 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining the (Not So) Obvious: Simple and Fast Explanation of STAN, a Next Point of Interest Recommendation System
Oct 04, 2024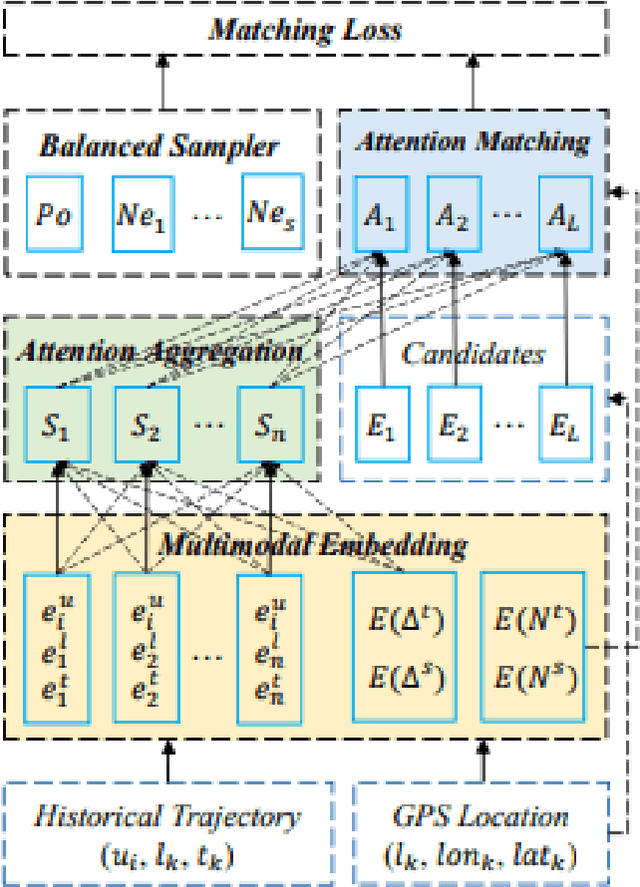
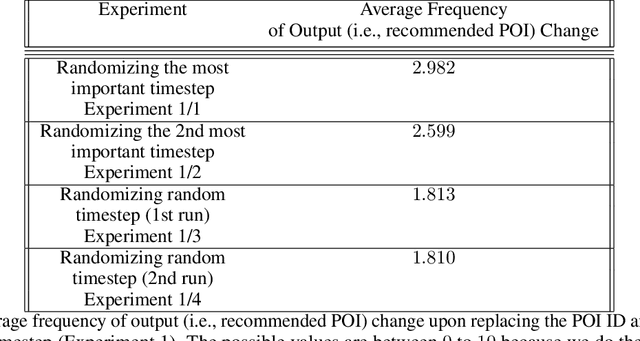
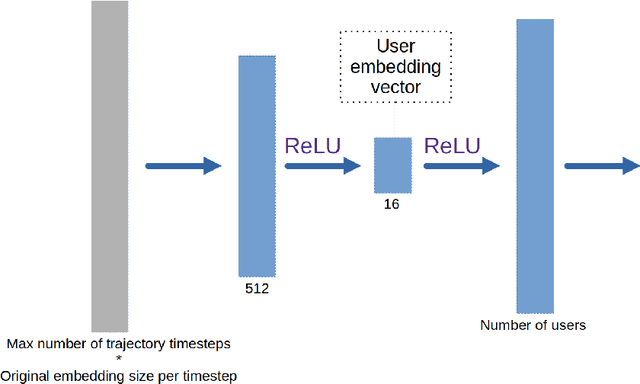

A lot of effort in recent years have been expended to explain machine learning systems. However, some machine learning methods are inherently explainable, and thus are not completely black box. This enables the developers to make sense of the output without a developing a complex and expensive explainability technique. Besides that, explainability should be tailored to suit the context of the problem. In a recommendation system which relies on collaborative filtering, the recommendation is based on the behaviors of similar users, therefore the explanation should tell which other users are similar to the current user. Similarly, if the recommendation system is based on sequence prediction, the explanation should also tell which input timesteps are the most influential. We demonstrate this philosophy/paradigm in STAN (Spatio-Temporal Attention Network for Next Location Recommendation), a next Point of Interest recommendation system based on collaborative filtering and sequence prediction. We also show that the explanation helps to "debug" the output.
