 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Pre-training and Self-training
Paper and Code
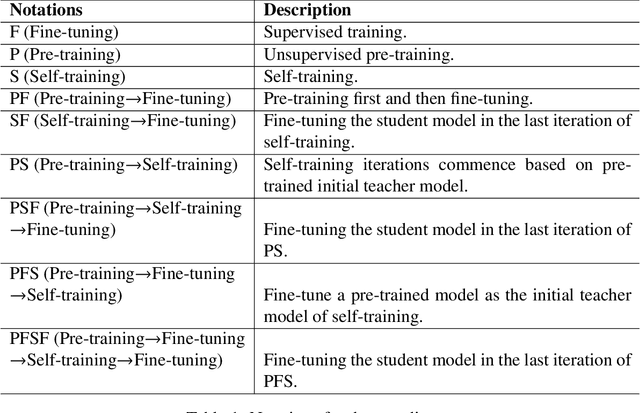

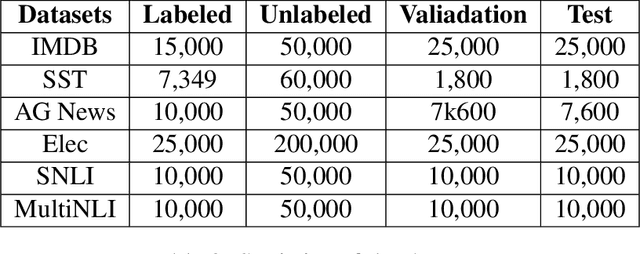
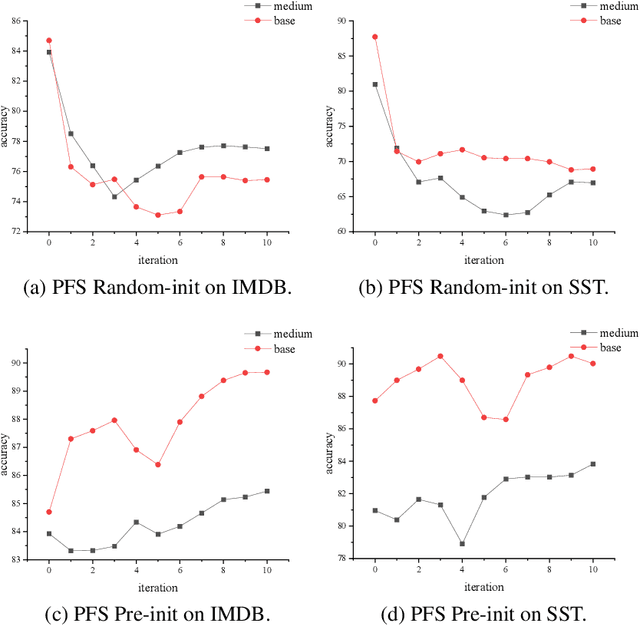
Pre-training and self-training are two approaches to semi-supervised learning. The comparison between pre-training and self-training has been explored. However, the previous works led to confusing findings: self-training outperforms pre-training experienced on some tasks in computer vision, and contrarily, pre-training outperforms self-training experienced on some tasks in natural language processing, under certain conditions of incomparable settings. We propose, comparatively and exhaustively, an ensemble method to empirical study all feasible training paradigms combining pre-training, self-training, and fine-tuning within consistent foundational settings comparable to data augmentation. We conduct experiments on six datasets, four data augmentation, and imbalanced data for sentiment analysis and natural language inference tasks. Our findings confirm that the pre-training and fine-tuning paradigm yields the best overall performances. Moreover, self-training offers no additional benefits when combined with semi-supervised pre-training.