 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoMeLVLM: A Large Vision Language Model for Social Media Processing
Paper and Code
Feb 20, 2024

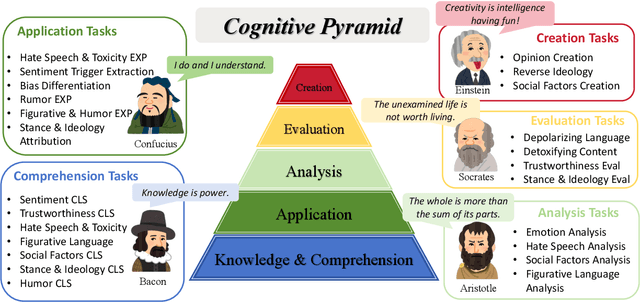

The growth of social media, characterized by its multimodal nature, has led to the emergence of diverse phenomena and challenges, which calls for an effective approach to uniformly solve automated tasks. The powerful Large Vision Language Models make it possible to handle a variety of tasks simultaneously, but even with carefully designed prompting methods, the general domain models often fall short in aligning with the unique speaking style and context of social media tasks. In this paper, we introduce a Large Vision Language Model for Social Media Processing (SoMeLVLM), which is a cognitive framework equipped with five key capabilities including knowledge & comprehension, application, analysis, evaluation, and creation. SoMeLVLM is designed to understand and generate realistic social media behavior. We have developed a 654k multimodal social media instruction-tuning dataset to support our cognitive framework and fine-tune our model. Our experiments demonstrate that SoMeLVLM achieves state-of-the-art performance in multiple social media tasks. Further analysis shows its significant advantages over baselines in terms of cognitive abilities.