 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGMol: Target-Aware Gradient-guided Molecule Generation
Jun 03, 2024



3D generative models have shown significant promise in structure-based drug design (SBDD), particularly in discovering ligands tailored to specific target binding sites. Existing algorithms often focus primarily on ligand-target binding, characterized by binding affinity. Moreover, models trained solely on target-ligand distribution may fall short in addressing the broader objectives of drug discovery, such as the development of novel ligands with desired properties like drug-likeness, and synthesizability, underscoring the multifaceted nature of the drug design process. To overcome these challenges, we decouple the problem into molecular generation and property prediction. The latter synergistically guides the diffusion sampling process, facilitating guided diffusion and resulting in the creation of meaningful molecules with the desired properties. We call this guided molecular generation process as TAGMol. Through experiments on benchmark datasets, TAGMol demonstrates superior performance compared to state-of-the-art baselines, achieving a 22% improvement in average Vina Score and yielding favorable outcomes in essential auxiliary properties. This establishes TAGMol as a comprehensive framework for drug generation.
GenToC: Leveraging Partially-Labeled Data for Product Attribute-Value Identification
May 17, 2024



In the e-commerce domain, the accurate extraction of attribute-value pairs from product listings (e.g., Brand: Apple) is crucial for enhancing search and recommendation systems. The automation of this extraction process is challenging due to the vast diversity of product categories and their respective attributes, compounded by the lack of extensive, accurately annotated training datasets and the demand for low latency to meet the real-time needs of e-commerce platforms. To address these challenges, we introduce GenToC, a novel two-stage model for extracting attribute-value pairs from product titles. GenToC is designed to train with partially-labeled data, leveraging incomplete attribute-value pairs and obviating the need for a fully annotated dataset. Moreover, we introduce a bootstrapping method that enables GenToC to progressively refine and expand its training dataset. This enhancement substantially improves the quality of data available for training other neural network models that are typically faster but are inherently less capable than GenToC in terms of their capacity to handle partially-labeled data. By supplying an enriched dataset for training, GenToC significantly advances the performance of these alternative models, making them more suitable for real-time deployment. Our results highlight the unique capability of GenToC to learn from a limited set of labeled data and to contribute to the training of more efficient models, marking a significant leap forward in the automated extraction of attribute-value pairs from product titles. GenToC has been successfully integrated into India's largest B2B e-commerce platform, IndiaMART.com, achieving a significant increase of 21.1% in recall over the existing deployed system while maintaining a high precision of 89.5% in this challenging task.
mOKB6: A Multilingual Open Knowledge Base Completion Benchmark
Nov 13, 2022Automated completion of open knowledge bases (KBs), which are constructed from triples of the form (subject phrase, relation phrase, object phrase) obtained via open information extraction (IE) from text, is useful for discovering novel facts that may not directly be present in the text. However, research in open knowledge base completion (KBC) has so far been limited to resource-rich languages like English. Using the latest advances in multilingual open IE, we construct the first multilingual open KBC dataset, called mOKB6, that contains facts from Wikipedia in six languages (including English). Improving the previous open KB construction pipeline by doing multilingual coreference resolution and keeping only entity-linked triples, we create a dense open KB. We experiment with several baseline models that have been proposed for both open and closed KBs and observe a consistent benefit of using knowledge gained from other languages. The dataset and accompanying code will be made publicly available.
"Covid vaccine is against Covid but Oxford vaccine is made at Oxford!" Semantic Interpretation of Proper Noun Compounds
Oct 24, 2022Proper noun compounds, e.g., "Covid vaccine", convey information in a succinct manner (a "Covid vaccine" is a "vaccine that immunizes against the Covid disease"). These are commonly used in short-form domains, such as news headlines, but are largely ignored in information-seeking applications. To address this limitation, we release a new manually annotated dataset, ProNCI, consisting of 22.5K proper noun compounds along with their free-form semantic interpretations. ProNCI is 60 times larger than prior noun compound datasets and also includes non-compositional examples, which have not been previously explored. We experiment with various neural models for automatically generating the semantic interpretations from proper noun compounds, ranging from few-shot prompting to supervised learning, with varying degrees of knowledge about the constituent nouns. We find that adding targeted knowledge, particularly about the common noun, results in performance gains of upto 2.8%. Finally, we integrate our model generated interpretations with an existing Open IE system and observe an 7.5% increase in yield at a precision of 85%. The dataset and code are available at https://github.com/dair-iitd/pronci.
Multilingual Fact Linking
Oct 01, 2021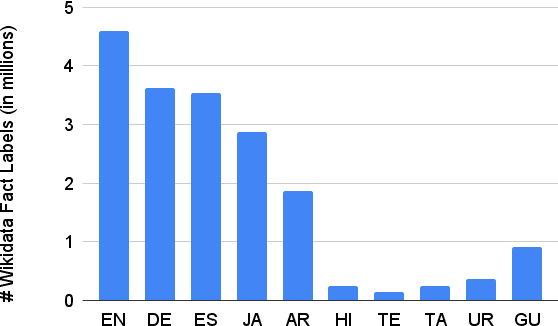
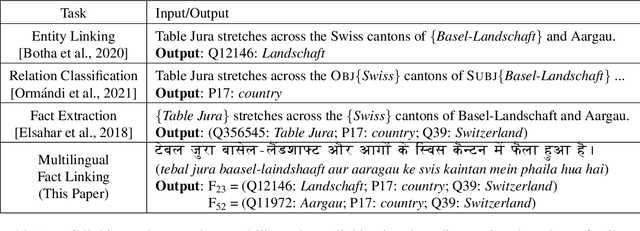

