 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Barrier-free GeoQA Portal: Natural Language Interaction with Geospatial Data Using Multi-Agent LLMs and Semantic Search
Mar 18, 2025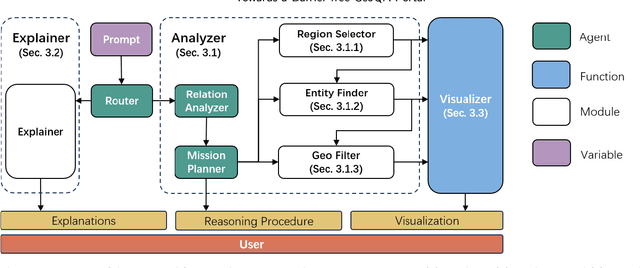
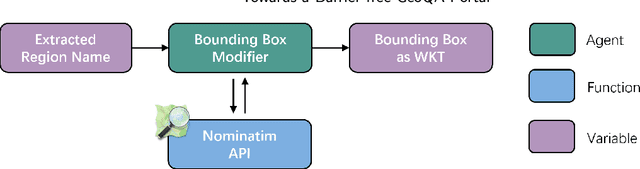

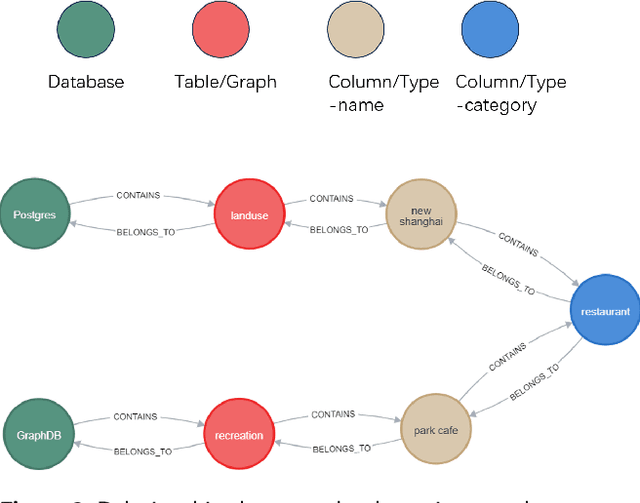
A Barrier-Free GeoQA Portal: Enhancing Geospatial Data Accessibility with a Multi-Agent LLM Framework Geoportals are vital for accessing and analyzing geospatial data, promoting open spatial data sharing and online geo-information management. Designed with GIS-like interaction and layered visualization, they often challenge non-expert users with complex functionalities and overlapping layers that obscure spatial relationships. We propose a GeoQA Portal using a multi-agent Large Language Model framework for seamless natural language interaction with geospatial data. Complex queries are broken into subtasks handled by specialized agents, retrieving relevant geographic data efficiently. Task plans are shown to users, boosting transparency. The portal supports default and custom data inputs for flexibility. Semantic search via word vector similarity aids data retrieval despite imperfect terms. Case studies, evaluations, and user tests confirm its effectiveness for non-experts, bridging GIS complexity and public access, and offering an intuitive solution for future geoportals.
Integrating 3D City Data through Knowledge Graphs
Oct 17, 2023CityGML is a widely adopted standard by the Open Geospatial Consortium (OGC) for representing and exchanging 3D city models. The representation of semantic and topological properties in CityGML makes it possible to query such 3D city data to perform analysis in various applications, e.g., security management and emergency response, energy consumption and estimation, and occupancy measurement. However, the potential of querying CityGML data has not been fully exploited. The official GML/XML encoding of CityGML is only intended as an exchange format but is not suitable for query answering. The most common way of dealing with CityGML data is to store them in the 3DCityDB system as relational tables and then query them with the standard SQL query language. Nevertheless, for end users, it remains a challenging task to formulate queries over 3DCityDB directly for their ad-hoc analytical tasks, because there is a gap between the conceptual semantics of CityGML and the relational schema adopted in 3DCityDB. In fact, the semantics of CityGML itself can be modeled as a suitable ontology. The technology of Knowledge Graphs (KGs), where an ontology is at the core, is a good solution to bridge such a gap. Moreover, embracing KGs makes it easier to integrate with other spatial data sources, e.g., OpenStreetMap and existing (Geo)KGs (e.g., Wikidata, DBPedia, and GeoNames), and to perform queries combining information from multiple data sources. In this work, we describe a CityGML KG framework to populate the concepts in the CityGML ontology using declarative mappings to 3DCityDB, thus exposing the CityGML data therein as a KG. To demonstrate the feasibility of our approach, we use CityGML data from the city of Munich as test data and integrate OpenStreeMap data in the same area.
INODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
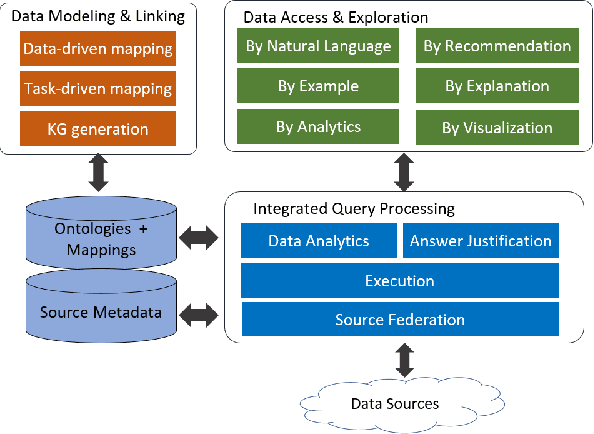

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.
Certain Answers to a SPARQL Query over a Knowledge Base
Nov 21, 2019
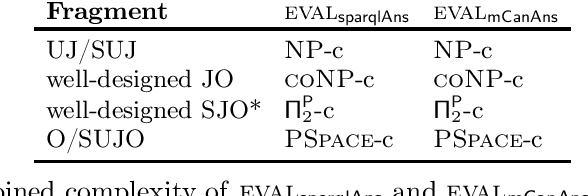
Ontology-Mediated Query Answering (OMQA) is a well-established framework to answer queries over an RDFS or OWL Knowledge Base (KB). OMQA was originally designed for unions of conjunctive queries (UCQs), and based on certain answers. More recently, OMQA has been extended to SPARQL queries, but to our knowledge, none of the efforts made in this direction (either in the literature, or the so-called SPARQL entailment regimes) is able to capture both certain answers for UCQs and the standard interpretation of SPARQL over a plain graph. We formalize these as requirements to be met by any semantics aiming at conciliating certain answers and SPARQL answers, and define three additional requirements, which generalize to KBs some basic properties of SPARQL answers. Then we show that a semantics can be defined that satisfies all requirements for SPARQL queries with SELECT, UNION, and OPTIONAL, and for DLs with the canonical model property. We also investigate combined complexity for query answering under such a semantics over DL-Lite R KBs. In particular, we show for different fragments of SPARQL that known upper-bounds for query answering over a plain graph are matched.
Enriching Ontology-based Data Access with Provenance (Extended Version)
Jun 01, 2019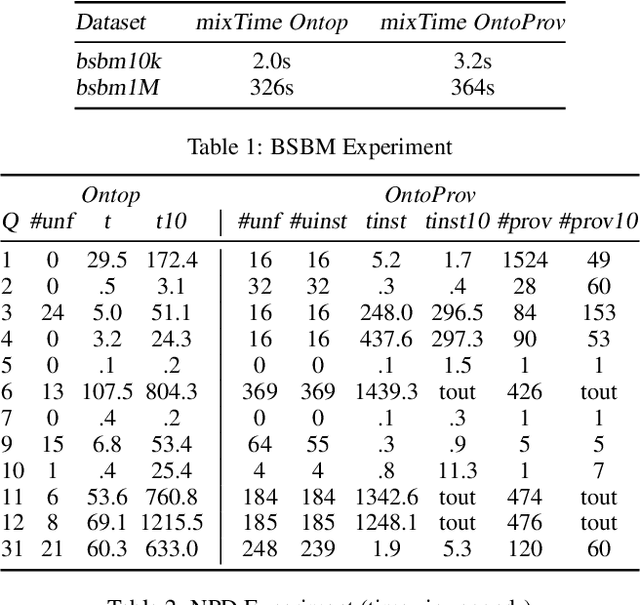
Ontology-based data access (OBDA) is a popular paradigm for querying heterogeneous data sources by connecting them through mappings to an ontology. In OBDA, it is often difficult to reconstruct why a tuple occurs in the answer of a query. We address this challenge by enriching OBDA with provenance semirings, taking inspiration from database theory. In particular, we investigate the problems of (i) deciding whether a provenance annotated OBDA instance entails a provenance annotated conjunctive query, and (ii) computing a polynomial representing the provenance of a query entailed by a provenance annotated OBDA instance. Differently from pure databases, in our case these polynomials may be infinite. To regain finiteness, we consider idempotent semirings, and study the complexity in the case of DL-Lite ontologies. We implement Task (ii) in a state-of-the-art OBDA system and show the practical feasibility of the approach through an extensive evaluation against two popular benchmarks.
