 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunityBench: Benchmarking Community-Level Alignment across Diverse Groups and Tasks
Jan 20, 2026Large language models (LLMs) alignment ensures model behaviors reflect human value. Existing alignment strategies primarily follow two paths: one assumes a universal value set for a unified goal (i.e., one-size-fits-all), while the other treats every individual as unique to customize models (i.e., individual-level). However, assuming a monolithic value space marginalizes minority norms, while tailoring individual models is prohibitively expensive. Recognizing that human society is organized into social clusters with high intra-group value alignment, we propose community-level alignment as a "middle ground". Practically, we introduce CommunityBench, the first large-scale benchmark for community-level alignment evaluation, featuring four tasks grounded in Common Identity and Common Bond theory. With CommunityBench, we conduct a comprehensive evaluation of various foundation models on CommunityBench, revealing that current LLMs exhibit limited capacity to model community-specific preferences. Furthermore, we investigate the potential of community-level alignment in facilitating individual modeling, providing a promising direction for scalable and pluralistic alignment.
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025


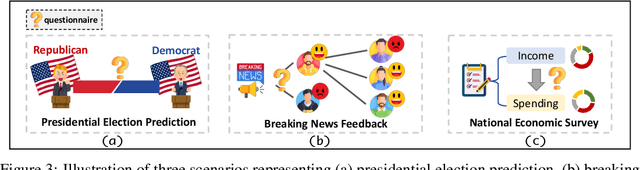
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents
Dec 04, 2024



Traditional sociological research often relies on human participation, which, though effective, is expensive, challenging to scale, and with ethical concerns. Recent advancements in large language models (LLMs) highlight their potential to simulate human behavior, enabling the replication of individual responses and facilitating studies on many interdisciplinary studies. In this paper, we conduct a comprehensive survey of this field, illustrating the recent progress in simulation driven by LLM-empowered agents. We categorize the simulations into three types: (1) Individual Simulation, which mimics specific individuals or demographic groups; (2) Scenario Simulation, where multiple agents collaborate to achieve goals within specific contexts; and (3) Society Simulation, which models interactions within agent societies to reflect the complexity and variety of real-world dynamics. These simulations follow a progression, ranging from detailed individual modeling to large-scale societal phenomena. We provide a detailed discussion of each simulation type, including the architecture or key components of the simulation, the classification of objectives or scenarios and the evaluation method. Afterward, we summarize commonly used datasets and benchmarks. Finally, we discuss the trends across these three types of simulation. A repository for the related sources is at {\url{https://github.com/FudanDISC/SocialAgent}}.
ElectionSim: Massive Population Election Simulation Powered by Large Language Model Driven Agents
Oct 28, 2024



The massive population election simulation aims to model the preferences of specific groups in particular election scenarios. It has garnered significant attention for its potential to forecast real-world social trends. Traditional agent-based modeling (ABM) methods are constrained by their ability to incorporate complex individual background information and provide interactive prediction results. In this paper, we introduce ElectionSim, an innovative election simulation framework based on large language models, designed to support accurate voter simulations and customized distributions, together with an interactive platform to dialogue with simulated voters. We present a million-level voter pool sampled from social media platforms to support accurate individual simulation. We also introduce PPE, a poll-based presidential election benchmark to assess the performance of our framework under the U.S. presidential election scenario. Through extensive experiments and analyses, we demonstrate the effectiveness and robustness of our framework in U.S. presidential election simulations.
AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios
Oct 25, 2024



Large language models (LLMs) are increasingly leveraged to empower autonomous agents to simulate human beings in various fields of behavioral research. However, evaluating their capacity to navigate complex social interactions remains a challenge. Previous studies face limitations due to insufficient scenario diversity, complexity, and a single-perspective focus. To this end, we introduce AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios. Drawing on Dramaturgical Theory, AgentSense employs a bottom-up approach to create 1,225 diverse social scenarios constructed from extensive scripts. We evaluate LLM-driven agents through multi-turn interactions, emphasizing both goal completion and implicit reasoning. We analyze goals using ERG theory and conduct comprehensive experiments. Our findings highlight that LLMs struggle with goals in complex social scenarios, especially high-level growth needs, and even GPT-4o requires improvement in private information reasoning.
A Comparative Study of Pre-training and Self-training
Sep 04, 2024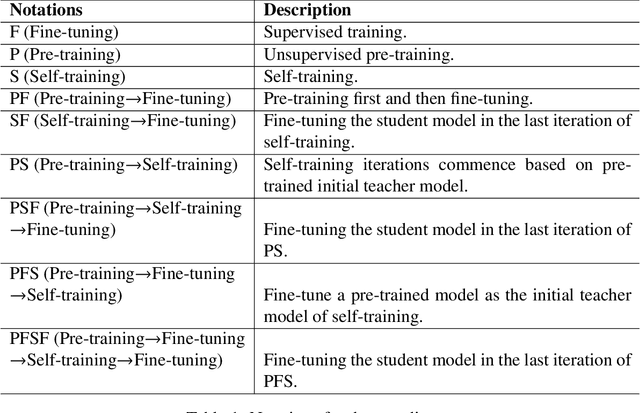

