leveraging Social Discourse to Measure Check-worthiness of Claims for Fact-checking
Sep 17, 2023



The expansion of online social media platforms has led to a surge in online content consumption. However, this has also paved the way for disseminating false claims and misinformation. As a result, there is an escalating demand for a substantial workforce to sift through and validate such unverified claims. Currently, these claims are manually verified by fact-checkers. Still, the volume of online content often outweighs their potency, making it difficult for them to validate every single claim in a timely manner. Thus, it is critical to determine which assertions are worth fact-checking and prioritize claims that require immediate attention. Multiple factors contribute to determining whether a claim necessitates fact-checking, encompassing factors such as its factual correctness, potential impact on the public, the probability of inciting hatred, and more. Despite several efforts to address claim check-worthiness, a systematic approach to identify these factors remains an open challenge. To this end, we introduce a new task of fine-grained claim check-worthiness, which underpins all of these factors and provides probable human grounds for identifying a claim as check-worthy. We present CheckIt, a manually annotated large Twitter dataset for fine-grained claim check-worthiness. We benchmark our dataset against a unified approach, CheckMate, that jointly determines whether a claim is check-worthy and the factors that led to that conclusion. We compare our suggested system with several baseline systems. Finally, we report a thorough analysis of results and human assessment, validating the efficacy of integrating check-worthiness factors in detecting claims worth fact-checking.
Empowering the Fact-checkers! Automatic Identification of Claim Spans on Twitter
Oct 11, 2022
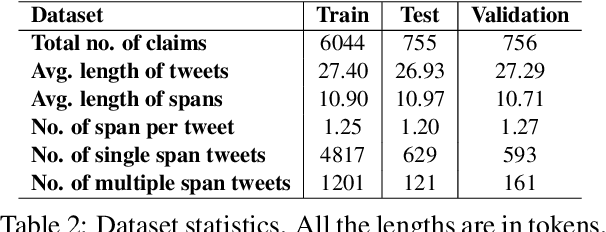
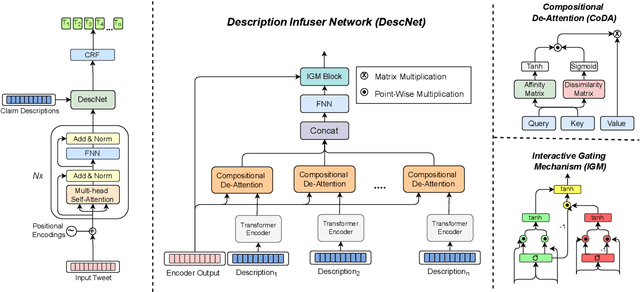
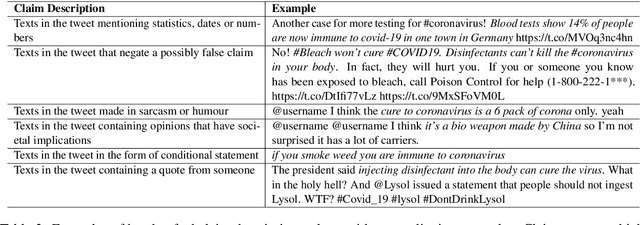
The widespread diffusion of medical and political claims in the wake of COVID-19 has led to a voluminous rise in misinformation and fake news. The current vogue is to employ manual fact-checkers to efficiently classify and verify such data to combat this avalanche of claim-ridden misinformation. However, the rate of information dissemination is such that it vastly outpaces the fact-checkers' strength. Therefore, to aid manual fact-checkers in eliminating the superfluous content, it becomes imperative to automatically identify and extract the snippets of claim-worthy (mis)information present in a post. In this work, we introduce the novel task of Claim Span Identification (CSI). We propose CURT, a large-scale Twitter corpus with token-level claim spans on more than 7.5k tweets. Furthermore, along with the standard token classification baselines, we benchmark our dataset with DABERTa, an adapter-based variation of RoBERTa. The experimental results attest that DABERTa outperforms the baseline systems across several evaluation metrics, improving by about 1.5 points. We also report detailed error analysis to validate the model's performance along with the ablation studies. Lastly, we release our comprehensive span annotation guidelines for public use.
DESYR: Definition and Syntactic Representation Based Claim Detection on the Web
Aug 19, 2021
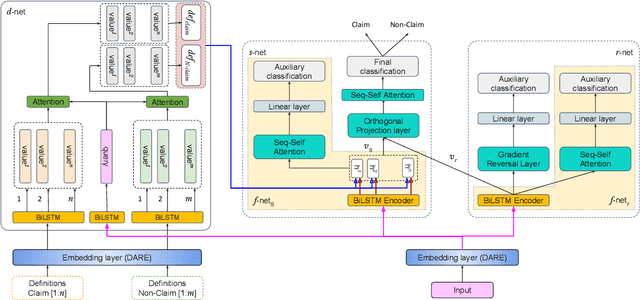
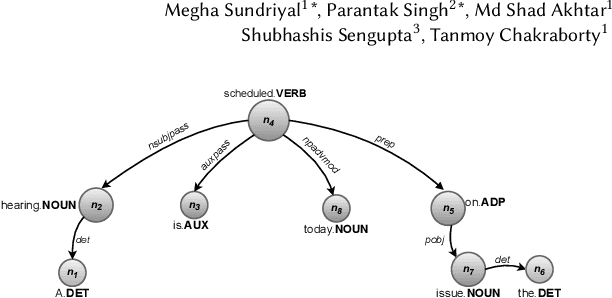