BigSR: an empirical study of real-time expressive RDF stream reasoning on modern Big Data platforms
Apr 12, 2018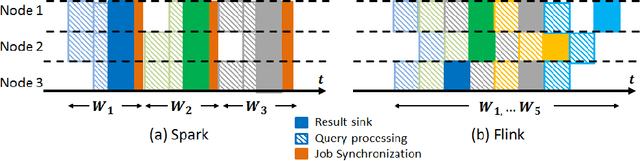
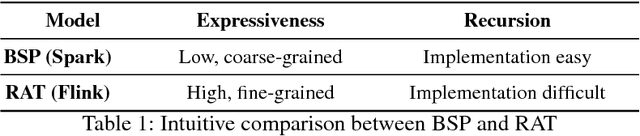
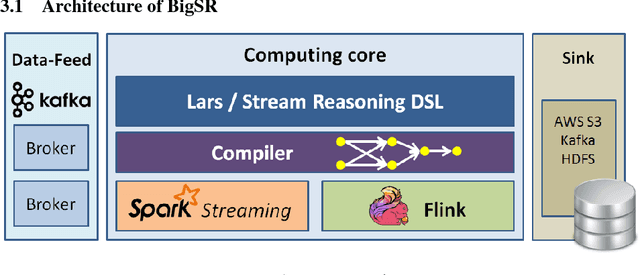

The trade-off between language expressiveness and system scalability (E&S) is a well-known problem in RDF stream reasoning. Higher expressiveness supports more complex reasoning logic, however, it may also hinder system scalability. Current research mainly focuses on logical frameworks suitable for stream reasoning as well as the implementation and the evaluation of prototype systems. These systems are normally developed in a centralized setting which suffer from inherent limited scalability, while an in-depth study of applying distributed solutions to cover E&S is still missing. In this paper, we aim to explore the feasibility of applying modern distributed computing frameworks to meet E&S all together. To do so, we first propose BigSR, a technical demonstrator that supports a positive fragment of the LARS framework. For the sake of generality and to cover a wide variety of use cases, BigSR relies on the two main execution models adopted by major distributed execution frameworks: Bulk Synchronous Processing (BSP) and Record-at-A-Time (RAT). Accordingly, we implement BigSR on top of Apache Spark Streaming (BSP model) and Apache Flink (RAT model). In order to conclude on the impacts of BSP and RAT on E&S, we analyze the ability of the two models to support distributed stream reasoning and identify several types of use cases characterized by their levels of support. This classification allows for quantifying the E&S trade-off by assessing the scalability of each type of use case \wrt its level of expressiveness. Then, we conduct a series of experiments with 15 queries from 4 different datasets. Our experiments show that BigSR over both BSP and RAT generally scales up to high throughput beyond million-triples per second (with or without recursion), and RAT attains sub-millisecond delay for stateless query operators.
OBDA Constraints for Effective Query Answering (Extended Version)
May 16, 2016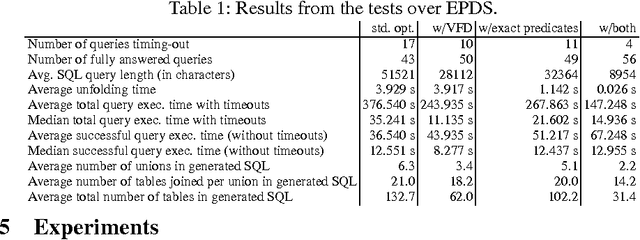
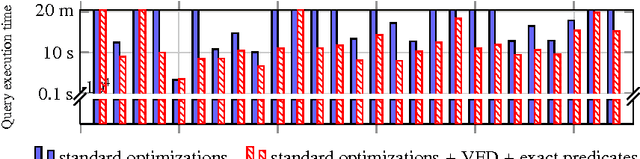
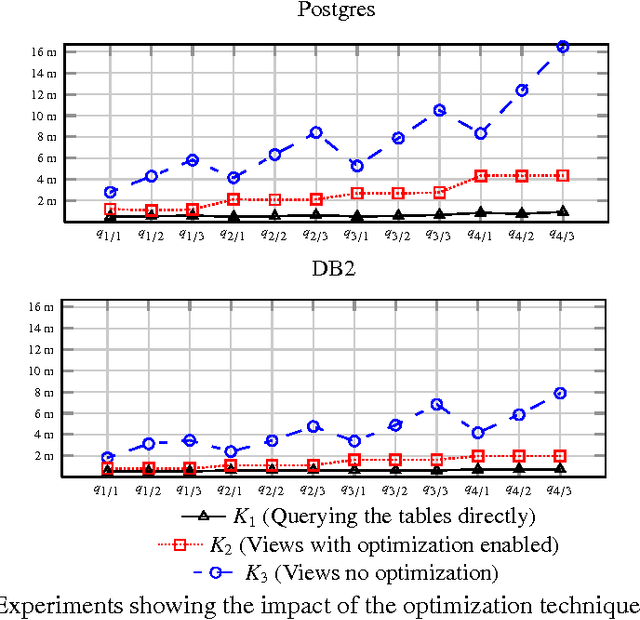
In Ontology Based Data Access (OBDA) users pose SPARQL queries over an ontology that lies on top of relational datasources. These queries are translated on-the-fly into SQL queries by OBDA systems. Standard SPARQL-to-SQL translation techniques in OBDA often produce SQL queries containing redundant joins and unions, even after a number of semantic and structural optimizations. These redundancies are detrimental to the performance of query answering, especially in complex industrial OBDA scenarios with large enterprise databases. To address this issue, we introduce two novel notions of OBDA constraints and show how to exploit them for efficient query answering. We conduct an extensive set of experiments on large datasets using real world data and queries, showing that these techniques strongly improve the performance of query answering up to orders of magnitude.
