 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Pre-training and Self-training
Sep 04, 2024

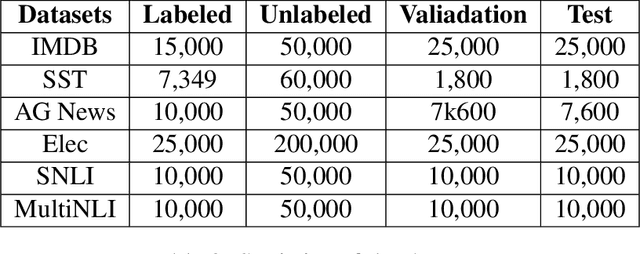
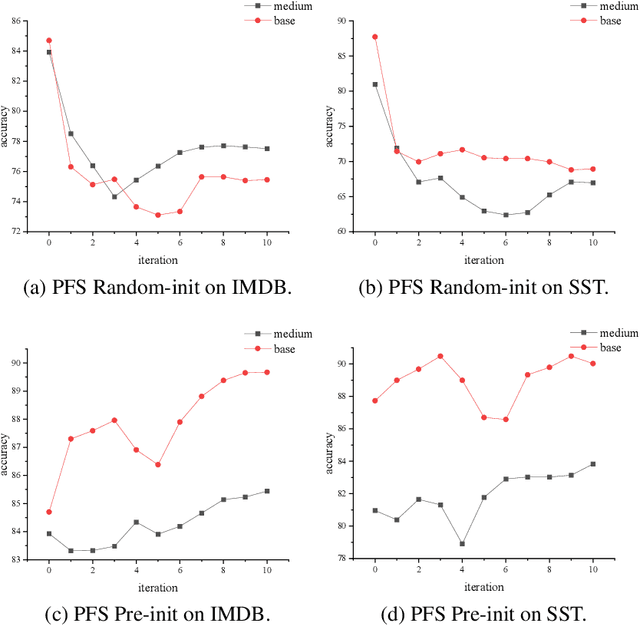
Pre-training and self-training are two approaches to semi-supervised learning. The comparison between pre-training and self-training has been explored. However, the previous works led to confusing findings: self-training outperforms pre-training experienced on some tasks in computer vision, and contrarily, pre-training outperforms self-training experienced on some tasks in natural language processing, under certain conditions of incomparable settings. We propose, comparatively and exhaustively, an ensemble method to empirical study all feasible training paradigms combining pre-training, self-training, and fine-tuning within consistent foundational settings comparable to data augmentation. We conduct experiments on six datasets, four data augmentation, and imbalanced data for sentiment analysis and natural language inference tasks. Our findings confirm that the pre-training and fine-tuning paradigm yields the best overall performances. Moreover, self-training offers no additional benefits when combined with semi-supervised pre-training.
An Empirical Study on Context Length for Open-Domain Dialog Generation
Aug 31, 2024Transformer-based open-domain dialog models have become increasingly popular in recent years. These models typically represent context as a concatenation of a dialog history. However, there is no criterion to decide how many utterances should be kept adequate in a context. We try to figure out how the choice of context length affects the model. We experiment on three questions from coarse to fine: (i) Does longer context help model training? (ii) Is it necessary to change the training context length when dealing with dialogs of different context lengths? (iii) Do different dialog samples have the same preference for context length? Our experimental results show that context length, an often overlooked setting, deserves attention when implementing Transformer-based dialog models.
