 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation, Found in Spans: Identifying Claims in Multilingual Social Media
Oct 27, 2023
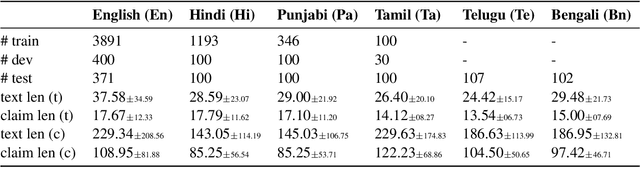
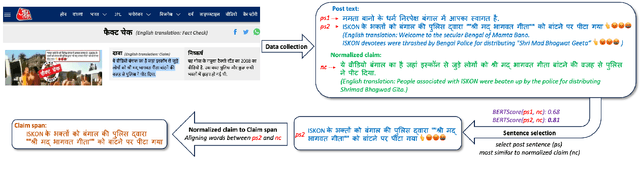
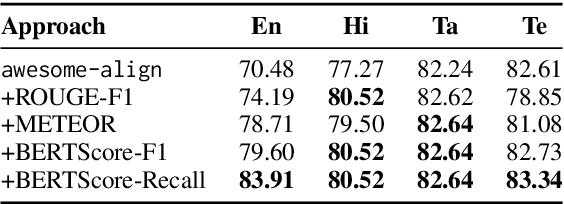
Claim span identification (CSI) is an important step in fact-checking pipelines, aiming to identify text segments that contain a checkworthy claim or assertion in a social media post. Despite its importance to journalists and human fact-checkers, it remains a severely understudied problem, and the scarce research on this topic so far has only focused on English. Here we aim to bridge this gap by creating a novel dataset, X-CLAIM, consisting of 7K real-world claims collected from numerous social media platforms in five Indian languages and English. We report strong baselines with state-of-the-art encoder-only language models (e.g., XLM-R) and we demonstrate the benefits of training on multiple languages over alternative cross-lingual transfer methods such as zero-shot transfer, or training on translated data, from a high-resource language such as English. We evaluate generative large language models from the GPT series using prompting methods on the X-CLAIM dataset and we find that they underperform the smaller encoder-only language models for low-resource languages.
mOKB6: A Multilingual Open Knowledge Base Completion Benchmark
Nov 13, 2022Automated completion of open knowledge bases (KBs), which are constructed from triples of the form (subject phrase, relation phrase, object phrase) obtained via open information extraction (IE) from text, is useful for discovering novel facts that may not directly be present in the text. However, research in open knowledge base completion (KBC) has so far been limited to resource-rich languages like English. Using the latest advances in multilingual open IE, we construct the first multilingual open KBC dataset, called mOKB6, that contains facts from Wikipedia in six languages (including English). Improving the previous open KB construction pipeline by doing multilingual coreference resolution and keeping only entity-linked triples, we create a dense open KB. We experiment with several baseline models that have been proposed for both open and closed KBs and observe a consistent benefit of using knowledge gained from other languages. The dataset and accompanying code will be made publicly available.
IITD at the WANLP 2022 Shared Task: Multilingual Multi-Granularity Network for Propaganda Detection
Oct 31, 2022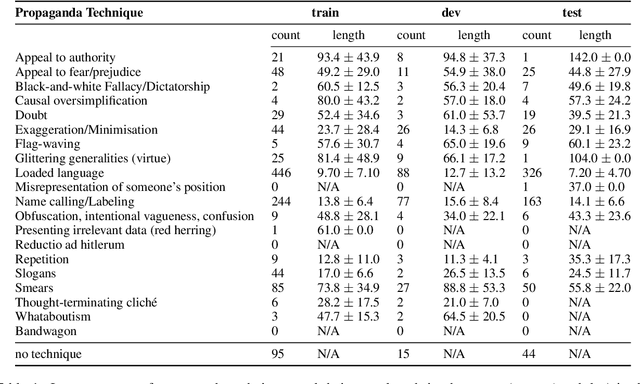
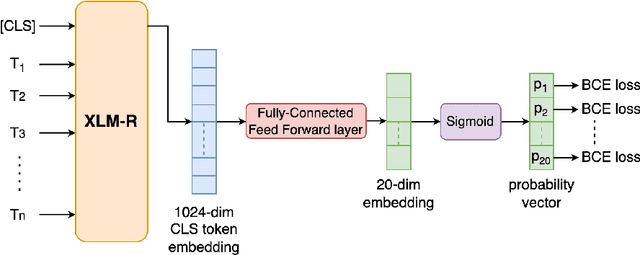
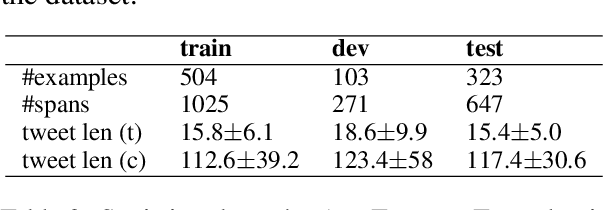
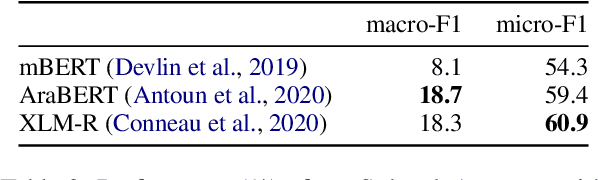
We present our system for the two subtasks of the shared task on propaganda detection in Arabic, part of WANLP'2022. Subtask 1 is a multi-label classification problem to find the propaganda techniques used in a given tweet. Our system for this task uses XLM-R to predict probabilities for the target tweet to use each of the techniques. In addition to finding the techniques, Subtask 2 further asks to identify the textual span for each instance of each technique that is present in the tweet; the task can be modeled as a sequence tagging problem. We use a multi-granularity network with mBERT encoder for Subtask 2. Overall, our system ranks second for both subtasks (out of 14 and 3 participants, respectively). Our empirical analysis show that it does not help to use a much larger English corpus annotated with propaganda techniques, regardless of whether used in English or after translation to Arabic.