 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURP: Codebook-based Continuous User Representation for Personalized Generation with LLMs
Jan 31, 2026User modeling characterizes individuals through their preferences and behavioral patterns to enable personalized simulation and generation with Large Language Models (LLMs) in contemporary approaches. However, existing methods, whether prompt-based or training-based methods, face challenges in balancing personalization quality against computational and data efficiency. We propose a novel framework CURP, which employs a bidirectional user encoder and a discrete prototype codebook to extract multi-dimensional user traits. This design enables plug-and-play personalization with a small number of trainable parameters (about 20M parameters, about 0.2\% of the total model size). Through extensive experiments on variant generation tasks, we show that CURP achieves superior performance and generalization compared to strong baselines, while offering better interpretability and scalability. The code are available at https://github.com/RaidonWong/CURP_code
PersonaDual: Balancing Personalization and Objectivity via Adaptive Reasoning
Jan 13, 2026As users increasingly expect LLMs to align with their preferences, personalized information becomes valuable. However, personalized information can be a double-edged sword: it can improve interaction but may compromise objectivity and factual correctness, especially when it is misaligned with the question. To alleviate this problem, we propose PersonaDual, a framework that supports both general-purpose objective reasoning and personalized reasoning in a single model, and adaptively switches modes based on context. PersonaDual is first trained with SFT to learn two reasoning patterns, and then further optimized via reinforcement learning with our proposed DualGRPO to improve mode selection. Experiments on objective and personalized benchmarks show that PersonaDual preserves the benefits of personalization while reducing interference, achieving near interference-free performance and better leveraging helpful personalized signals to improve objective problem-solving.
EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation
May 11, 2025Large language models (LLMs) have demonstrated an impressive ability to role-play humans and replicate complex social dynamics. While large-scale social simulations are gaining increasing attention, they still face significant challenges, particularly regarding high time and computation costs. Existing solutions, such as distributed mechanisms or hybrid agent-based model (ABM) integrations, either fail to address inference costs or compromise accuracy and generalizability. To this end, we propose EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation. EcoLANG operates in two stages: (1) language evolution, where we filter synonymous words and optimize sentence-level rules through natural selection, and (2) language utilization, where agents in social simulations communicate using the evolved language. Experimental results demonstrate that EcoLANG reduces token consumption by over 20%, enhancing efficiency without sacrificing simulation accuracy.
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025


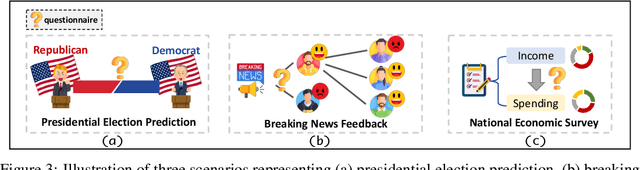
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents
Dec 04, 2024



Traditional sociological research often relies on human participation, which, though effective, is expensive, challenging to scale, and with ethical concerns. Recent advancements in large language models (LLMs) highlight their potential to simulate human behavior, enabling the replication of individual responses and facilitating studies on many interdisciplinary studies. In this paper, we conduct a comprehensive survey of this field, illustrating the recent progress in simulation driven by LLM-empowered agents. We categorize the simulations into three types: (1) Individual Simulation, which mimics specific individuals or demographic groups; (2) Scenario Simulation, where multiple agents collaborate to achieve goals within specific contexts; and (3) Society Simulation, which models interactions within agent societies to reflect the complexity and variety of real-world dynamics. These simulations follow a progression, ranging from detailed individual modeling to large-scale societal phenomena. We provide a detailed discussion of each simulation type, including the architecture or key components of the simulation, the classification of objectives or scenarios and the evaluation method. Afterward, we summarize commonly used datasets and benchmarks. Finally, we discuss the trends across these three types of simulation. A repository for the related sources is at {\url{https://github.com/FudanDISC/SocialAgent}}.
ElectionSim: Massive Population Election Simulation Powered by Large Language Model Driven Agents
Oct 28, 2024



The massive population election simulation aims to model the preferences of specific groups in particular election scenarios. It has garnered significant attention for its potential to forecast real-world social trends. Traditional agent-based modeling (ABM) methods are constrained by their ability to incorporate complex individual background information and provide interactive prediction results. In this paper, we introduce ElectionSim, an innovative election simulation framework based on large language models, designed to support accurate voter simulations and customized distributions, together with an interactive platform to dialogue with simulated voters. We present a million-level voter pool sampled from social media platforms to support accurate individual simulation. We also introduce PPE, a poll-based presidential election benchmark to assess the performance of our framework under the U.S. presidential election scenario. Through extensive experiments and analyses, we demonstrate the effectiveness and robustness of our framework in U.S. presidential election simulations.
AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios
Oct 25, 2024