Incorporating Exponential Smoothing into MLP: A Simple but Effective Sequence Model
Mar 26, 2024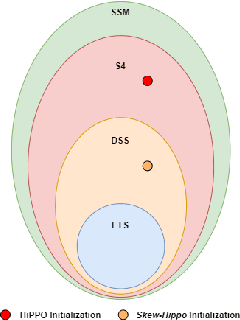
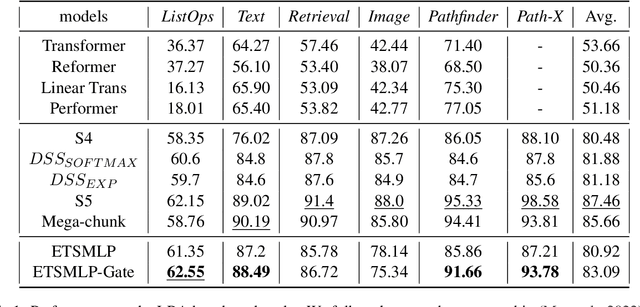
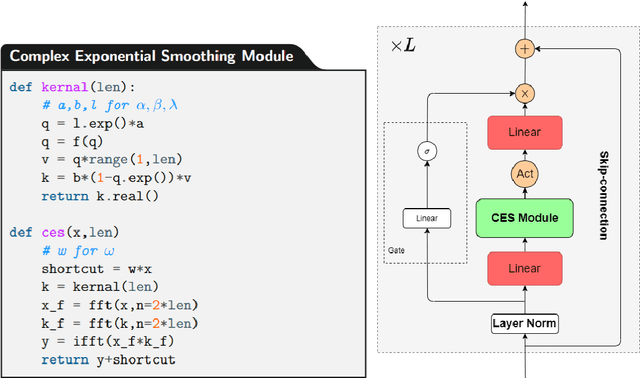
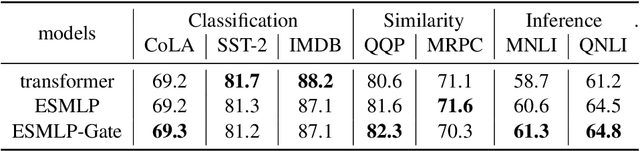
Modeling long-range dependencies in sequential data is a crucial step in sequence learning. A recently developed model, the Structured State Space (S4), demonstrated significant effectiveness in modeling long-range sequences. However, It is unclear whether the success of S4 can be attributed to its intricate parameterization and HiPPO initialization or simply due to State Space Models (SSMs). To further investigate the potential of the deep SSMs, we start with exponential smoothing (ETS), a simple SSM, and propose a stacked architecture by directly incorporating it into an element-wise MLP. We augment simple ETS with additional parameters and complex field to reduce the inductive bias. Despite increasing less than 1\% of parameters of element-wise MLP, our models achieve comparable results to S4 on the LRA benchmark.
Local and Global Contexts for Conversation
Jan 31, 2024The context in conversation is the dialog history crucial for multi-turn dialogue. Learning from the relevant contexts in dialog history for grounded conversation is a challenging problem. Local context is the most neighbor and more sensitive to the subsequent response, and global context is relevant to a whole conversation far beyond neighboring utterances. Currently, pretrained transformer models for conversation challenge capturing the correlation and connection between local and global contexts. We introduce a local and global conversation model (LGCM) for general-purpose conversation in open domain. It is a local-global hierarchical transformer model that excels at accurately discerning and assimilating the relevant contexts necessary for generating responses. It employs a local encoder to grasp the local context at the level of individual utterances and a global encoder to understand the broader context at the dialogue level. The seamless fusion of these locally and globally contextualized encodings ensures a comprehensive comprehension of the conversation. Experiments on popular datasets show that LGCM outperforms the existing conversation models on the performance of automatic metrics with significant margins.
A Paraconsistent Tableau Algorithm Based on Sign Transformation in Semantic Web
Jan 10, 2013In an open, constantly changing and collaborative environment like the forthcoming Semantic Web, it is reasonable to expect that knowledge sources will contain noise and inaccuracies. It is well known, as the logical foundation of the Semantic Web, description logic is lack of the ability of tolerating inconsistent or incomplete data. Recently, the ability of paraconsistent approaches in Semantic Web is weaker in this paper, we present a tableau algorithm based on sign transformation in Semantic Web which holds the stronger ability of reasoning. We prove that the tableau algorithm is decidable which hold the same function of classical tableau algorithm for consistent knowledge bases.
A Forgetting-based Approach to Merging Knowledge Bases
Jan 10, 2013This paper presents a novel approach based on variable forgetting, which is a useful tool in resolving contradictory by filtering some given variables, to merging multiple knowledge bases. This paper first builds a relationship between belief merging and variable forgetting by using dilation. Variable forgetting is applied to capture belief merging operation. Finally, some new merging operators are developed by modifying candidate variables to amend the shortage of traditional merging operators. Different from model selection of traditional merging operators, as an alternative approach, variable selection in those new operators could provide intuitive information about an atom variable among whole knowledge bases.
* 5 pages