 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Fact Linking
Oct 01, 2021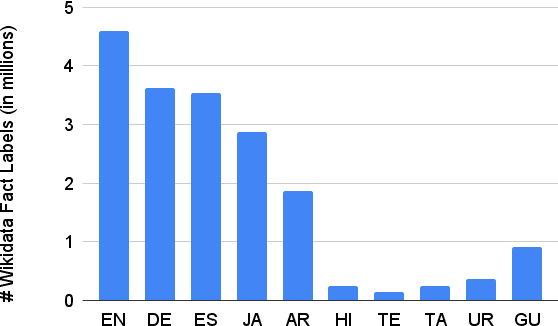
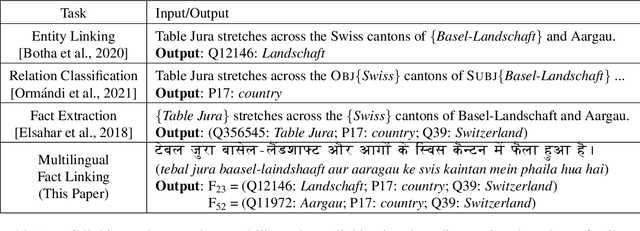

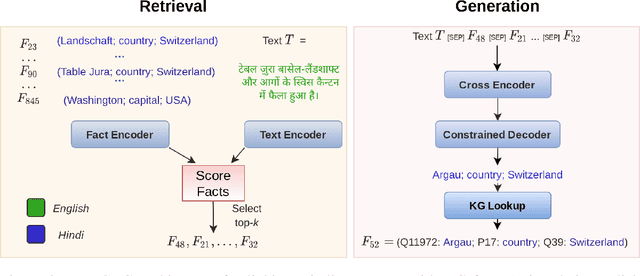
Knowledge-intensive NLP tasks can benefit from linking natural language text with facts from a Knowledge Graph (KG). Although facts themselves are language-agnostic, the fact labels (i.e., language-specific representation of the fact) in the KG are often present only in a few languages. This makes it challenging to link KG facts to sentences in languages other than the limited set of languages. To address this problem, we introduce the task of Multilingual Fact Linking (MFL) where the goal is to link fact expressed in a sentence to corresponding fact in the KG, even when the fact label in the KG is not available in the language of the sentence. To facilitate research in this area, we present a new evaluation dataset, IndicLink. This dataset contains 11,293 linked WikiData facts and 6,429 sentences spanning English and six Indian languages. We propose a Retrieval+Generation model, ReFCoG, that can scale to millions of KG facts by combining Dual Encoder based retrieval with a Seq2Seq based generation model which is constrained to output only valid KG facts. ReFCoG outperforms standard Retrieval+Re-ranking models by 10.7 pts in Precision@1. In spite of this gain, the model achieves an overall score of 52.1, showing ample scope for improvement in the task.ReFCoG code and IndicLink data are available at https://github.com/SaiKeshav/mfl
OBDA Constraints for Effective Query Answering (Extended Version)
May 16, 2016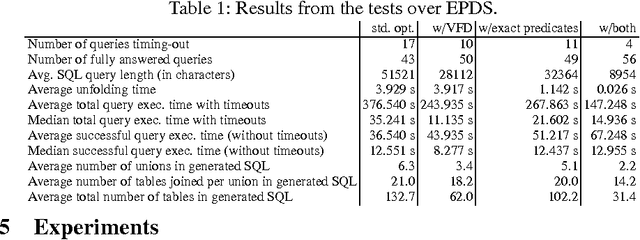
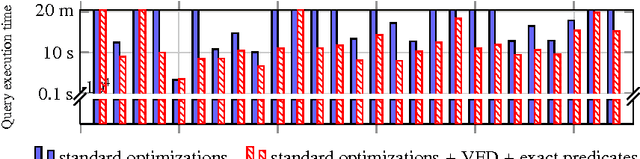
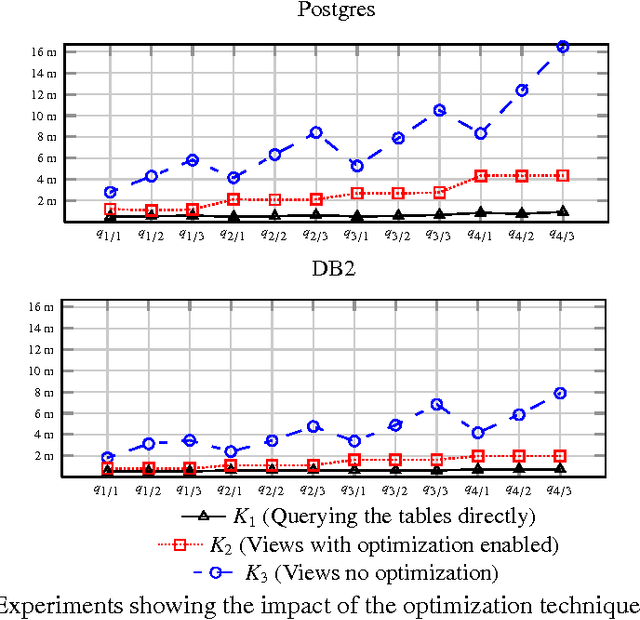
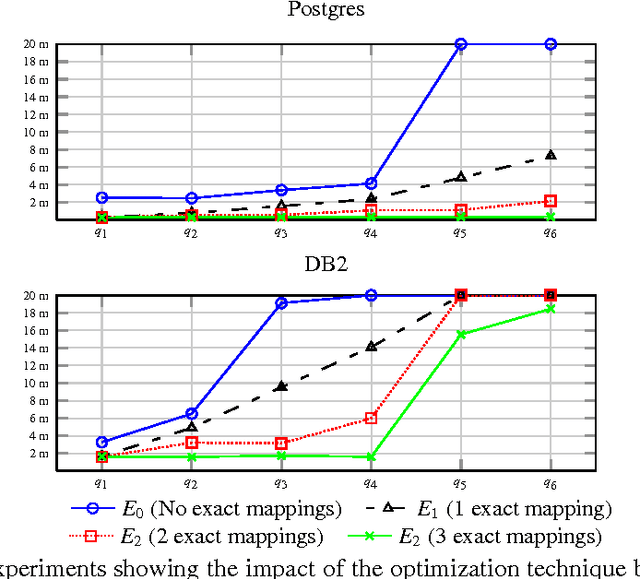
In Ontology Based Data Access (OBDA) users pose SPARQL queries over an ontology that lies on top of relational datasources. These queries are translated on-the-fly into SQL queries by OBDA systems. Standard SPARQL-to-SQL translation techniques in OBDA often produce SQL queries containing redundant joins and unions, even after a number of semantic and structural optimizations. These redundancies are detrimental to the performance of query answering, especially in complex industrial OBDA scenarios with large enterprise databases. To address this issue, we introduce two novel notions of OBDA constraints and show how to exploit them for efficient query answering. We conduct an extensive set of experiments on large datasets using real world data and queries, showing that these techniques strongly improve the performance of query answering up to orders of magnitude.