 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multi-Table Retrieval Through Iterative Search
Nov 17, 2025Open-domain question answering over datalakes requires retrieving and composing information from multiple tables, a challenging subtask that demands semantic relevance and structural coherence (e.g., joinability). While exact optimization methods like Mixed-Integer Programming (MIP) can ensure coherence, their computational complexity is often prohibitive. Conversely, simpler greedy heuristics that optimize for query coverage alone often fail to find these coherent, joinable sets. This paper frames multi-table retrieval as an iterative search process, arguing this approach offers advantages in scalability, interpretability, and flexibility. We propose a general framework and a concrete instantiation: a fast, effective Greedy Join-Aware Retrieval algorithm that holistically balances relevance, coverage, and joinability. Experiments across 5 NL2SQL benchmarks demonstrate that our iterative method achieves competitive retrieval performance compared to the MIP-based approach while being 4-400x faster depending on the benchmark and search space settings. This work highlights the potential of iterative heuristics for practical, scalable, and composition-aware retrieval.
Something's Fishy In The Data Lake: A Critical Re-evaluation of Table Union Search Benchmarks
May 28, 2025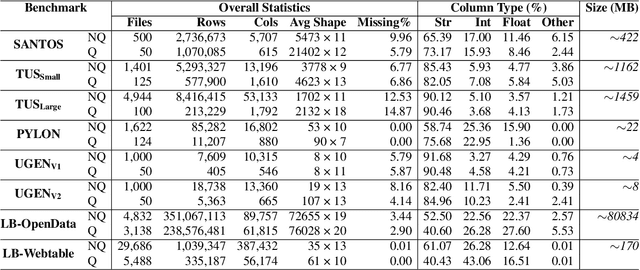
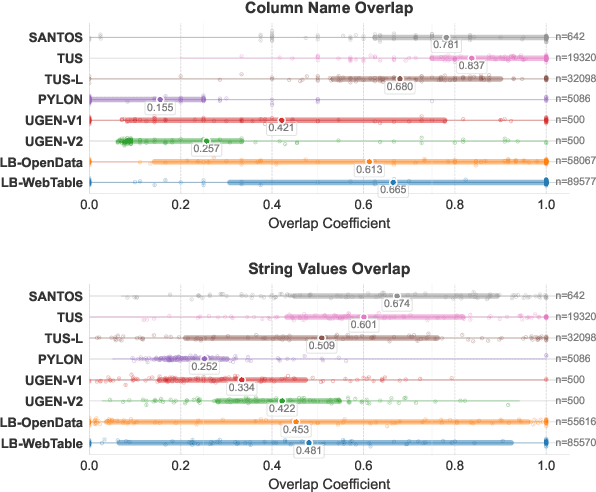
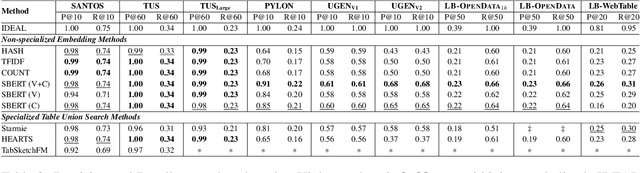
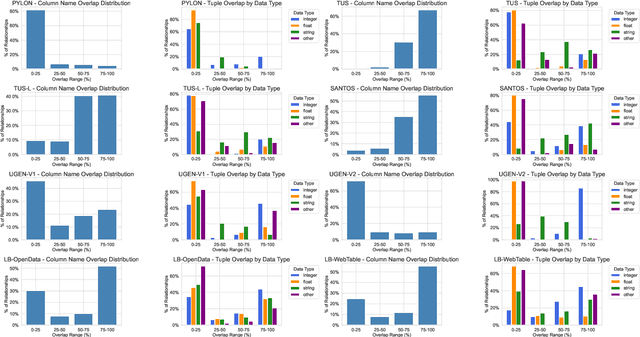
Recent table representation learning and data discovery methods tackle table union search (TUS) within data lakes, which involves identifying tables that can be unioned with a given query table to enrich its content. These methods are commonly evaluated using benchmarks that aim to assess semantic understanding in real-world TUS tasks. However, our analysis of prominent TUS benchmarks reveals several limitations that allow simple baselines to perform surprisingly well, often outperforming more sophisticated approaches. This suggests that current benchmark scores are heavily influenced by dataset-specific characteristics and fail to effectively isolate the gains from semantic understanding. To address this, we propose essential criteria for future benchmarks to enable a more realistic and reliable evaluation of progress in semantic table union search.