Large language models (LLMs) are increasingly leveraged to empower autonomous agents to simulate human beings in various fields of behavioral research. However, evaluating their capacity to navigate complex social interactions remains a challenge. Previous studies face limitations due to insufficient scenario diversity, complexity, and a single-perspective focus. To this end, we introduce AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios. Drawing on Dramaturgical Theory, AgentSense employs a bottom-up approach to create 1,225 diverse social scenarios constructed from extensive scripts. We evaluate LLM-driven agents through multi-turn interactions, emphasizing both goal completion and implicit reasoning. We analyze goals using ERG theory and conduct comprehensive experiments. Our findings highlight that LLMs struggle with goals in complex social scenarios, especially high-level growth needs, and even GPT-4o requires improvement in private information reasoning.
Unveiling the Truth and Facilitating Change: Towards Agent-based Large-scale Social Movement Simulation
Feb 26, 2024


Social media has emerged as a cornerstone of social movements, wielding significant influence in driving societal change. Simulating the response of the public and forecasting the potential impact has become increasingly important. However, existing methods for simulating such phenomena encounter challenges concerning their efficacy and efficiency in capturing the behaviors of social movement participants. In this paper, we introduce a hybrid framework for social media user simulation, wherein users are categorized into two types. Core users are driven by Large Language Models, while numerous ordinary users are modeled by deductive agent-based models. We further construct a Twitter-like environment to replicate their response dynamics following trigger events. Subsequently, we develop a multi-faceted benchmark SoMoSiMu-Bench for evaluation and conduct comprehensive experiments across real-world datasets. Experimental results demonstrate the effectiveness and flexibility of our method.
SoMeLVLM: A Large Vision Language Model for Social Media Processing
Feb 20, 2024

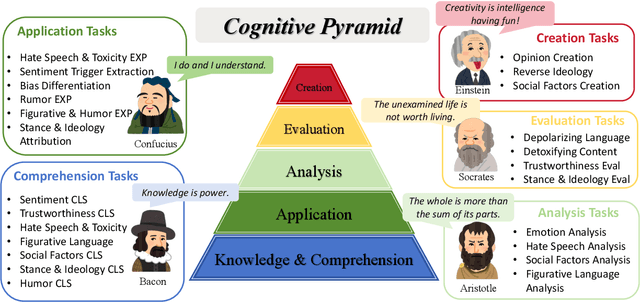

The growth of social media, characterized by its multimodal nature, has led to the emergence of diverse phenomena and challenges, which calls for an effective approach to uniformly solve automated tasks. The powerful Large Vision Language Models make it possible to handle a variety of tasks simultaneously, but even with carefully designed prompting methods, the general domain models often fall short in aligning with the unique speaking style and context of social media tasks. In this paper, we introduce a Large Vision Language Model for Social Media Processing (SoMeLVLM), which is a cognitive framework equipped with five key capabilities including knowledge & comprehension, application, analysis, evaluation, and creation. SoMeLVLM is designed to understand and generate realistic social media behavior. We have developed a 654k multimodal social media instruction-tuning dataset to support our cognitive framework and fine-tune our model. Our experiments demonstrate that SoMeLVLM achieves state-of-the-art performance in multiple social media tasks. Further analysis shows its significant advantages over baselines in terms of cognitive abilities.
GPT-4V as A Social Media Analysis Engine
Nov 13, 2023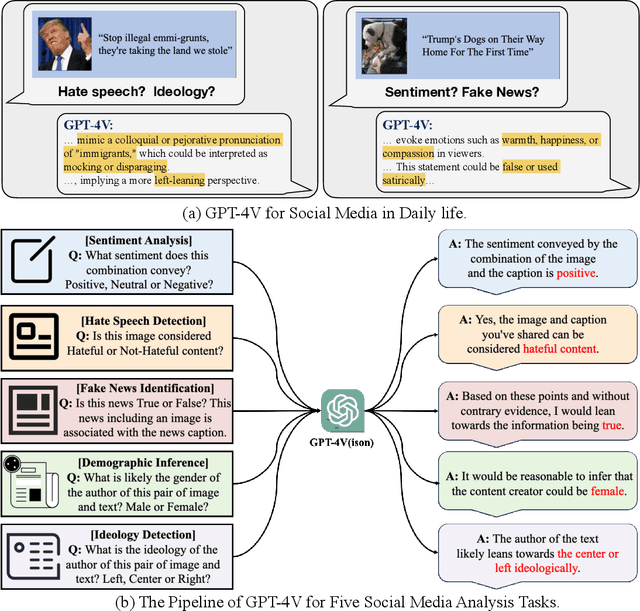