The formulation of a claim rests at the core of argument mining. To demarcate between a claim and a non-claim is arduous for both humans and machines, owing to latent linguistic variance between the two and the inadequacy of extensive definition-based formalization. Furthermore, the increase in the usage of online social media has resulted in an explosion of unsolicited information on the web presented as informal text. To account for the aforementioned, in this paper, we proposed DESYR. It is a framework that intends on annulling the said issues for informal web-based text by leveraging a combination of hierarchical representation learning (dependency-inspired Poincare embedding), definition-based alignment, and feature projection. We do away with fine-tuning computer-heavy language models in favor of fabricating a more domain-centric but lighter approach. Experimental results indicate that DESYR builds upon the state-of-the-art system across four benchmark claim datasets, most of which were constructed with informal texts. We see an increase of 3 claim-F1 points on the LESA-Twitter dataset, an increase of 1 claim-F1 point and 9 macro-F1 points on the Online Comments(OC) dataset, an increase of 24 claim-F1 points and 17 macro-F1 points on the Web Discourse(WD) dataset, and an increase of 8 claim-F1 points and 5 macro-F1 points on the Micro Texts(MT) dataset. We also perform an extensive analysis of the results. We make a 100-D pre-trained version of our Poincare-variant along with the source code.
LESA: Linguistic Encapsulation and Semantic Amalgamation Based Generalised Claim Detection from Online Content
Jan 28, 2021
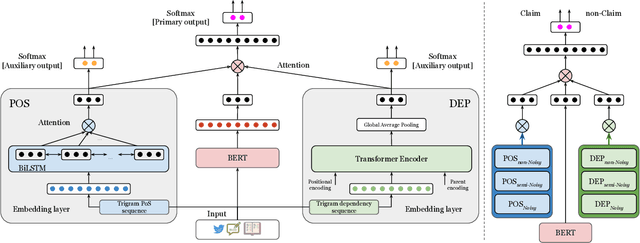
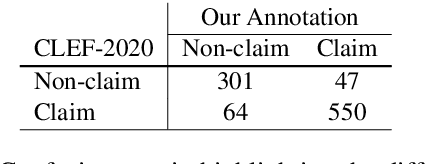

The conceptualization of a claim lies at the core of argument mining. The segregation of claims is complex, owing to the divergence in textual syntax and context across different distributions. Another pressing issue is the unavailability of labeled unstructured text for experimentation. In this paper, we propose LESA, a framework which aims at advancing headfirst into expunging the former issue by assembling a source-independent generalized model that captures syntactic features through part-of-speech and dependency embeddings, as well as contextual features through a fine-tuned language model. We resolve the latter issue by annotating a Twitter dataset which aims at providing a testing ground on a large unstructured dataset. Experimental results show that LESA improves upon the state-of-the-art performance across six benchmark claim datasets by an average of 3 claim-F1 points for in-domain experiments and by 2 claim-F1 points for general-domain experiments. On our dataset too, LESA outperforms existing baselines by 1 claim-F1 point on the in-domain experiments and 2 claim-F1 points on the general-domain experiments. We also release comprehensive data annotation guidelines compiled during the annotation phase (which was missing in the current literature).