TISIS : Trajectory Indexing for SImilarity Search
Sep 17, 2024
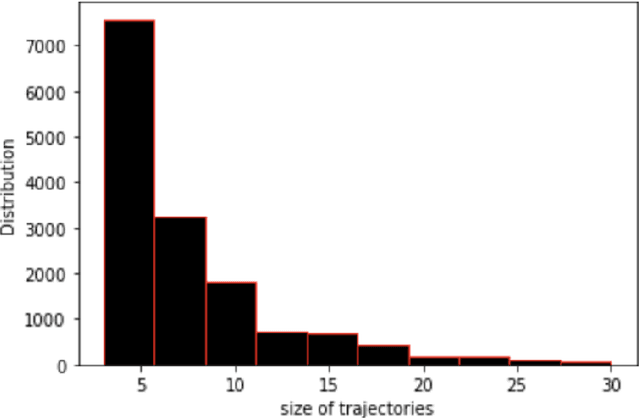
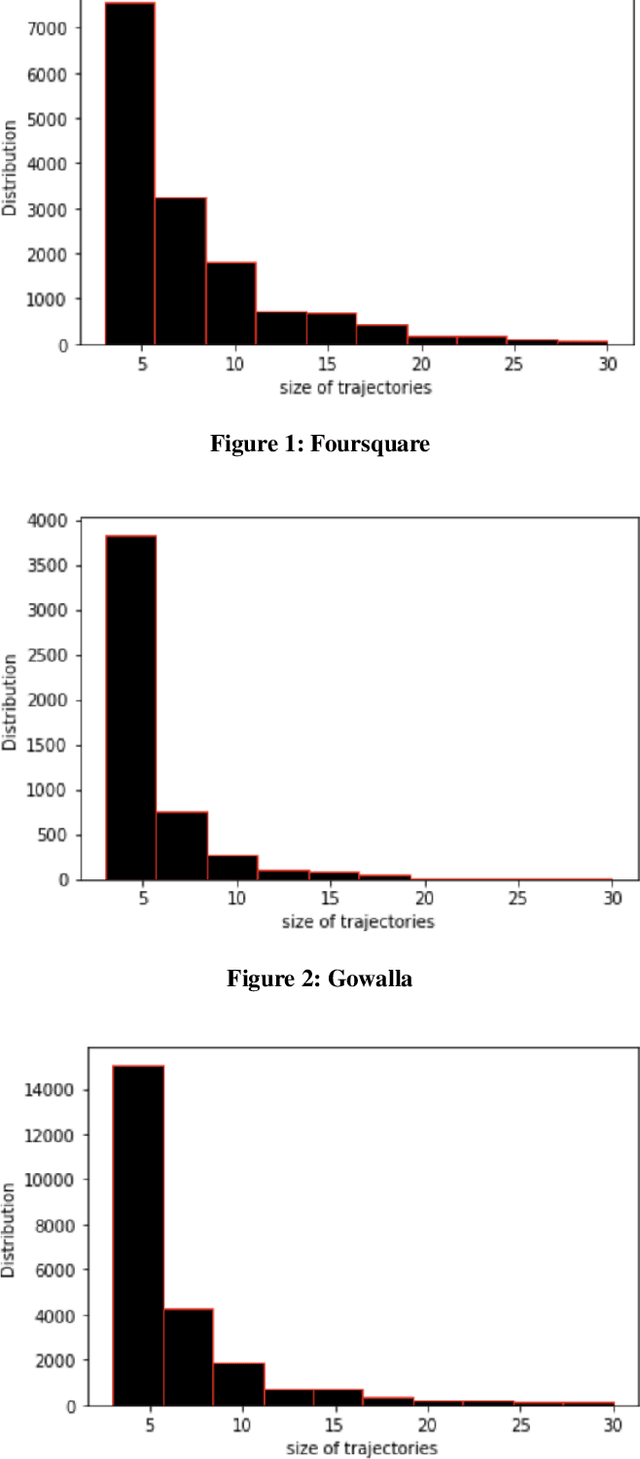

Social media platforms enable users to share diverse types of information, including geolocation data that captures their movement patterns. Such geolocation data can be leveraged to reconstruct the trajectory of a user's visited Points of Interest (POIs). A key requirement in numerous applications is the ability to measure the similarity between such trajectories, as this facilitates the retrieval of trajectories that are similar to a given reference trajectory. This is the main focus of our work. Existing methods predominantly rely on applying a similarity function to each candidate trajectory to identify those that are sufficiently similar. However, this approach becomes computationally expensive when dealing with large-scale datasets. To mitigate this challenge, we propose TISIS, an efficient method that uses trajectory indexing to quickly find similar trajectories that share common POIs in the same order. Furthermore, to account for scenarios where POIs in trajectories may not exactly match but are contextually similar, we introduce TISIS*, a variant of TISIS that incorporates POI embeddings. This extension allows for more comprehensive retrieval of similar trajectories by considering semantic similarities between POIs, beyond mere exact matches. Extensive experimental evaluations demonstrate that the proposed approach significantly outperforms a baseline method based on the well-known Longest Common SubSequence (LCSS) algorithm, yielding substantial performance improvements across various real-world datasets.
