 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Computational Hardness of Transformers
Mar 11, 2026The transformer has revolutionized modern AI across language, vision, and beyond. It consists of $L$ layers, each running $H$ attention heads in parallel and feeding the combined output to the subsequent layer. In attention, the input consists of $N$ tokens, each a vector of dimension $m$. The attention mechanism involves multiplying three $N \times m$ matrices, applying softmax to an intermediate product. Several recent works have advanced our understanding of the complexity of attention. Known algorithms for transformers compute each attention head independently. This raises a fundamental question that has recurred throughout TCS under the guise of ``direct sum'' problems: can multiple instances of the same problem be solved more efficiently than solving each instance separately? Many answers to this question, both positive and negative, have arisen in fields spanning communication complexity and algorithm design. Thus, we ask whether transformers can be computed more efficiently than $LH$ independent evaluations of attention. In this paper, we resolve this question in the negative, and give the first non-trivial computational lower bounds for multi-head multi-layer transformers. In the small embedding regime ($m = N^{o(1)}$), computing $LH$ attention heads separately takes $LHN^{2 + o(1)}$ time. We establish that this is essentially optimal under SETH. In the large embedding regime ($m = N$), one can compute $LH$ attention heads separately using $LHN^{ω+ o(1)}$ arithmetic operations (plus exponents), where $ω$ is the matrix multiplication exponent. We establish that this is optimal, by showing that $LHN^{ω- o(1)}$ arithmetic operations are necessary when $ω> 2$. Our lower bound in the large embedding regime relies on a novel application of the Baur-Strassen theorem, a powerful algorithmic tool underpinning the famous backpropagation algorithm.
From Generative to Episodic: Sample-Efficient Replicable Reinforcement Learning
Jul 16, 2025The epidemic failure of replicability across empirical science and machine learning has recently motivated the formal study of replicable learning algorithms [Impagliazzo et al. (2022)]. In batch settings where data comes from a fixed i.i.d. source (e.g., hypothesis testing, supervised learning), the design of data-efficient replicable algorithms is now more or less understood. In contrast, there remain significant gaps in our knowledge for control settings like reinforcement learning where an agent must interact directly with a shifting environment. Karbasi et. al show that with access to a generative model of an environment with $S$ states and $A$ actions (the RL 'batch setting'), replicably learning a near-optimal policy costs only $\tilde{O}(S^2A^2)$ samples. On the other hand, the best upper bound without a generative model jumps to $\tilde{O}(S^7 A^7)$ [Eaton et al. (2024)] due to the substantial difficulty of environment exploration. This gap raises a key question in the broader theory of replicability: Is replicable exploration inherently more expensive than batch learning? Is sample-efficient replicable RL even possible? In this work, we (nearly) resolve this problem (for low-horizon tabular MDPs): exploration is not a significant barrier to replicable learning! Our main result is a replicable RL algorithm on $\tilde{O}(S^2A)$ samples, bridging the gap between the generative and episodic settings. We complement this with a matching $\tilde{\Omega}(S^2A)$ lower bound in the generative setting (under the common parallel sampling assumption) and an unconditional lower bound in the episodic setting of $\tilde{\Omega}(S^2)$ showcasing the near-optimality of our algorithm with respect to the state space $S$.
Replicable Distribution Testing
Jul 03, 2025We initiate a systematic investigation of distribution testing in the framework of algorithmic replicability. Specifically, given independent samples from a collection of probability distributions, the goal is to characterize the sample complexity of replicably testing natural properties of the underlying distributions. On the algorithmic front, we develop new replicable algorithms for testing closeness and independence of discrete distributions. On the lower bound front, we develop a new methodology for proving sample complexity lower bounds for replicable testing that may be of broader interest. As an application of our technique, we establish near-optimal sample complexity lower bounds for replicable uniformity testing -- answering an open question from prior work -- and closeness testing.
Subquadratic Algorithms and Hardness for Attention with Any Temperature
May 20, 2025


Despite the popularity of the Transformer architecture, the standard algorithm for computing Attention suffers from quadratic time complexity in context length $n$. Alman and Song [NeurIPS 2023] showed that when the head dimension $d = \Theta(\log n)$, subquadratic Attention is possible if and only if the inputs have small entries bounded by $B = o(\sqrt{\log n})$ in absolute values, under the Strong Exponential Time Hypothesis ($\mathsf{SETH}$). Equivalently, subquadratic Attention is possible if and only if the softmax is applied with high temperature for $d=\Theta(\log n)$. Running times of these algorithms depend exponentially on $B$ and thus they do not lead to even a polynomial-time algorithm outside the specific range of $B$. This naturally leads to the question: when can Attention be computed efficiently without strong assumptions on temperature? Are there fast attention algorithms that scale polylogarithmically with entry size $B$? In this work, we resolve this question and characterize when fast Attention for arbitrary temperatures is possible. First, for all constant $d = O(1)$, we give the first subquadratic $\tilde{O}(n^{2 - 1/d} \cdot \mathrm{polylog}(B))$ time algorithm for Attention with large $B$. Our result holds even for matrices with large head dimension if they have low rank. In this regime, we also give a similar running time for Attention gradient computation, and therefore for the full LLM training process. Furthermore, we show that any substantial improvement on our algorithm is unlikely. In particular, we show that even when $d = 2^{\Theta(\log^* n)}$, Attention requires $n^{2 - o(1)}$ time under $\mathsf{SETH}$. Finally, in the regime where $d = \mathrm{poly}(n)$, we show that the standard algorithm is optimal under popular fine-grained complexity assumptions.
