 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining the (Not So) Obvious: Simple and Fast Explanation of STAN, a Next Point of Interest Recommendation System
Oct 04, 2024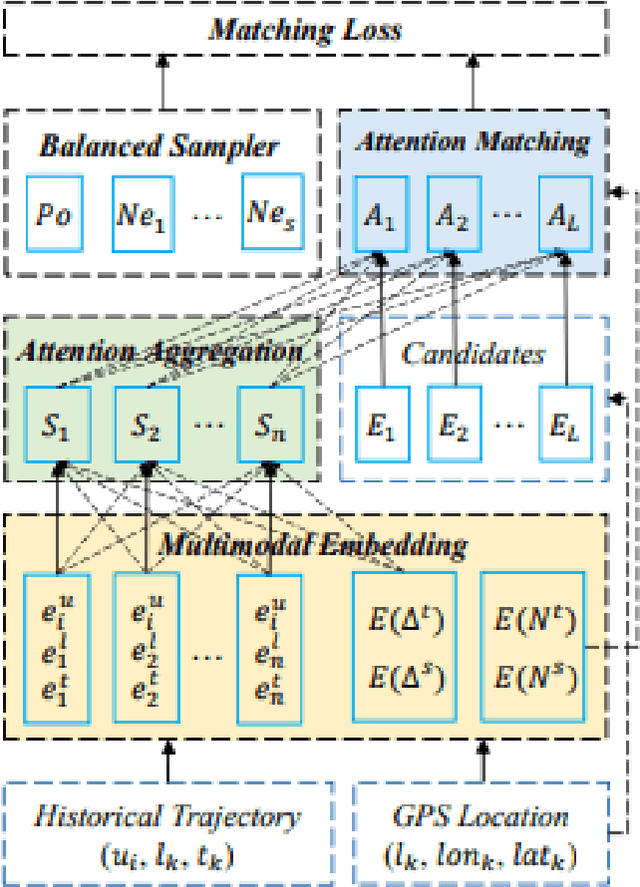
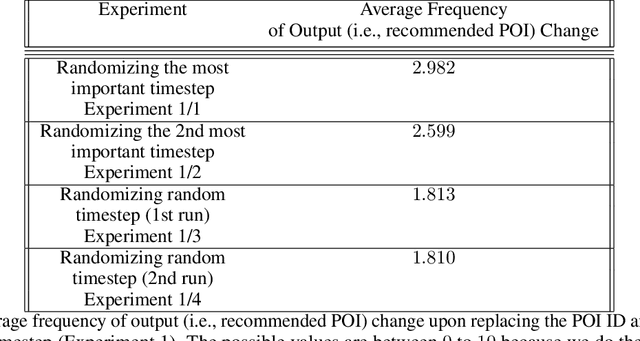
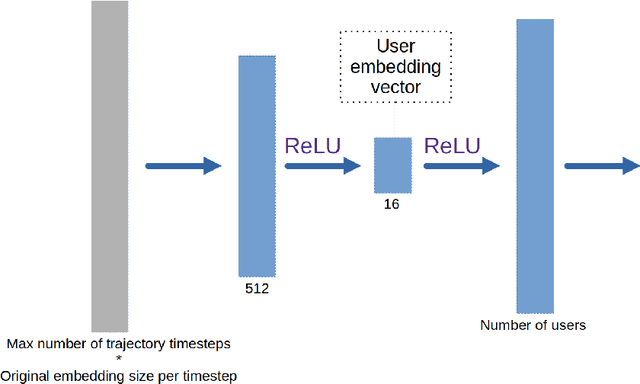

A lot of effort in recent years have been expended to explain machine learning systems. However, some machine learning methods are inherently explainable, and thus are not completely black box. This enables the developers to make sense of the output without a developing a complex and expensive explainability technique. Besides that, explainability should be tailored to suit the context of the problem. In a recommendation system which relies on collaborative filtering, the recommendation is based on the behaviors of similar users, therefore the explanation should tell which other users are similar to the current user. Similarly, if the recommendation system is based on sequence prediction, the explanation should also tell which input timesteps are the most influential. We demonstrate this philosophy/paradigm in STAN (Spatio-Temporal Attention Network for Next Location Recommendation), a next Point of Interest recommendation system based on collaborative filtering and sequence prediction. We also show that the explanation helps to "debug" the output.