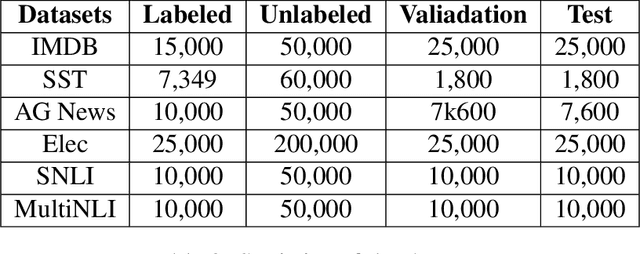
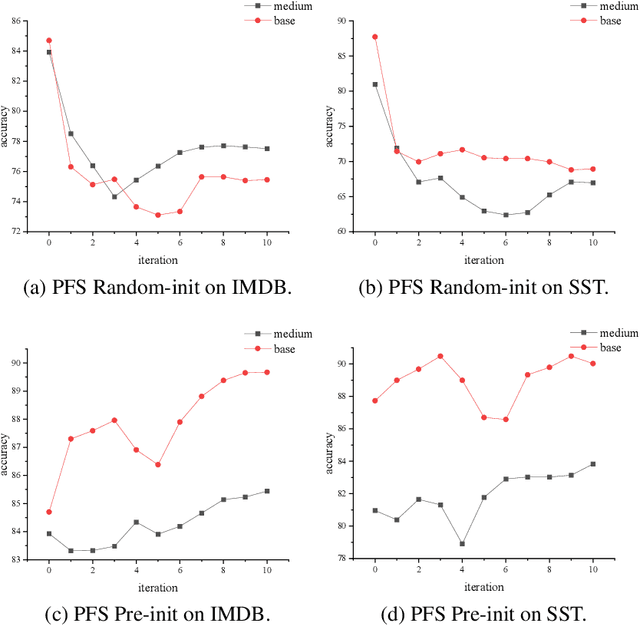
Pre-training and self-training are two approaches to semi-supervised learning. The comparison between pre-training and self-training has been explored. However, the previous works led to confusing findings: self-training outperforms pre-training experienced on some tasks in computer vision, and contrarily, pre-training outperforms self-training experienced on some tasks in natural language processing, under certain conditions of incomparable settings. We propose, comparatively and exhaustively, an ensemble method to empirical study all feasible training paradigms combining pre-training, self-training, and fine-tuning within consistent foundational settings comparable to data augmentation. We conduct experiments on six datasets, four data augmentation, and imbalanced data for sentiment analysis and natural language inference tasks. Our findings confirm that the pre-training and fine-tuning paradigm yields the best overall performances. Moreover, self-training offers no additional benefits when combined with semi-supervised pre-training.
Overview of AI-Debater 2023: The Challenges of Argument Generation Tasks
Jul 24, 2024



In this paper we present the results of the AI-Debater 2023 Challenge held by the Chinese Conference on Affect Computing (CCAC 2023), and introduce the related datasets. We organize two tracks to handle the argumentative generation tasks in different scenarios, namely, Counter-Argument Generation (Track 1) and Claim-based Argument Generation (Track 2). Each track is equipped with its distinct dataset and baseline model respectively. In total, 32 competing teams register for the challenge, from which we received 11 successful submissions. In this paper, we will present the results of the challenge and a summary of the systems, highlighting commonalities and innovations among participating systems. Datasets and baseline models of the AI-Debater 2023 Challenge have been already released and can be accessed through the official website of the challenge.
Argue with Me Tersely: Towards Sentence-Level Counter-Argument Generation
Dec 21, 2023