Replicable Uniformity Testing
Oct 12, 2024Uniformity testing is arguably one of the most fundamental distribution testing problems. Given sample access to an unknown distribution $\mathbf{p}$ on $[n]$, one must decide if $\mathbf{p}$ is uniform or $\varepsilon$-far from uniform (in total variation distance). A long line of work established that uniformity testing has sample complexity $\Theta(\sqrt{n}\varepsilon^{-2})$. However, when the input distribution is neither uniform nor far from uniform, known algorithms may have highly non-replicable behavior. Consequently, if these algorithms are applied in scientific studies, they may lead to contradictory results that erode public trust in science. In this work, we revisit uniformity testing under the framework of algorithmic replicability [STOC '22], requiring the algorithm to be replicable under arbitrary distributions. While replicability typically incurs a $\rho^{-2}$ factor overhead in sample complexity, we obtain a replicable uniformity tester using only $\tilde{O}(\sqrt{n} \varepsilon^{-2} \rho^{-1})$ samples. To our knowledge, this is the first replicable learning algorithm with (nearly) linear dependence on $\rho$. Lastly, we consider a class of ``symmetric" algorithms [FOCS '00] whose outputs are invariant under relabeling of the domain $[n]$, which includes all existing uniformity testers (including ours). For this natural class of algorithms, we prove a nearly matching sample complexity lower bound for replicable uniformity testing.
Replicability in High Dimensional Statistics
Jun 04, 2024The replicability crisis is a major issue across nearly all areas of empirical science, calling for the formal study of replicability in statistics. Motivated in this context, [Impagliazzo, Lei, Pitassi, and Sorrell STOC 2022] introduced the notion of replicable learning algorithms, and gave basic procedures for $1$-dimensional tasks including statistical queries. In this work, we study the computational and statistical cost of replicability for several fundamental high dimensional statistical tasks, including multi-hypothesis testing and mean estimation. Our main contribution establishes a computational and statistical equivalence between optimal replicable algorithms and high dimensional isoperimetric tilings. As a consequence, we obtain matching sample complexity upper and lower bounds for replicable mean estimation of distributions with bounded covariance, resolving an open problem of [Bun, Gaboardi, Hopkins, Impagliazzo, Lei, Pitassi, Sivakumar, and Sorrell, STOC2023] and for the $N$-Coin Problem, resolving a problem of [Karbasi, Velegkas, Yang, and Zhou, NeurIPS2023] up to log factors. While our equivalence is computational, allowing us to shave log factors in sample complexity from the best known efficient algorithms, efficient isoperimetric tilings are not known. To circumvent this, we introduce several relaxed paradigms that do allow for sample and computationally efficient algorithms, including allowing pre-processing, adaptivity, and approximate replicability. In these cases we give efficient algorithms matching or beating the best known sample complexity for mean estimation and the coin problem, including a generic procedure that reduces the standard quadratic overhead of replicability to linear in expectation.
The I/O Complexity of Attention, or How Optimal is Flash Attention?
Feb 12, 2024Self-attention is at the heart of the popular Transformer architecture, yet suffers from quadratic time and memory complexity. The breakthrough FlashAttention algorithm revealed I/O complexity as the true bottleneck in scaling Transformers. Given two levels of memory hierarchy, a fast cache (e.g. GPU on-chip SRAM) and a slow memory (e.g. GPU high-bandwidth memory), the I/O complexity measures the number of accesses to memory. FlashAttention computes attention using $\frac{N^2d^2}{M}$ I/O operations where $N$ is the dimension of the attention matrix, $d$ the head-dimension and $M$ the cache size. However, is this I/O complexity optimal? The known lower bound only rules out an I/O complexity of $o(Nd)$ when $M=\Theta(Nd)$, since the output that needs to be written to slow memory is $\Omega(Nd)$. This leads to the main question of our work: Is FlashAttention I/O optimal for all values of $M$? We resolve the above question in its full generality by showing an I/O complexity lower bound that matches the upper bound provided by FlashAttention for any values of $M \geq d^2$ within any constant factors. Further, we give a better algorithm with lower I/O complexity for $M < d^2$, and show that it is optimal as well. Moreover, our lower bounds do not rely on using combinatorial matrix multiplication for computing the attention matrix. We show even if one uses fast matrix multiplication, the above I/O complexity bounds cannot be improved. We do so by introducing a new communication complexity protocol for matrix compression, and connecting communication complexity to I/O complexity. To the best of our knowledge, this is the first work to establish a connection between communication complexity and I/O complexity, and we believe this connection could be of independent interest and will find many more applications in proving I/O complexity lower bounds in the future.