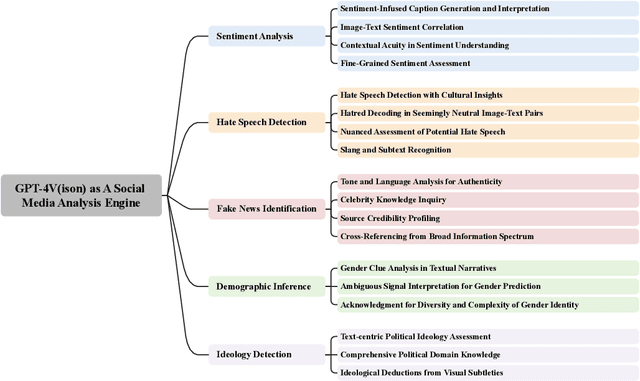
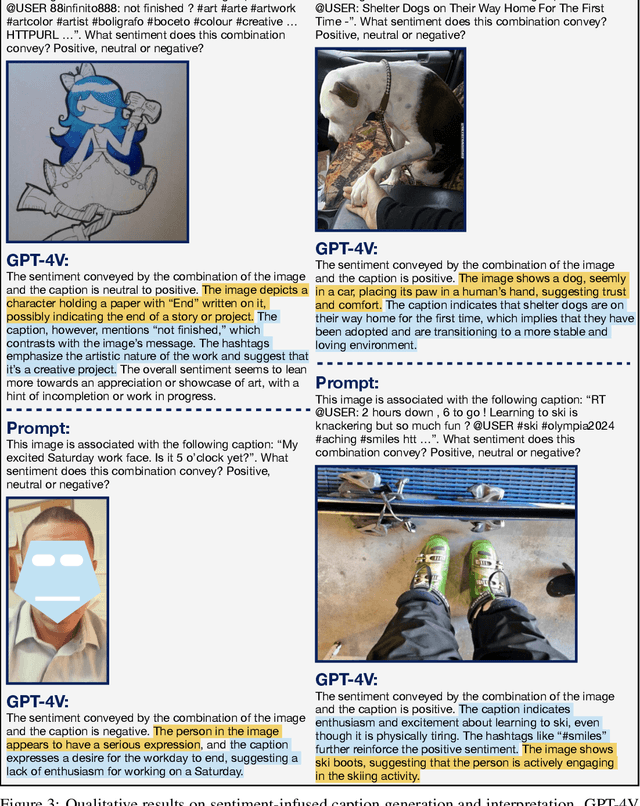
Recent research has offered insights into the extraordinary capabilities of Large Multimodal Models (LMMs) in various general vision and language tasks. There is growing interest in how LMMs perform in more specialized domains. Social media content, inherently multimodal, blends text, images, videos, and sometimes audio. Understanding social multimedia content remains a challenging problem for contemporary machine learning frameworks. In this paper, we explore GPT-4V(ision)'s capabilities for social multimedia analysis. We select five representative tasks, including sentiment analysis, hate speech detection, fake news identification, demographic inference, and political ideology detection, to evaluate GPT-4V. Our investigation begins with a preliminary quantitative analysis for each task using existing benchmark datasets, followed by a careful review of the results and a selection of qualitative samples that illustrate GPT-4V's potential in understanding multimodal social media content. GPT-4V demonstrates remarkable efficacy in these tasks, showcasing strengths such as joint understanding of image-text pairs, contextual and cultural awareness, and extensive commonsense knowledge. Despite the overall impressive capacity of GPT-4V in the social media domain, there remain notable challenges. GPT-4V struggles with tasks involving multilingual social multimedia comprehension and has difficulties in generalizing to the latest trends in social media. Additionally, it exhibits a tendency to generate erroneous information in the context of evolving celebrity and politician knowledge, reflecting the known hallucination problem. The insights gleaned from our findings underscore a promising future for LMMs in enhancing our comprehension of social media content and its users through the analysis of multimodal information.