 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy and when should you pool? Analyzing Pooling in Recurrent Architectures
Paper and Code
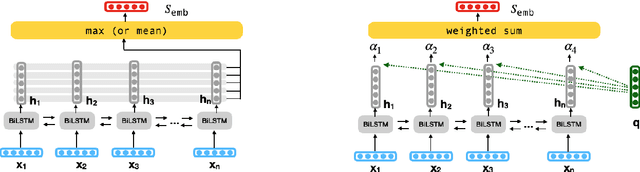
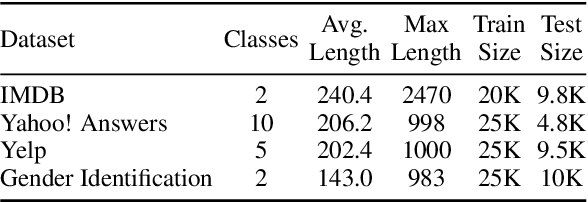
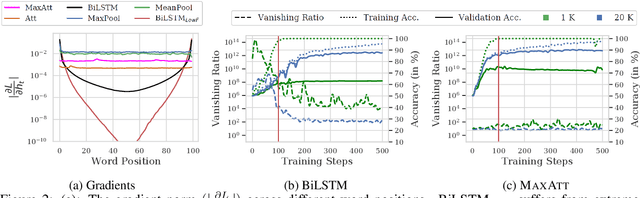

Pooling-based recurrent neural architectures consistently outperform their counterparts without pooling. However, the reasons for their enhanced performance are largely unexamined. In this work, we examine three commonly used pooling techniques (mean-pooling, max-pooling, and attention), and propose max-attention, a novel variant that effectively captures interactions among predictive tokens in a sentence. We find that pooling-based architectures substantially differ from their non-pooling equivalents in their learning ability and positional biases--which elucidate their performance benefits. By analyzing the gradient propagation, we discover that pooling facilitates better gradient flow compared to BiLSTMs. Further, we expose how BiLSTMs are positionally biased towards tokens in the beginning and the end of a sequence. Pooling alleviates such biases. Consequently, we identify settings where pooling offers large benefits: (i) in low resource scenarios, and (ii) when important words lie towards the middle of the sentence. Among the pooling techniques studied, max-attention is the most effective, resulting in significant performance gains on several text classification tasks.