Predicting the Stereoselectivity of Chemical Transformations by Machine Learning
Oct 12, 2021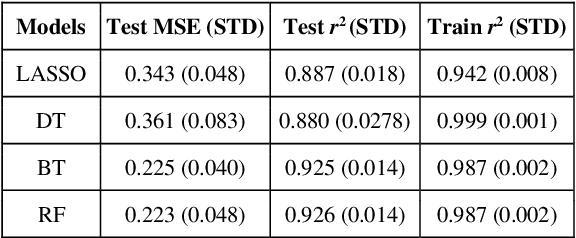
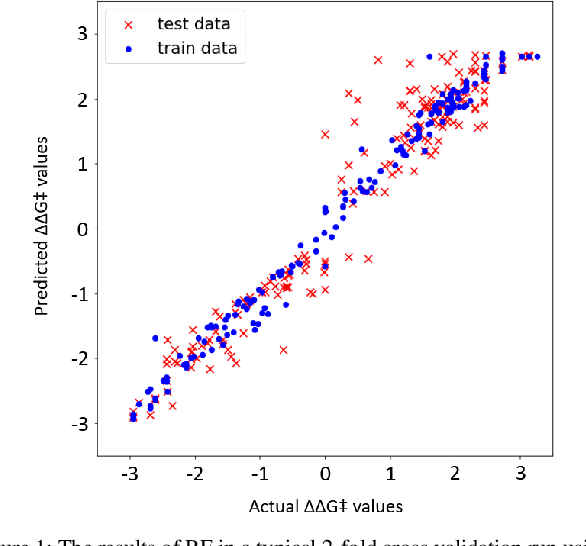
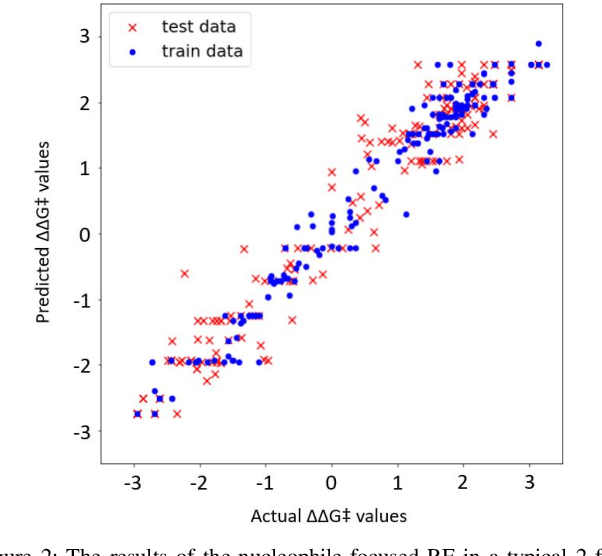
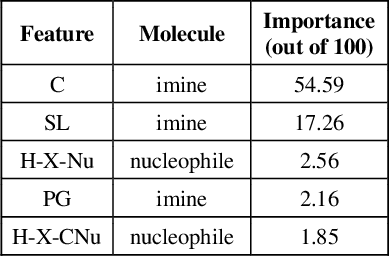
Stereoselective reactions (both chemical and enzymatic reactions) have been essential for origin of life, evolution, human biology and medicine. Since late 1960s, there have been numerous successes in the exciting new frontier of asymmetric catalysis. However, most industrial and academic asymmetric catalysis nowadays do follow the trial-and-error model, since the energetic difference for success or failure in asymmetric catalysis is incredibly small. Our current understanding about stereoselective reactions is mostly qualitative that stereoselectivity arises from differences in steric effects and electronic effects in multiple competing mechanistic pathways. Quantitatively understanding and modulating the stereoselectivity of for a given chemical reaction still remains extremely difficult. As a proof of principle, we herein present a novel machine learning technique, which combines a LASSO model and two Random Forest model via two Gaussian Mixture models, for quantitatively predicting stereoselectivity of chemical reactions. Compared to the recent ground-breaking approach [1], our approach is able to capture interactions between features and exploit complex data distributions, which are important for predicting stereoselectivity. Experimental results on a recently published dataset demonstrate that our approach significantly outperform [1]. The insight obtained from our results provide a solid foundation for further exploration of other synthetically valuable yet mechanistically intriguing stereoselective reactions.