Counter-argument generation -- a captivating area in computational linguistics -- seeks to craft statements that offer opposing views. While most research has ventured into paragraph-level generation, sentence-level counter-argument generation beckons with its unique constraints and brevity-focused challenges. Furthermore, the diverse nature of counter-arguments poses challenges for evaluating model performance solely based on n-gram-based metrics. In this paper, we present the ArgTersely benchmark for sentence-level counter-argument generation, drawing from a manually annotated dataset from the ChangeMyView debate forum. We also propose Arg-LlaMA for generating high-quality counter-argument. For better evaluation, we trained a BERT-based evaluator Arg-Judge with human preference data. We conducted comparative experiments involving various baselines such as LlaMA, Alpaca, GPT-3, and others. The results show the competitiveness of our proposed framework and evaluator in counter-argument generation tasks. Code and data are available at https://github.com/amazingljy1206/ArgTersely.
Query-Efficient Adversarial Attack Based on Latin Hypercube Sampling
Jul 05, 2022



In order to be applicable in real-world scenario, Boundary Attacks (BAs) were proposed and ensured one hundred percent attack success rate with only decision information. However, existing BA methods craft adversarial examples by leveraging a simple random sampling (SRS) to estimate the gradient, consuming a large number of model queries. To overcome the drawback of SRS, this paper proposes a Latin Hypercube Sampling based Boundary Attack (LHS-BA) to save query budget. Compared with SRS, LHS has better uniformity under the same limited number of random samples. Therefore, the average on these random samples is closer to the true gradient than that estimated by SRS. Various experiments are conducted on benchmark datasets including MNIST, CIFAR, and ImageNet-1K. Experimental results demonstrate the superiority of the proposed LHS-BA over the state-of-the-art BA methods in terms of query efficiency. The source codes are publicly available at https://github.com/GZHU-DVL/LHS-BA.
Multi-feature Co-learning for Image Inpainting
May 21, 2022
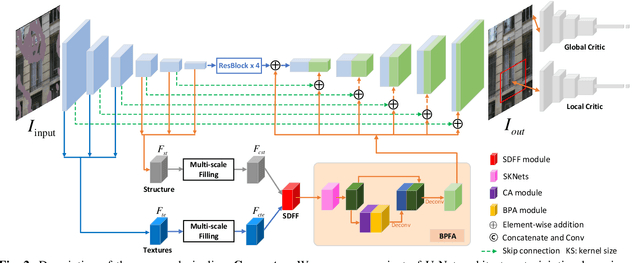
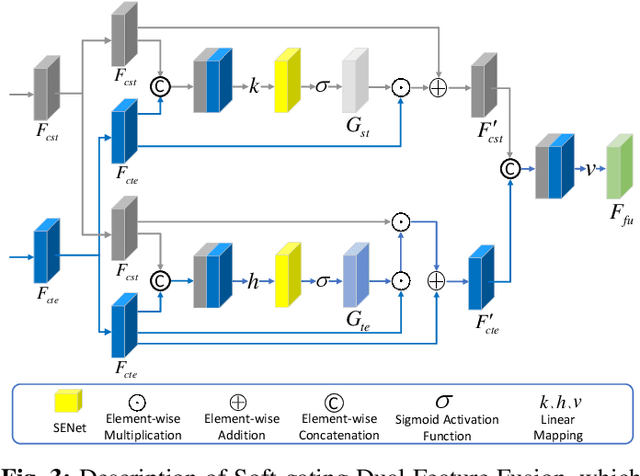
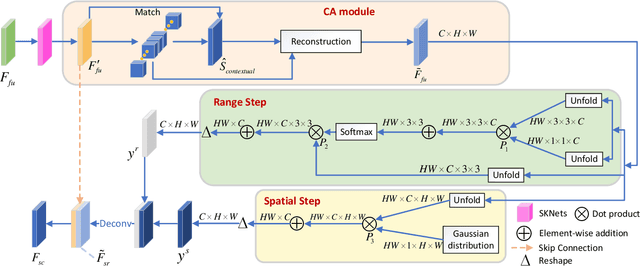
Image inpainting has achieved great advances by simultaneously leveraging image structure and texture features. However, due to lack of effective multi-feature fusion techniques, existing image inpainting methods still show limited improvement. In this paper, we design a deep multi-feature co-learning network for image inpainting, which includes Soft-gating Dual Feature Fusion (SDFF) and Bilateral Propagation Feature Aggregation (BPFA) modules. To be specific, we first use two branches to learn structure features and texture features separately. Then the proposed SDFF module integrates structure features into texture features, and meanwhile uses texture features as an auxiliary in generating structure features. Such a co-learning strategy makes the structure and texture features more consistent. Next, the proposed BPFA module enhances the connection from local feature to overall consistency by co-learning contextual attention, channel-wise information and feature space, which can further refine the generated structures and textures. Finally, extensive experiments are performed on benchmark datasets, including CelebA, Places2, and Paris StreetView. Experimental results demonstrate the superiority of the proposed method over the state-of-the-art. The source codes are available at https://github.com/GZHU-DVL/MFCL-Inpainting.