 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-feature Co-learning for Image Inpainting
Paper and Code

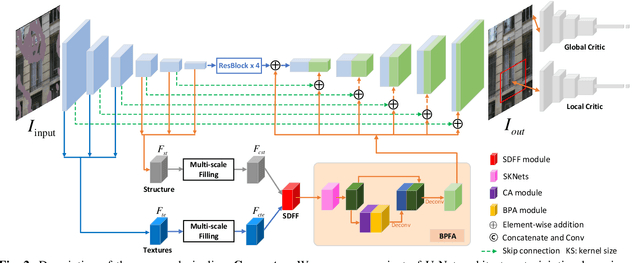
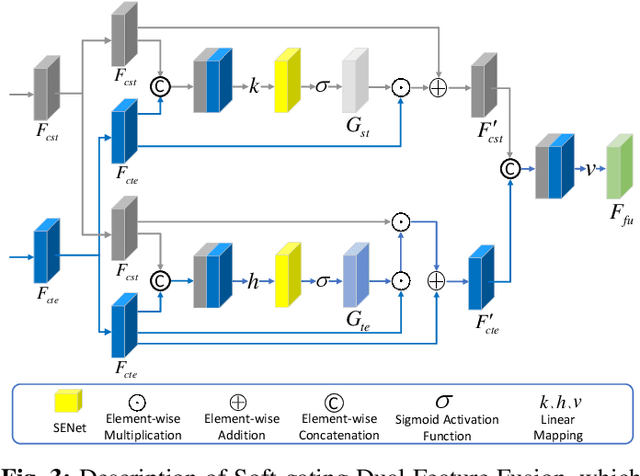
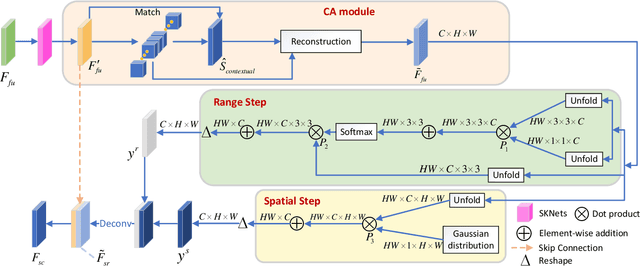
Image inpainting has achieved great advances by simultaneously leveraging image structure and texture features. However, due to lack of effective multi-feature fusion techniques, existing image inpainting methods still show limited improvement. In this paper, we design a deep multi-feature co-learning network for image inpainting, which includes Soft-gating Dual Feature Fusion (SDFF) and Bilateral Propagation Feature Aggregation (BPFA) modules. To be specific, we first use two branches to learn structure features and texture features separately. Then the proposed SDFF module integrates structure features into texture features, and meanwhile uses texture features as an auxiliary in generating structure features. Such a co-learning strategy makes the structure and texture features more consistent. Next, the proposed BPFA module enhances the connection from local feature to overall consistency by co-learning contextual attention, channel-wise information and feature space, which can further refine the generated structures and textures. Finally, extensive experiments are performed on benchmark datasets, including CelebA, Places2, and Paris StreetView. Experimental results demonstrate the superiority of the proposed method over the state-of-the-art. The source codes are available at https://github.com/GZHU-DVL/MFCL-Inpainting.