 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Predictive Model: From Prosody To Communicative Gestures
Paper and Code

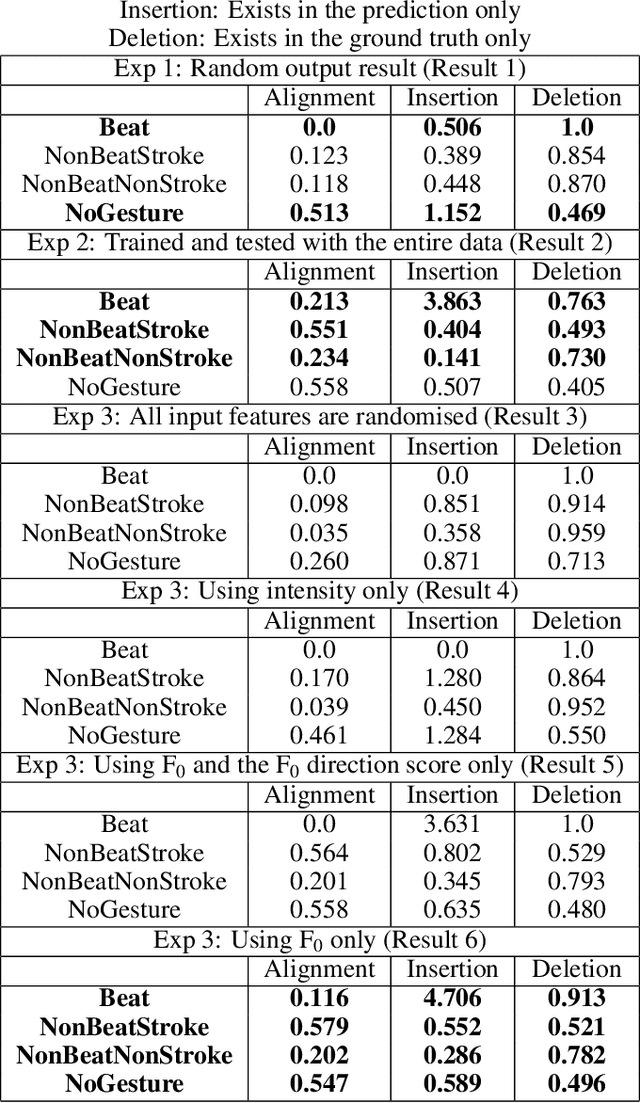
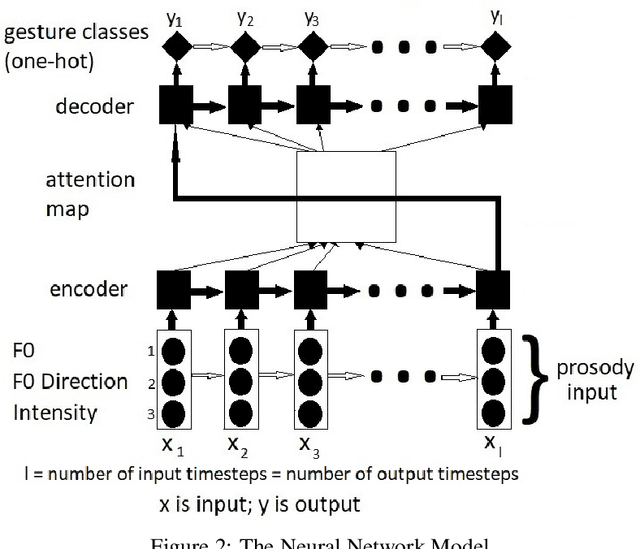
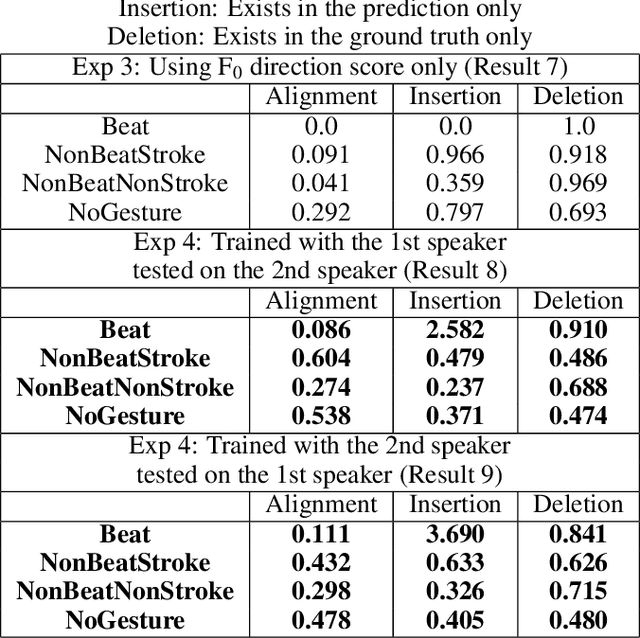
Communicative gestures and speech prosody are tightly linked. Our objective is to predict the timing of gestures according to the prosody. That is, we want to predict when a certain gesture occurs. We develop a model based on a recurrent neural network with attention mechanism. The model is trained on a corpus of natural dyadic interaction where the speech prosody and the gesture phases and types have been annotated. The input of the model is a sequence of speech prosody and the output is a sequence of gesture classes. The classes we are using for the model output is based on a combination of gesture phases and gesture types. We use a sequence comparison technique to evaluate the model performance. We find that the model can predict better certain gesture classes than others. We also perform ablation studies which reveal that fundamental frequency is a pertinent feature. We also find that a model trained on the data of one speaker only also works for the other speaker of the same conversation. Lastly, we also find that including eyebrow movements as a form of beat gesture improves the performance.