River: machine learning for streaming data in Python
Dec 08, 2020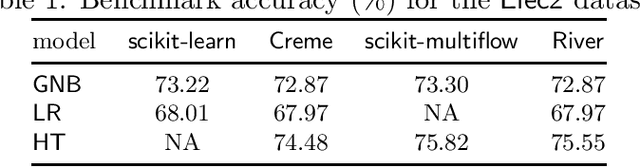

River is a machine learning library for dynamic data streams and continual learning. It provides multiple state-of-the-art learning methods, data generators/transformers, performance metrics and evaluators for different stream learning problems. It is the result from the merger of the two most popular packages for stream learning in Python: Creme and scikit-multiflow. River introduces a revamped architecture based on the lessons learnt from the seminal packages. River's ambition is to be the go-to library for doing machine learning on streaming data. Additionally, this open source package brings under the same umbrella a large community of practitioners and researchers. The source code is available at https://github.com/online-ml/river.
Adaptive XGBoost for Evolving Data Streams
May 15, 2020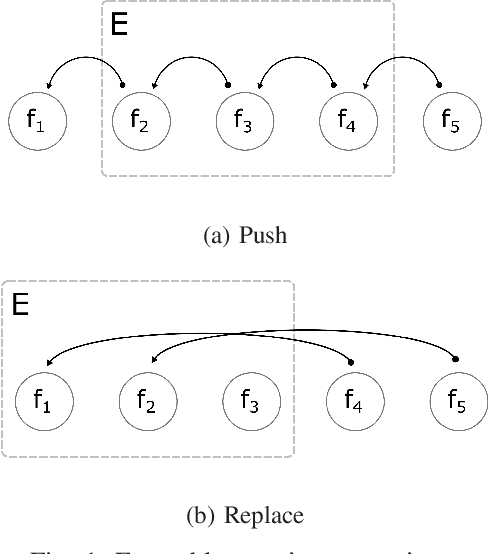
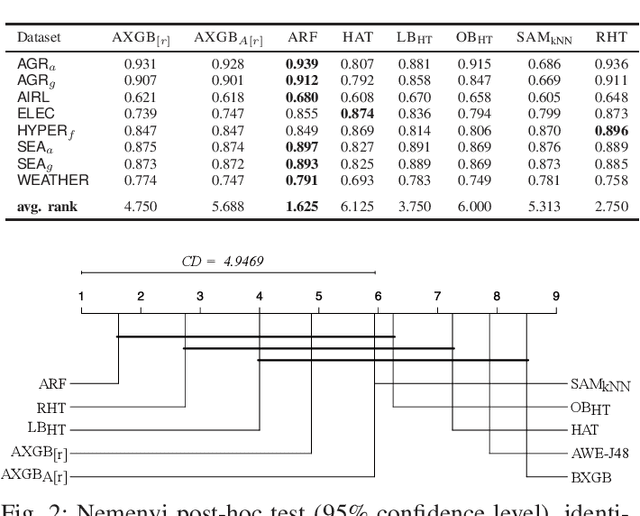
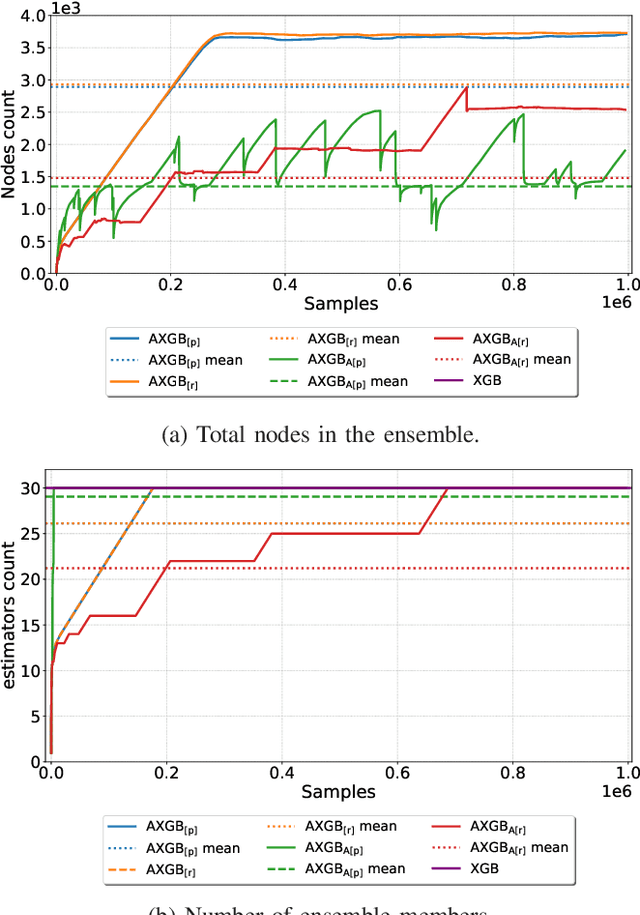
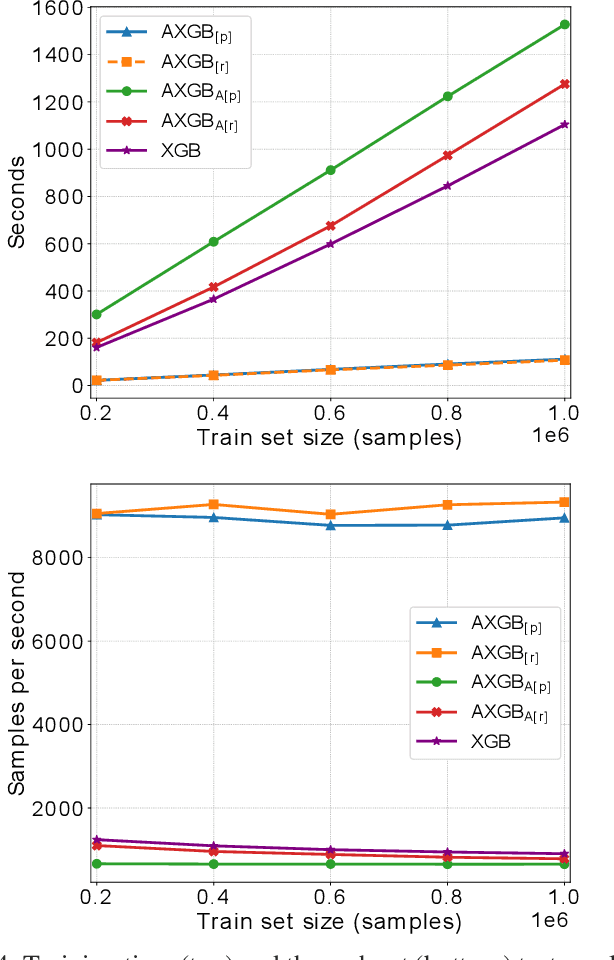
Boosting is an ensemble method that combines base models in a sequential manner to achieve high predictive accuracy. A popular learning algorithm based on this ensemble method is eXtreme Gradient Boosting (XGB). We present an adaptation of XGB for classification of evolving data streams. In this setting, new data arrives over time and the relationship between the class