Representation Learning of Image Schema
Jul 17, 2022

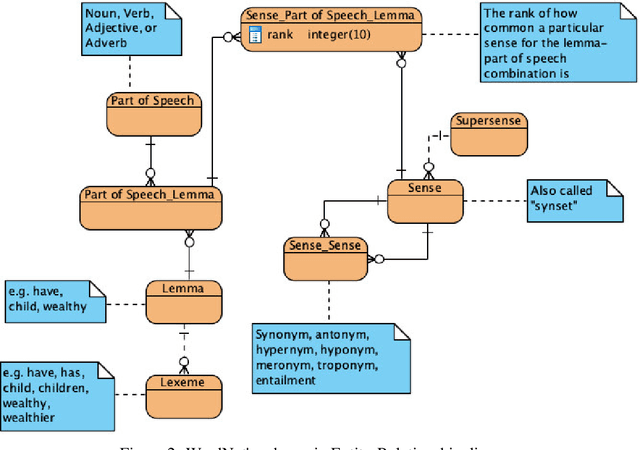
Image schema is a recurrent pattern of reasoning where one entity is mapped into another. Image schema is similar to conceptual metaphor and is also related to metaphoric gesture. Our main goal is to generate metaphoric gestures for an Embodied Conversational Agent. We propose a technique to learn the vector representation of image schemas. As far as we are aware of, this is the first work which addresses that problem. Our technique uses Ravenet et al's algorithm which we use to compute the image schemas from the text input and also BERT and SenseBERT which we use as the base word embedding technique to calculate the final vector representation of the image schema. Our representation learning technique works by clustering: word embedding vectors which belong to the same image schema should be relatively closer to each other, and thus form a cluster. With the image schemas representable as vectors, it also becomes possible to have a notion that some image schemas are closer or more similar to each other than to the others because the distance between the vectors is a proxy of the dissimilarity between the corresponding image schemas. Therefore, after obtaining the vector representation of the image schemas, we calculate the distances between those vectors. Based on these, we create visualizations to illustrate the relative distances between the different image schemas.