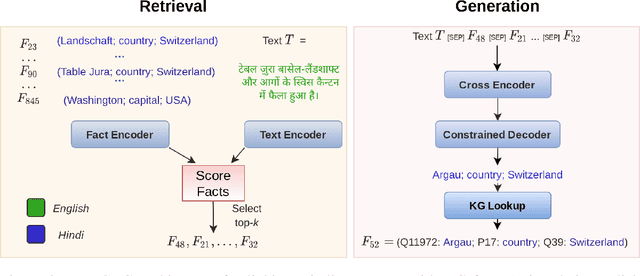
Knowledge-intensive NLP tasks can benefit from linking natural language text with facts from a Knowledge Graph (KG). Although facts themselves are language-agnostic, the fact labels (i.e., language-specific representation of the fact) in the KG are often present only in a few languages. This makes it challenging to link KG facts to sentences in languages other than the limited set of languages. To address this problem, we introduce the task of Multilingual Fact Linking (MFL) where the goal is to link fact expressed in a sentence to corresponding fact in the KG, even when the fact label in the KG is not available in the language of the sentence. To facilitate research in this area, we present a new evaluation dataset, IndicLink. This dataset contains 11,293 linked WikiData facts and 6,429 sentences spanning English and six Indian languages. We propose a Retrieval+Generation model, ReFCoG, that can scale to millions of KG facts by combining Dual Encoder based retrieval with a Seq2Seq based generation model which is constrained to output only valid KG facts. ReFCoG outperforms standard Retrieval+Re-ranking models by 10.7 pts in Precision@1. In spite of this gain, the model achieves an overall score of 52.1, showing ample scope for improvement in the task.ReFCoG code and IndicLink data are available at https://github.com/SaiKeshav/mfl
CEAR: Cross-Entity Aware Reranker for Knowledge Base Completion
Apr 18, 2021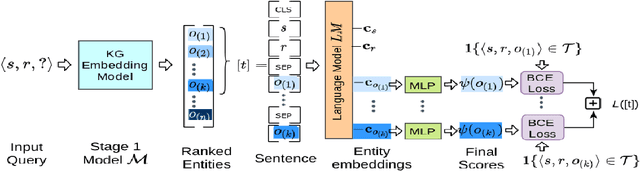
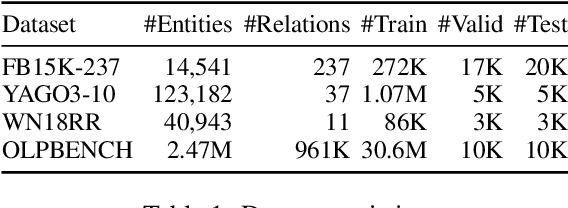
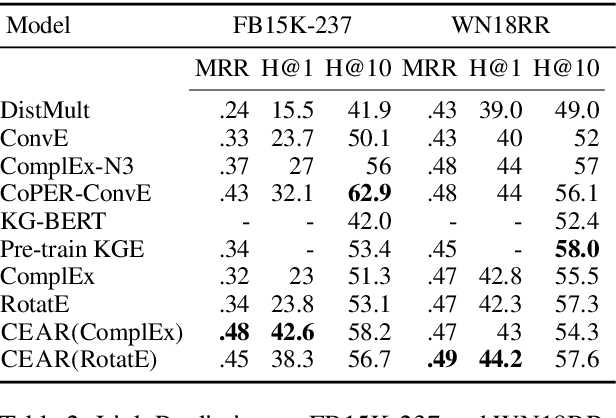

Pre-trained language models (LMs) like BERT have shown to store factual knowledge about the world. This knowledge can be used to augment the information present in Knowledge Bases, which tend to be incomplete. However, prior attempts at using BERT for task of Knowledge Base Completion (KBC) resulted in performance worse than embedding based techniques that rely only on the graph structure. In this work we develop a novel model, Cross-Entity Aware Reranker (CEAR), that uses BERT to re-rank the output of existing KBC models with cross-entity attention. Unlike prior work that scores each entity independently, CEAR uses BERT to score the entities together, which is effective for exploiting its factual knowledge. CEAR establishes a new state of the art performance with 42.6 HITS@1 in FB15k-237 (32.7% relative improvement) and 5.3 pt improvement in HITS@1 for Open Link Prediction.
OpenIE6: Iterative Grid Labeling and Coordination Analysis for Open Information Extraction
Oct 07, 2020