and the features may change in the process, thus exhibiting concept drift. The proposed method creates new members of the ensemble from mini-batches of data as new data becomes available. The maximum ensemble size is fixed, but learning does not stop when this size is reached because the ensemble is updated on new data to ensure consistency with the current concept. We also explore the use of concept drift detection to trigger a mechanism to update the ensemble. We test our method on real and synthetic data with concept drift and compare it against batch-incremental and instance-incremental classification methods for data streams.
Scikit-Multiflow: A Multi-output Streaming Framework
Jul 12, 2018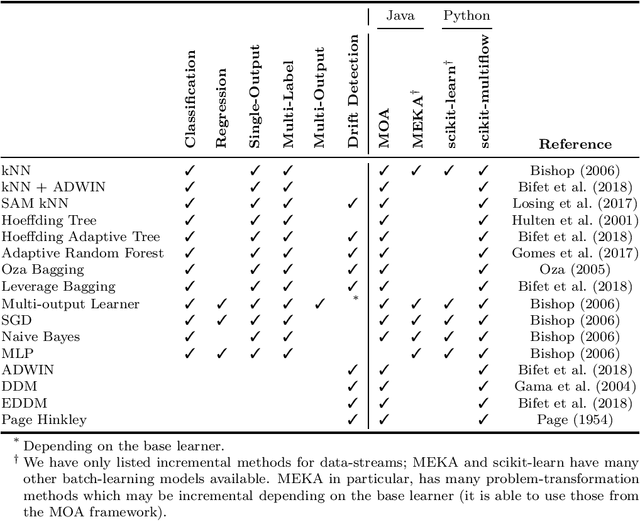
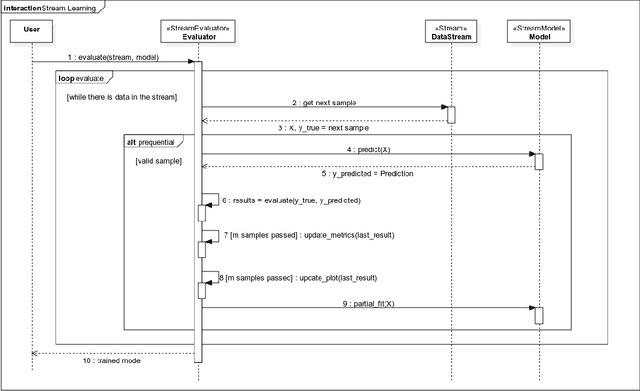
Scikit-multiflow is a multi-output/multi-label and stream data mining framework for the Python programming language. Conceived to serve as a platform to encourage democratization of stream learning research, it provides multiple state of the art methods for stream learning, stream generators and evaluators. scikit-multiflow builds upon popular open source frameworks including scikit-learn, MOA and MEKA. Development follows the FOSS principles and quality is enforced by complying with PEP8 guidelines and using continuous integration and automatic testing. The source code is publicly available at https://github.com/scikit-multiflow/scikit-multiflow.