Sequence-to-Sequence Predictive Model: From Prosody To Communicative Gestures
Aug 17, 2020
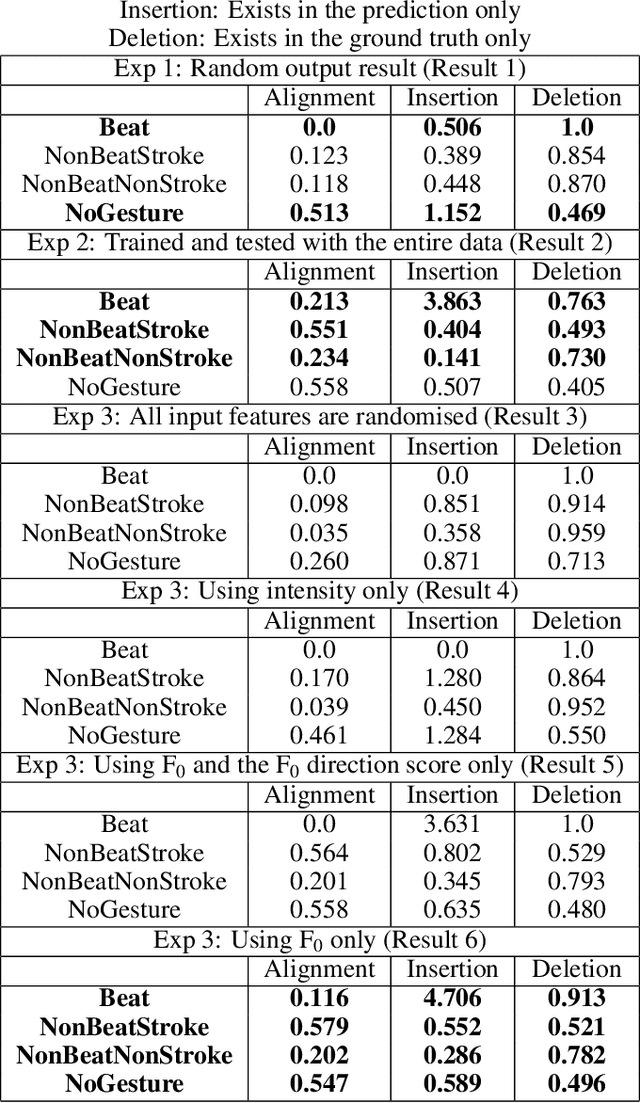
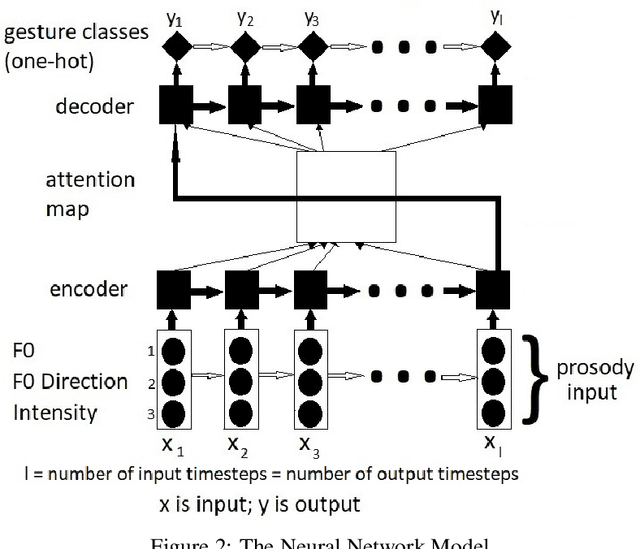
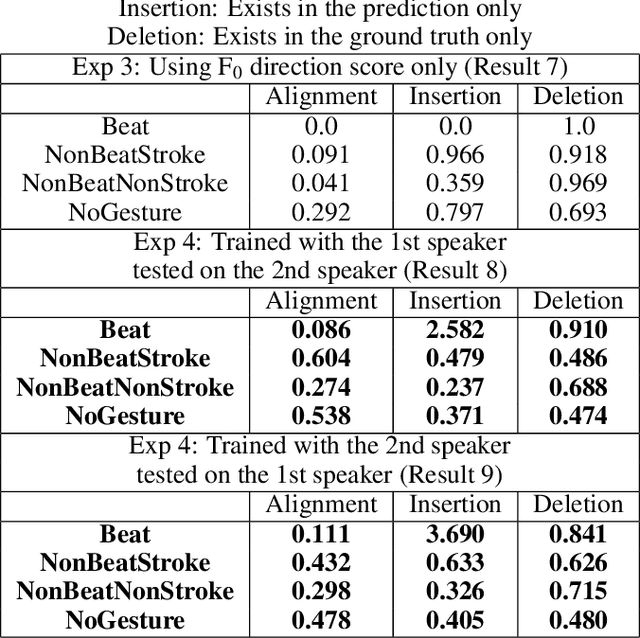
Communicative gestures and speech prosody are tightly linked. Our objective is to predict the timing of gestures according to the prosody. That is, we want to predict when a certain gesture occurs. We develop a model based on a recurrent neural network with attention mechanism. The model is trained on a corpus of natural dyadic interaction where the speech prosody and the gesture phases and types have been annotated. The input of the model is a sequence of speech prosody and the output is a sequence of gesture classes. The classes we are using for the model output is based on a combination of gesture phases and gesture types. We use a sequence comparison technique to evaluate the model performance. We find that the model can predict better certain gesture classes than others. We also perform ablation studies which reveal that fundamental frequency is a pertinent feature. We also find that a model trained on the data of one speaker only also works for the other speaker of the same conversation. Lastly, we also find that including eyebrow movements as a form of beat gesture improves the performance.