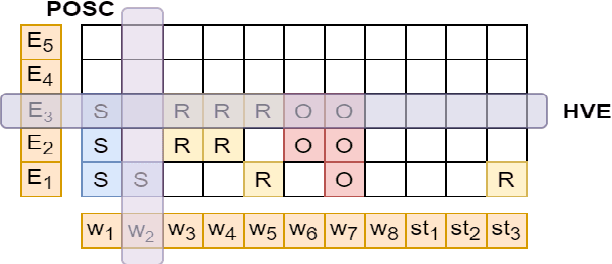
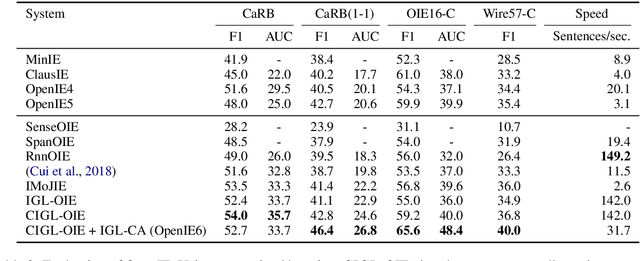
A recent state-of-the-art neural open information extraction (OpenIE) system generates extractions iteratively, requiring repeated encoding of partial outputs. This comes at a significant computational cost. On the other hand, sequence labeling approaches for OpenIE are much faster, but worse in extraction quality. In this paper, we bridge this trade-off by presenting an iterative labeling-based system that establishes a new state of the art for OpenIE, while extracting 10x faster. This is achieved through a novel Iterative Grid Labeling (IGL) architecture, which treats OpenIE as a 2-D grid labeling task. We improve its performance further by applying coverage (soft) constraints on the grid at training time. Moreover, on observing that the best OpenIE systems falter at handling coordination structures, our OpenIE system also incorporates a new coordination analyzer built with the same IGL architecture. This IGL based coordination analyzer helps our OpenIE system handle complicated coordination structures, while also establishing a new state of the art on the task of coordination analysis, with a 12.3 pts improvement in F1 over previous analyzers. Our OpenIE system, OpenIE6, beats the previous systems by as much as 4 pts in F1, while being much faster.
IMoJIE: Iterative Memory-Based Joint Open Information Extraction
May 17, 2020
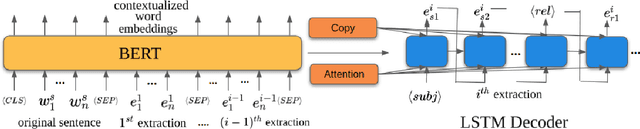


While traditional systems for Open Information Extraction were statistical and rule-based, recently neural models have been introduced for the task. Our work builds upon CopyAttention, a sequence generation OpenIE model (Cui et. al., 2018). Our analysis reveals that CopyAttention produces a constant number of extractions per sentence, and its extracted tuples often express redundant information. We present IMoJIE, an extension to CopyAttention, which produces the next extraction conditioned on all previously extracted tuples. This approach overcomes both shortcomings of CopyAttention, resulting in a variable number of diverse extractions per sentence. We train IMoJIE on training data bootstrapped from extractions of several non-neural systems, which have been automatically filtered to reduce redundancy and noise. IMoJIE outperforms CopyAttention by about 18 F1 pts, and a BERT-based strong baseline by 2 F1 pts, establishing a new state of the art for the task.
Why and when should you pool? Analyzing Pooling in Recurrent Architectures
May 01, 2020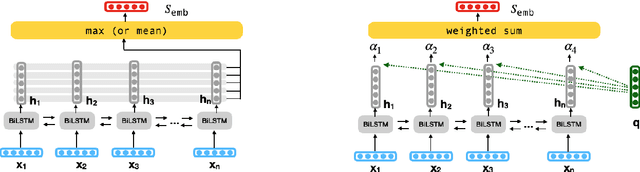
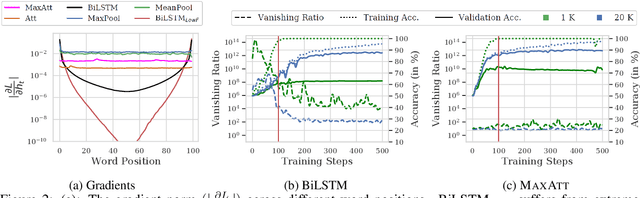

Pooling-based recurrent neural architectures consistently outperform their counterparts without pooling. However, the reasons for their enhanced performance are largely unexamined. In this work, we examine three commonly used pooling techniques (mean-pooling, max-pooling, and attention), and propose max-attention, a novel variant that effectively captures interactions among predictive tokens in a sentence. We find that pooling-based architectures substantially differ from their non-pooling equivalents in their learning ability and positional biases--which elucidate their performance benefits. By analyzing the gradient propagation, we discover that pooling facilitates better gradient flow compared to BiLSTMs. Further, we expose how BiLSTMs are positionally biased towards tokens in the beginning and the end of a sequence. Pooling alleviates such biases. Consequently, we identify settings where pooling offers large benefits: (i) in low resource scenarios, and (ii) when important words lie towards the middle of the sentence. Among the pooling techniques studied, max-attention is the most effective, resulting in significant performance gains on several text classification tasks.