 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Topic Coherence Metrics
May 23, 2023The recent explosion in work on neural topic modeling has been criticized for optimizing automated topic evaluation metrics at the expense of actual meaningful topic identification. But human annotation remains expensive and time-consuming. We propose LLM-based methods inspired by standard human topic evaluations, in a family of metrics called Contextualized Topic Coherence (CTC). We evaluate both a fully automated version as well as a semi-automated CTC that allows human-centered evaluation of coherence while maintaining the efficiency of automated methods. We evaluate CTC relative to five other metrics on six topic models and find that it outperforms automated topic coherence methods, works well on short documents, and is not susceptible to meaningless but high-scoring topics.
Linguistic dependencies and statistical dependence
Apr 18, 2021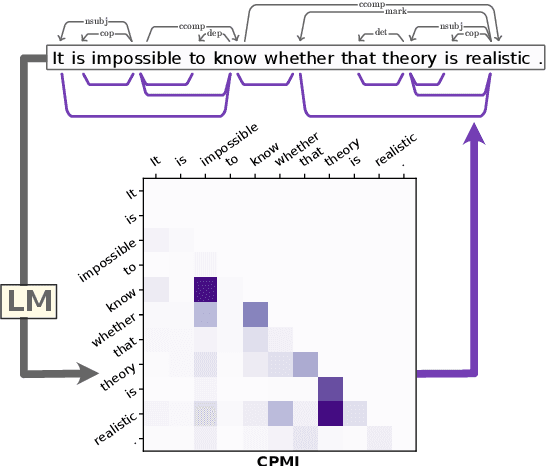
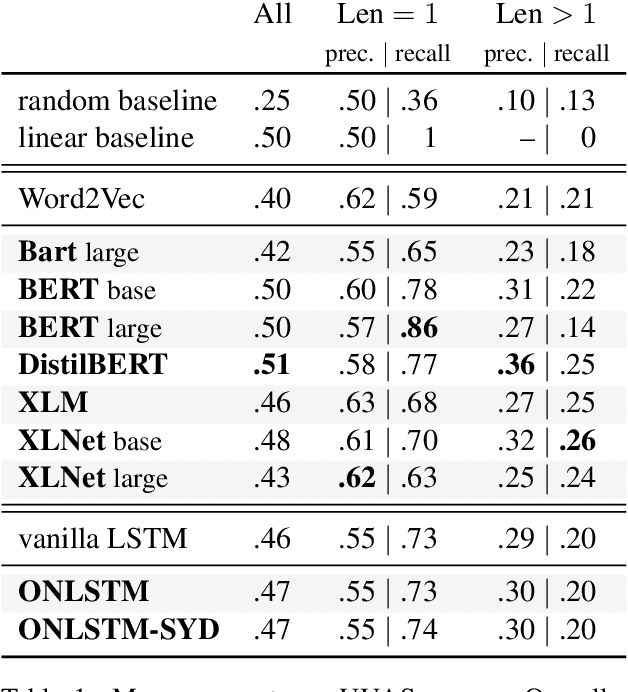
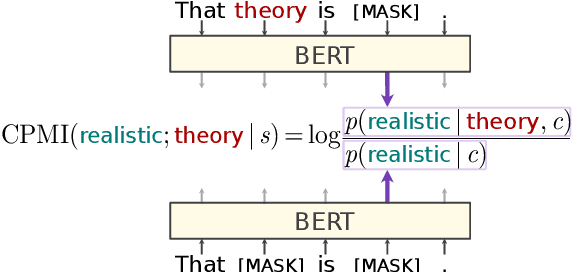
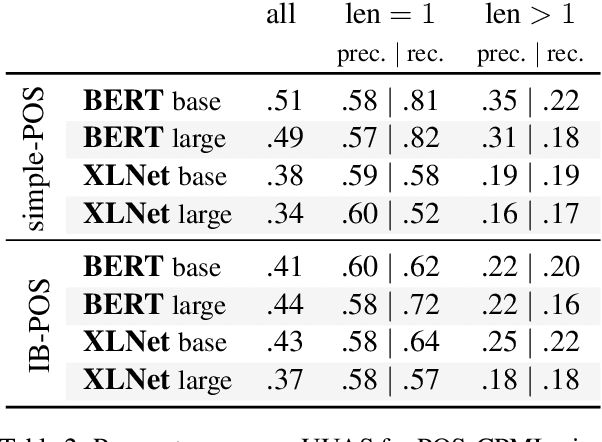
What is the relationship between linguistic dependencies and statistical dependence? Building on earlier work in NLP and cognitive science, we study this question. We introduce a contextualized version of pointwise mutual information (CPMI), using pretrained language models to estimate probabilities of words in context. Extracting dependency trees which maximize CPMI, we compare the resulting structures against gold dependencies. Overall, we find that these maximum-CPMI trees correspond to linguistic dependencies more often than trees extracted from non-contextual PMI estimate, but only roughly as often as a simple baseline formed by connecting adjacent words. We also provide evidence that the extent to which the two kinds of dependency align cannot be explained by the distance between words or by the category of the dependency relation. Finally, our analysis sheds some light on the differences between large pretrained language models, specifically in the kinds of inductive biases they encode.