Leiden-Fusion Partitioning Method for Effective Distributed Training of Graph Embeddings
Sep 15, 2024In the area of large-scale training of graph embeddings, effective training frameworks and partitioning methods are critical for handling large networks. However, they face two major challenges: 1) existing synchronized distributed frameworks require continuous communication to access information from other machines, and 2) the inability of current partitioning methods to ensure that subgraphs remain connected components without isolated nodes, which is essential for effective training of GNNs since training relies on information aggregation from neighboring nodes. To address these issues, we introduce a novel partitioning method, named Leiden-Fusion, designed for large-scale training of graphs with minimal communication. Our method extends the Leiden community detection algorithm with a greedy algorithm that merges the smallest communities with highly connected neighboring communities. Our method guarantees that, for an initially connected graph, each partition is a densely connected subgraph with no isolated nodes. After obtaining the partitions, we train a GNN for each partition independently, and finally integrate all embeddings for node classification tasks, which significantly reduces the need for network communication and enhances the efficiency of distributed graph training. We demonstrate the effectiveness of our method through extensive evaluations on several benchmark datasets, achieving high efficiency while preserving the quality of the graph embeddings for node classification tasks.
ATEM: A Topic Evolution Model for the Detection of Emerging Topics in Scientific Archives
Jun 04, 2023


This paper presents ATEM, a novel framework for studying topic evolution in scientific archives. ATEM is based on dynamic topic modeling and dynamic graph embedding techniques that explore the dynamics of content and citations of documents within a scientific corpus. ATEM explores a new notion of contextual emergence for the discovery of emerging interdisciplinary research topics based on the dynamics of citation links in topic clusters. Our experiments show that ATEM can efficiently detect emerging cross-disciplinary topics within the DBLP archive of over five million computer science articles.
Contextualized Topic Coherence Metrics
May 23, 2023The recent explosion in work on neural topic modeling has been criticized for optimizing automated topic evaluation metrics at the expense of actual meaningful topic identification. But human annotation remains expensive and time-consuming. We propose LLM-based methods inspired by standard human topic evaluations, in a family of metrics called Contextualized Topic Coherence (CTC). We evaluate both a fully automated version as well as a semi-automated CTC that allows human-centered evaluation of coherence while maintaining the efficiency of automated methods. We evaluate CTC relative to five other metrics on six topic models and find that it outperforms automated topic coherence methods, works well on short documents, and is not susceptible to meaningless but high-scoring topics.