Pessimistic Uplift Modeling
Apr 19, 2017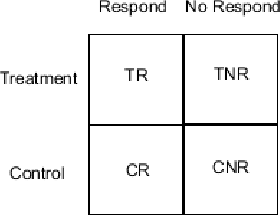
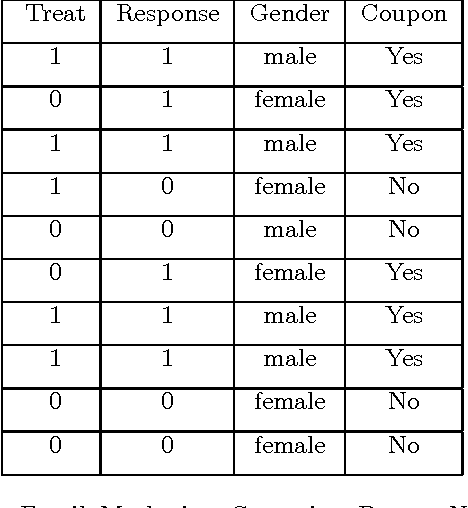
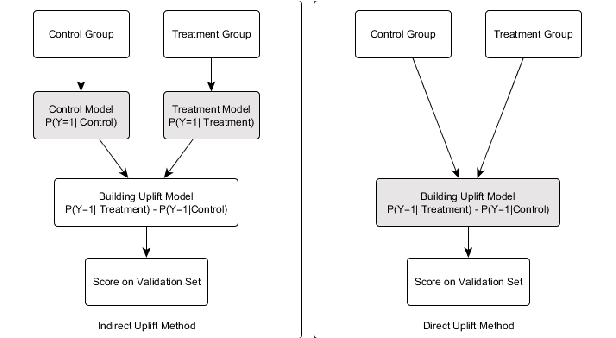
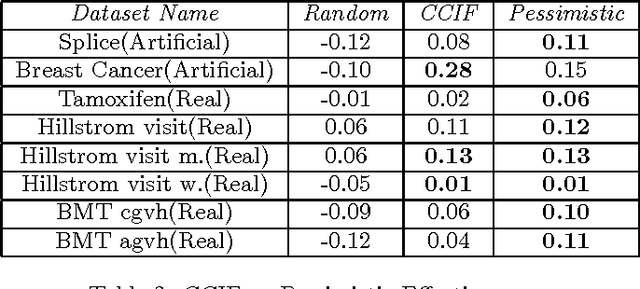
Uplift modeling is a machine learning technique that aims to model treatment effects heterogeneity. It has been used in business and health sectors to predict the effect of a specific action on a given individual. Despite its advantages, uplift models show high sensitivity to noise and disturbance, which leads to unreliable results. In this paper we show different approaches to address the problem of uplift modeling, we demonstrate how disturbance in data can affect uplift measurement. We propose a new approach, we call it Pessimistic Uplift Modeling, that minimizes disturbance effects. We compared our approach with the existing uplift methods, on simulated and real data-sets. The experiments show that our approach outperforms the existing approaches, especially in the case of high noise data environment.