Beyond OWL 2 QL in OBDA: Rewritings and Approximations
Dec 01, 2015
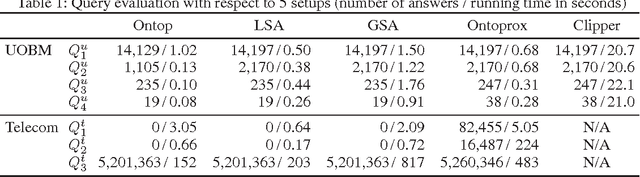
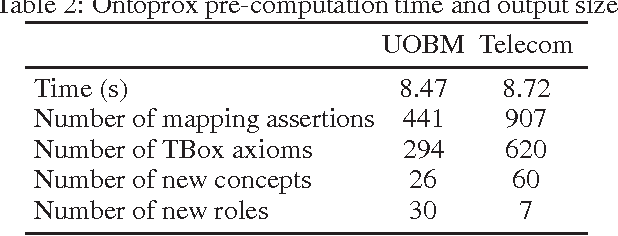
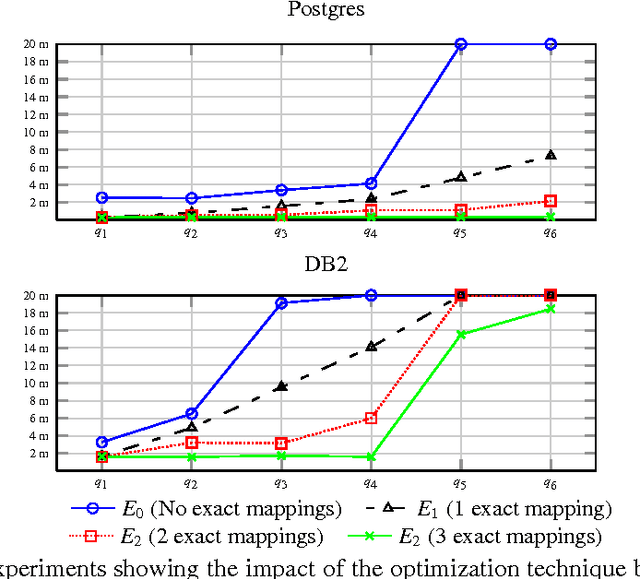
Ontology-based data access (OBDA) is a novel paradigm facilitating access to relational data, realized by linking data sources to an ontology by means of declarative mappings. DL-Lite_R, which is the logic underpinning the W3C ontology language OWL 2 QL and the current language of choice for OBDA, has been designed with the goal of delegating query answering to the underlying database engine, and thus is restricted in expressive power. E.g., it does not allow one to express disjunctive information, and any form of recursion on the data. The aim of this paper is to overcome these limitations of DL-Lite_R, and extend OBDA to more expressive ontology languages, while still leveraging the underlying relational technology for query answering. We achieve this by relying on two well-known mechanisms, namely conservative rewriting and approximation, but significantly extend their practical impact by bringing into the picture the mapping, an essential component of OBDA. Specifically, we develop techniques to rewrite OBDA specifications with an expressive ontology to "equivalent" ones with a DL-Lite_R ontology, if possible, and to approximate them otherwise. We do so by exploiting the high expressive power of the mapping layer to capture part of the domain semantics of rich ontology languages. We have implemented our techniques in the prototype system OntoProx, making use of the state-of-the-art OBDA system Ontop and the query answering system Clipper, and we have shown their feasibility and effectiveness with experiments on synthetic and real-world data.
A Paraconsistent Tableau Algorithm Based on Sign Transformation in Semantic Web
Jan 10, 2013In an open, constantly changing and collaborative environment like the forthcoming Semantic Web, it is reasonable to expect that knowledge sources will contain noise and inaccuracies. It is well known, as the logical foundation of the Semantic Web, description logic is lack of the ability of tolerating inconsistent or incomplete data. Recently, the ability of paraconsistent approaches in Semantic Web is weaker in this paper, we present a tableau algorithm based on sign transformation in Semantic Web which holds the stronger ability of reasoning. We prove that the tableau algorithm is decidable which hold the same function of classical tableau algorithm for consistent knowledge bases.