ANTM: An Aligned Neural Topic Model for Exploring Evolving Topics
Feb 03, 2023
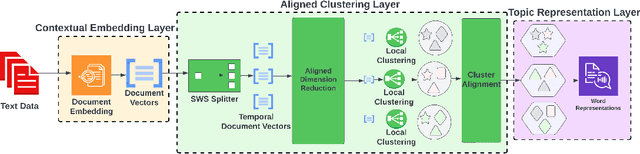
As the amount of text data generated by humans and machines increases, the necessity of understanding large corpora and finding a way to extract insights from them is becoming more crucial than ever. Dynamic topic models are effective methods that primarily focus on studying the evolution of topics present in a collection of documents. These models are widely used for understanding trends, exploring public opinion in social networks, or tracking research progress and discoveries in scientific archives. Since topics are defined as clusters of semantically similar documents, it is necessary to observe the changes in the content or themes of these clusters in order to understand how topics evolve as new knowledge is discovered over time. In this paper, we introduce the Aligned Neural Topic Model (ANTM), a dynamic neural topic model that uses document embeddings to compute clusters of semantically similar documents at different periods and to align document clusters to represent their evolution. This alignment procedure preserves the temporal similarity of document clusters over time and captures the semantic change of words characterized by their context within different periods. Experiments on four different datasets show that ANTM outperforms probabilistic dynamic topic models (e.g. DTM, DETM) and significantly improves topic coherence and diversity over other existing dynamic neural topic models (e.g. BERTopic).
BigSR: an empirical study of real-time expressive RDF stream reasoning on modern Big Data platforms
Apr 12, 2018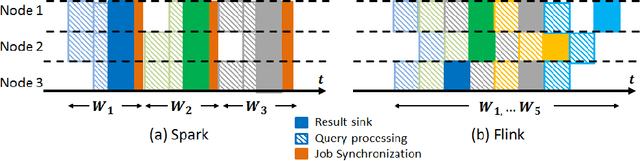
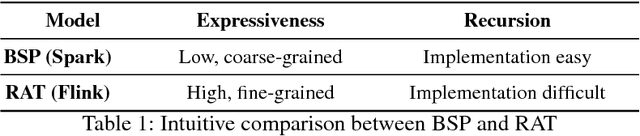
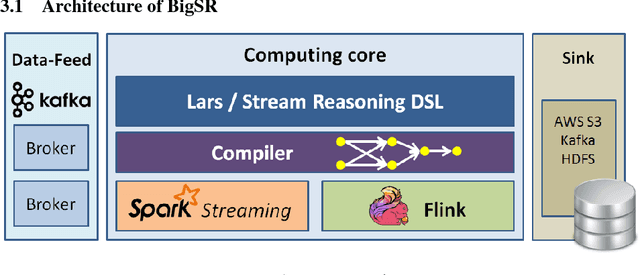

The trade-off between language expressiveness and system scalability (E&S) is a well-known problem in RDF stream reasoning. Higher expressiveness supports more complex reasoning logic, however, it may also hinder system scalability. Current research mainly focuses on logical frameworks suitable for stream reasoning as well as the implementation and the evaluation of prototype systems. These systems are normally developed in a centralized setting which suffer from inherent limited scalability, while an in-depth study of applying distributed solutions to cover E&S is still missing. In this paper, we aim to explore the feasibility of applying modern distributed computing frameworks to meet E&S all together. To do so, we first propose BigSR, a technical demonstrator that supports a positive fragment of the LARS framework. For the sake of generality and to cover a wide variety of use cases, BigSR relies on the two main execution models adopted by major distributed execution frameworks: Bulk Synchronous Processing (BSP) and Record-at-A-Time (RAT). Accordingly, we implement BigSR on top of Apache Spark Streaming (BSP model) and Apache Flink (RAT model). In order to conclude on the impacts of BSP and RAT on E&S, we analyze the ability of the two models to support distributed stream reasoning and identify several types of use cases characterized by their levels of support. This classification allows for quantifying the E&S trade-off by assessing the scalability of each type of use case \wrt its level of expressiveness. Then, we conduct a series of experiments with 15 queries from 4 different datasets. Our experiments show that BigSR over both BSP and RAT generally scales up to high throughput beyond million-triples per second (with or without recursion), and RAT attains sub-millisecond delay for stateless query operators.