Dynamic recommender system : using cluster-based biases to improve the accuracy of the predictions
Dec 03, 2012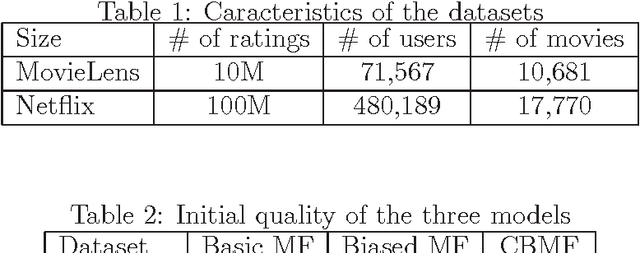
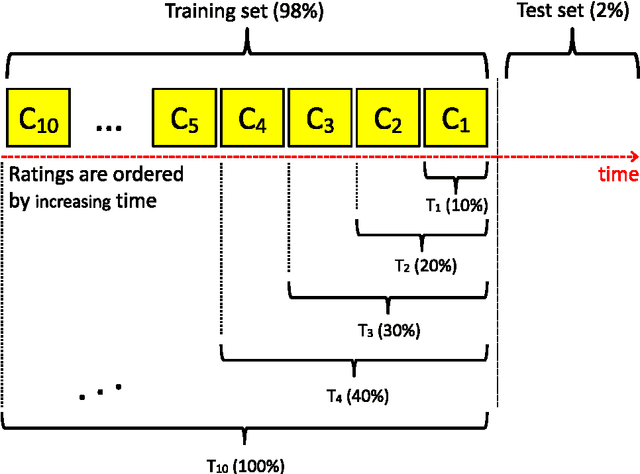
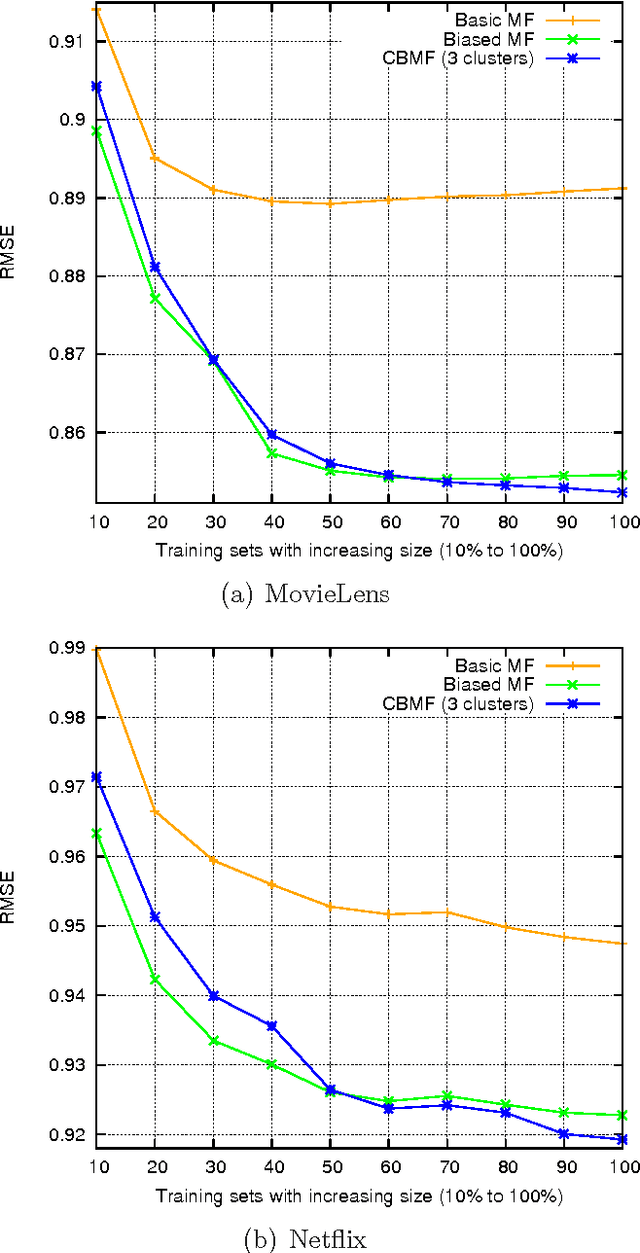

It is today accepted that matrix factorization models allow a high quality of rating prediction in recommender systems. However, a major drawback of matrix factorization is its static nature that results in a progressive declining of the accuracy of the predictions after each factorization. This is due to the fact that the new obtained ratings are not taken into account until a new factorization is computed, which can not be done very often because of the high cost of matrix factorization. In this paper, aiming at improving the accuracy of recommender systems, we propose a cluster-based matrix factorization technique that enables online integration of new ratings. Thus, we significantly enhance the obtained predictions between two matrix factorizations. We use finer-grained user biases by clustering similar items into groups, and allocating in these groups a bias to each user. The experiments we did on large datasets demonstrated the efficiency of our approach.