 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
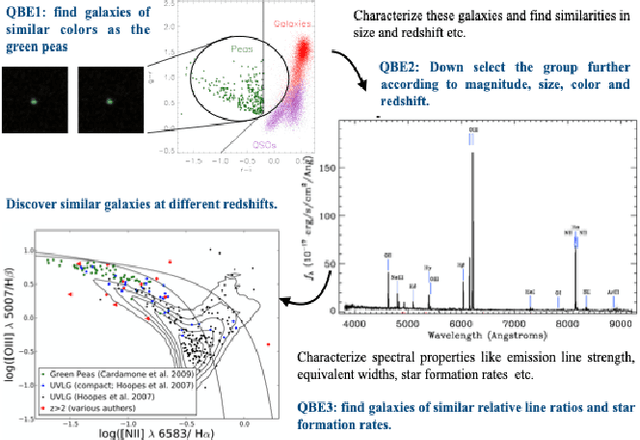
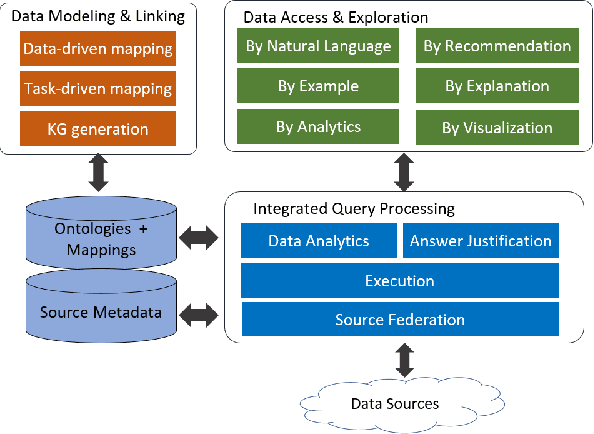

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.
Mapping Patterns for Virtual Knowledge Graphs
Dec 03, 2020Virtual Knowledge Graphs (VKG) constitute one of the most promising paradigms for integrating and accessing legacy data sources. A critical bottleneck in the integration process involves the definition, validation, and maintenance of mappings that link data sources to a domain ontology. To support the management of mappings throughout their entire lifecycle, we propose a comprehensive catalog of sophisticated mapping patterns that emerge when linking databases to ontologies. To do so, we build on well-established methodologies and patterns studied in data management, data analysis, and conceptual modeling. These are extended and refined through the analysis of concrete VKG benchmarks and real-world use cases, and considering the inherent impedance mismatch between data sources and ontologies. We validate our catalog on the considered VKG scenarios, showing that it covers the vast majority of patterns present therein.
Counting Query Answers over a DL-Lite Knowledge Base
May 25, 2020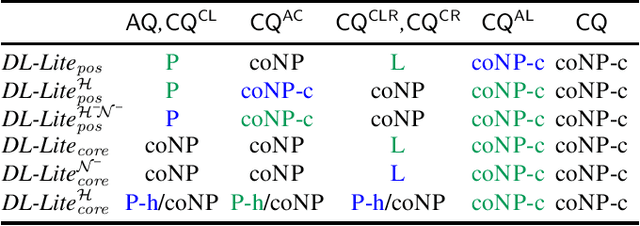
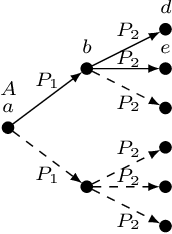
Counting answers to a query is an operation supported by virtually all database management systems. In this paper we focus on counting answers over a Knowledge Base (KB), which may be viewed as a database enriched with background knowledge about the domain under consideration. In particular, we place our work in the context of Ontology-Mediated Query Answering/Ontology-based Data Access (OMQA/OBDA), where the language used for the ontology is a member of the DL-Lite family and the data is a (usually virtual) set of assertions. We study the data complexity of query answering, for different members of the DL-Lite family that include number restrictions, and for variants of conjunctive queries with counting that differ with respect to their shape (connected, branching, rooted). We improve upon existing results by providing a PTIME and coNP lower bounds, and upper bounds in PTIME and LOGSPACE. For the latter case, we define a novel query rewriting technique into first-order logic with counting.
Enriching Ontology-based Data Access with Provenance (Extended Version)
Jun 01, 2019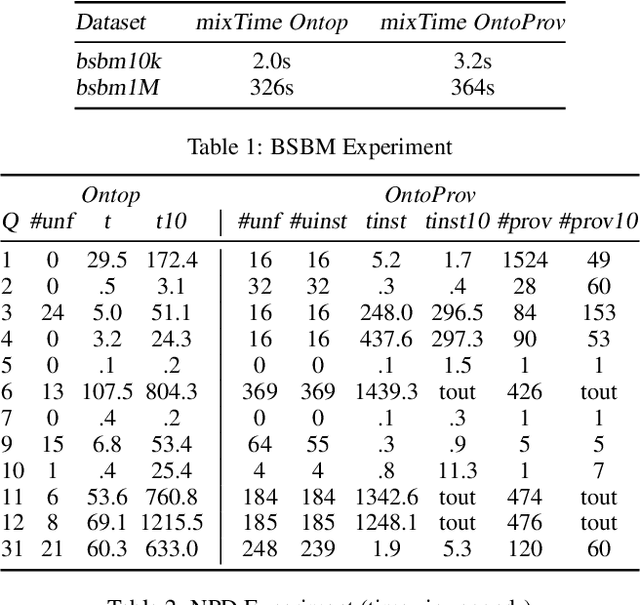
Ontology-based data access (OBDA) is a popular paradigm for querying heterogeneous data sources by connecting them through mappings to an ontology. In OBDA, it is often difficult to reconstruct why a tuple occurs in the answer of a query. We address this challenge by enriching OBDA with provenance semirings, taking inspiration from database theory. In particular, we investigate the problems of (i) deciding whether a provenance annotated OBDA instance entails a provenance annotated conjunctive query, and (ii) computing a polynomial representing the provenance of a query entailed by a provenance annotated OBDA instance. Differently from pure databases, in our case these polynomials may be infinite. To regain finiteness, we consider idempotent semirings, and study the complexity in the case of DL-Lite ontologies. We implement Task (ii) in a state-of-the-art OBDA system and show the practical feasibility of the approach through an extensive evaluation against two popular benchmarks.