Dynamic recommender system : using cluster-based biases to improve the accuracy of the predictions
Dec 03, 2012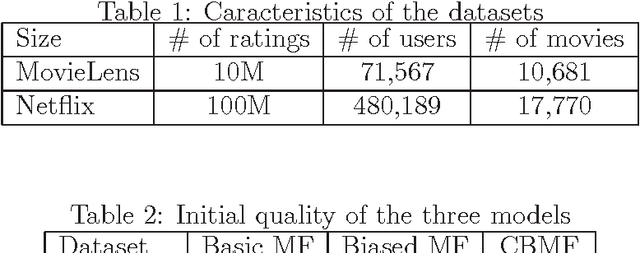
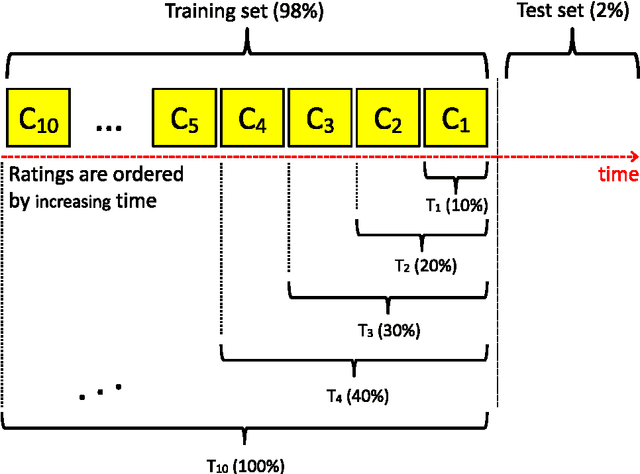
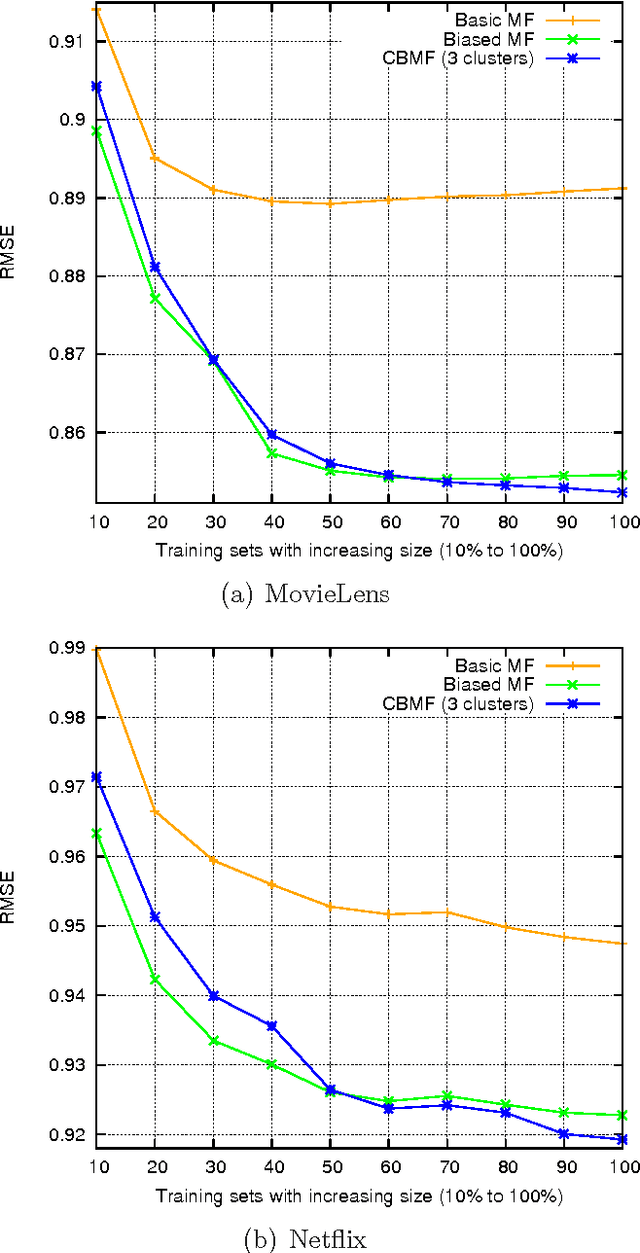

It is today accepted that matrix factorization models allow a high quality of rating prediction in recommender systems. However, a major drawback of matrix factorization is its static nature that results in a progressive declining of the accuracy of the predictions after each factorization. This is due to the fact that the new obtained ratings are not taken into account until a new factorization is computed, which can not be done very often because of the high cost of matrix factorization. In this paper, aiming at improving the accuracy of recommender systems, we propose a cluster-based matrix factorization technique that enables online integration of new ratings. Thus, we significantly enhance the obtained predictions between two matrix factorizations. We use finer-grained user biases by clustering similar items into groups, and allocating in these groups a bias to each user. The experiments we did on large datasets demonstrated the efficiency of our approach.