 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIITD at the WANLP 2022 Shared Task: Multilingual Multi-Granularity Network for Propaganda Detection
Paper and Code
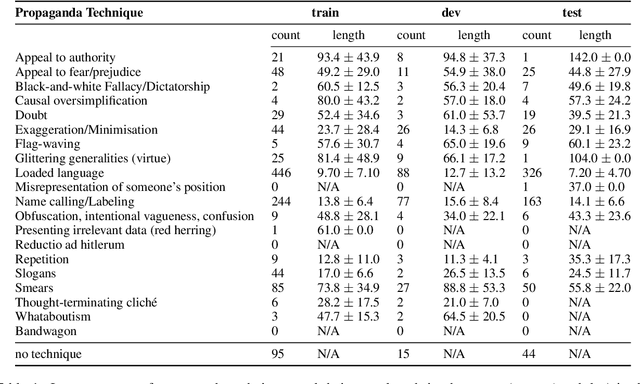
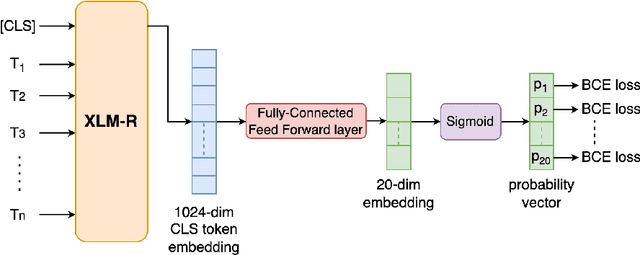
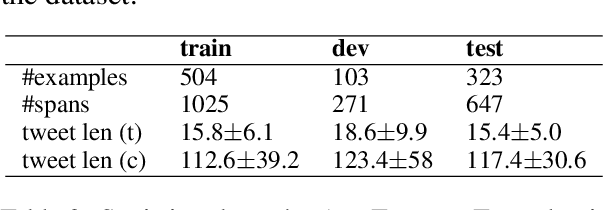
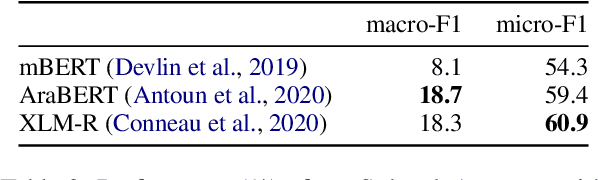
We present our system for the two subtasks of the shared task on propaganda detection in Arabic, part of WANLP'2022. Subtask 1 is a multi-label classification problem to find the propaganda techniques used in a given tweet. Our system for this task uses XLM-R to predict probabilities for the target tweet to use each of the techniques. In addition to finding the techniques, Subtask 2 further asks to identify the textual span for each instance of each technique that is present in the tweet; the task can be modeled as a sequence tagging problem. We use a multi-granularity network with mBERT encoder for Subtask 2. Overall, our system ranks second for both subtasks (out of 14 and 3 participants, respectively). Our empirical analysis show that it does not help to use a much larger English corpus annotated with propaganda techniques, regardless of whether used in English or after translation to Arabic.