OBDA Constraints for Effective Query Answering (Extended Version)
May 16, 2016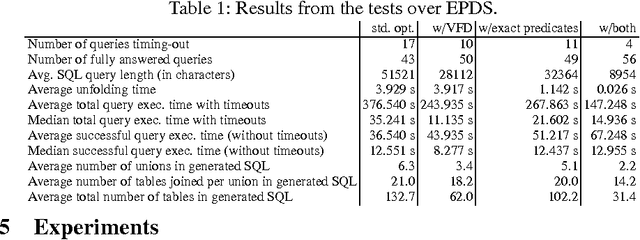
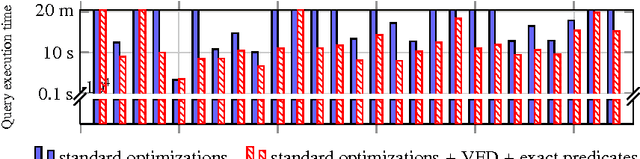
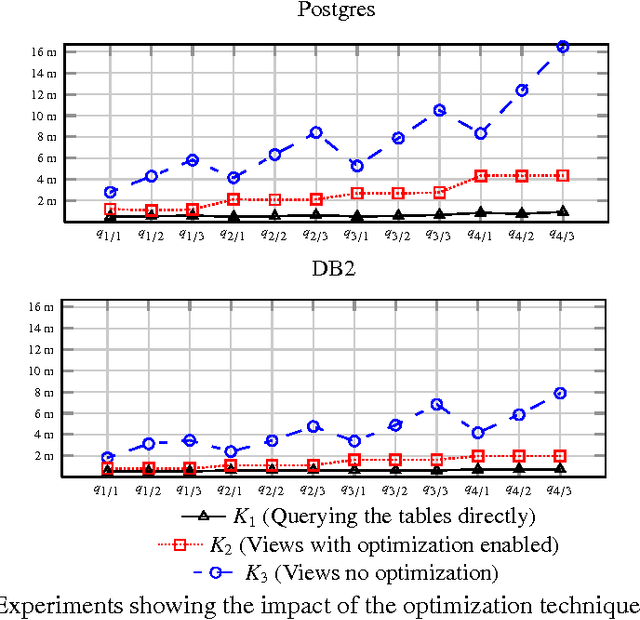
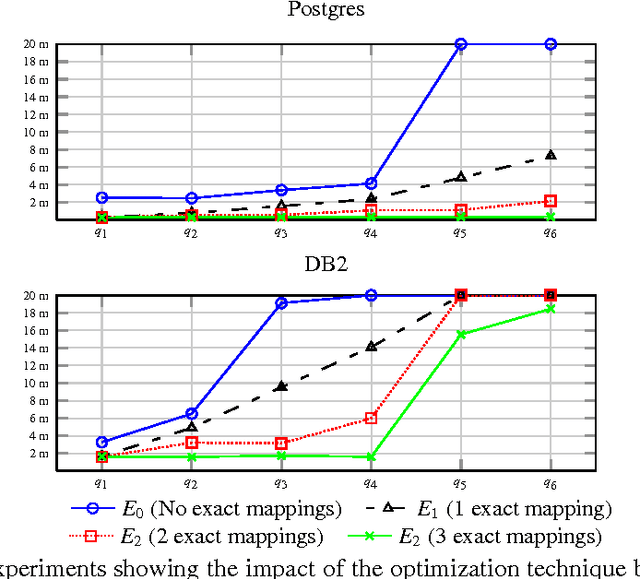
In Ontology Based Data Access (OBDA) users pose SPARQL queries over an ontology that lies on top of relational datasources. These queries are translated on-the-fly into SQL queries by OBDA systems. Standard SPARQL-to-SQL translation techniques in OBDA often produce SQL queries containing redundant joins and unions, even after a number of semantic and structural optimizations. These redundancies are detrimental to the performance of query answering, especially in complex industrial OBDA scenarios with large enterprise databases. To address this issue, we introduce two novel notions of OBDA constraints and show how to exploit them for efficient query answering. We conduct an extensive set of experiments on large datasets using real world data and queries, showing that these techniques strongly improve the performance of query answering up to orders of magnitude.