 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic dependencies and statistical dependence
Paper and Code
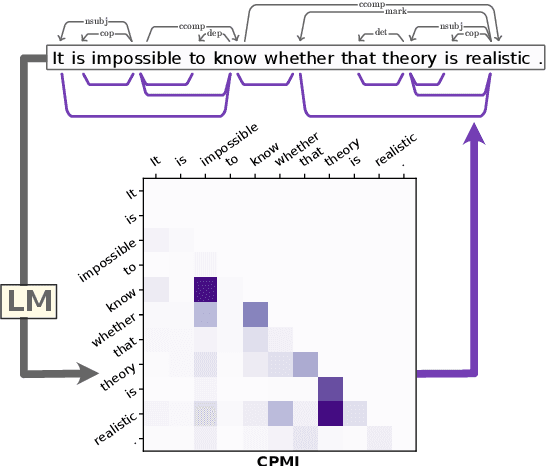
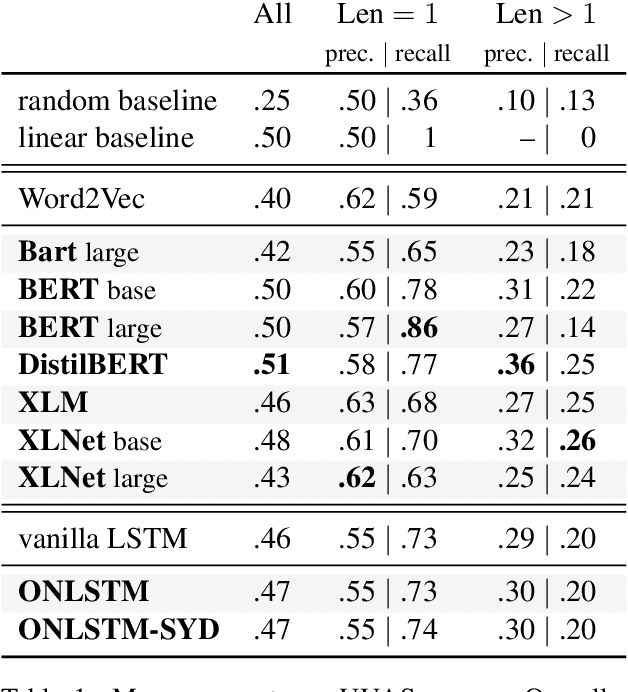
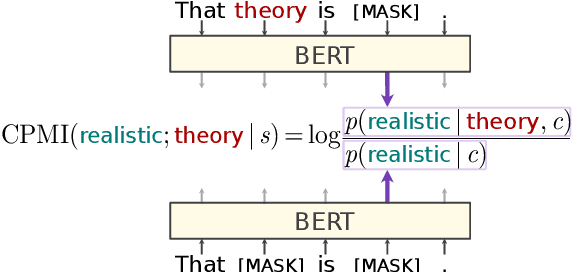
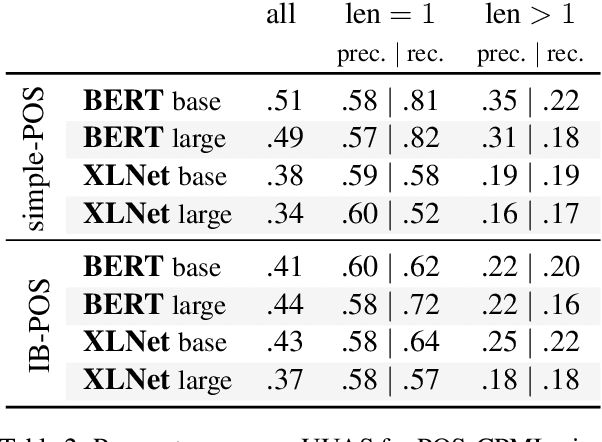
What is the relationship between linguistic dependencies and statistical dependence? Building on earlier work in NLP and cognitive science, we study this question. We introduce a contextualized version of pointwise mutual information (CPMI), using pretrained language models to estimate probabilities of words in context. Extracting dependency trees which maximize CPMI, we compare the resulting structures against gold dependencies. Overall, we find that these maximum-CPMI trees correspond to linguistic dependencies more often than trees extracted from non-contextual PMI estimate, but only roughly as often as a simple baseline formed by connecting adjacent words. We also provide evidence that the extent to which the two kinds of dependency align cannot be explained by the distance between words or by the category of the dependency relation. Finally, our analysis sheds some light on the differences between large pretrained language models, specifically in the kinds of inductive biases they encode.