 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Retrieval Models for Stripped Binary Analysis
Dec 11, 2025
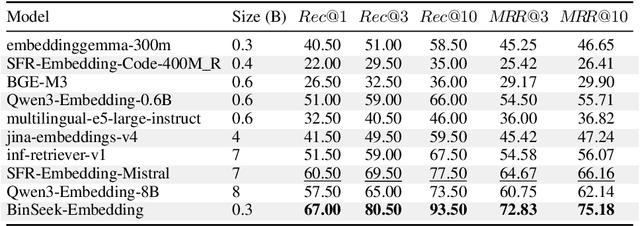
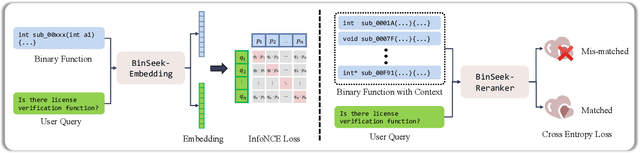
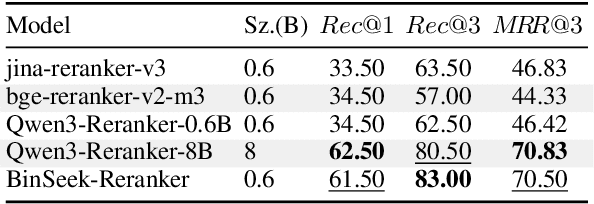
LLM-agent based binary code analysis has demonstrated significant potential across a wide range of software security scenarios, including vulnerability detection, malware analysis, etc. In agent workflow, however, retrieving the positive from thousands of stripped binary functions based on user query remains under-studied and challenging, as the absence of symbolic information distinguishes it from source code retrieval. In this paper, we introduce, BinSeek, the first two-stage cross-modal retrieval framework for stripped binary code analysis. It consists of two models: BinSeekEmbedding is trained on large-scale dataset to learn the semantic relevance of the binary code and the natural language description, furthermore, BinSeek-Reranker learns to carefully judge the relevance of the candidate code to the description with context augmentation. To this end, we built an LLM-based data synthesis pipeline to automate training construction, also deriving a domain benchmark for future research. Our evaluation results show that BinSeek achieved the state-of-the-art performance, surpassing the the same scale models by 31.42% in Rec@3 and 27.17% in MRR@3, as well as leading the advanced general-purpose models that have 16 times larger parameters.
Acoustic modeling for Overlapping Speech Recognition: JHU Chime-5 Challenge System
May 17, 2024This paper summarizes our acoustic modeling efforts in the Johns Hopkins University speech recognition system for the CHiME-5 challenge to recognize highly-overlapped dinner party speech recorded by multiple microphone arrays. We explore data augmentation approaches, neural network architectures, front-end speech dereverberation, beamforming and robust i-vector extraction with comparisons of our in-house implementations and publicly available tools. We finally achieved a word error rate of 69.4% on the development set, which is a 11.7% absolute improvement over the previous baseline of 81.1%, and release this improved baseline with refined techniques/tools as an advanced CHiME-5 recipe.
* Published in: ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
LMTuner: An user-friendly and highly-integrable Training Framework for fine-tuning Large Language Models
Aug 20, 2023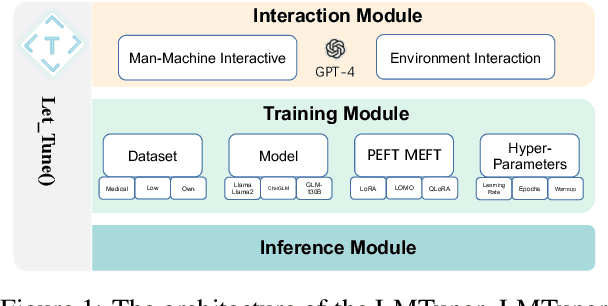
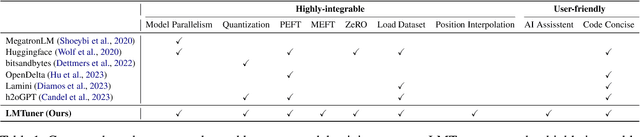
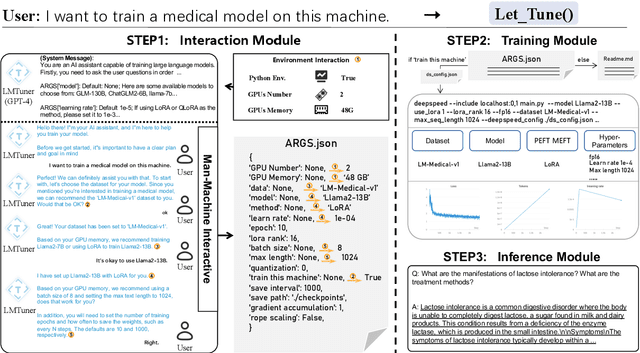
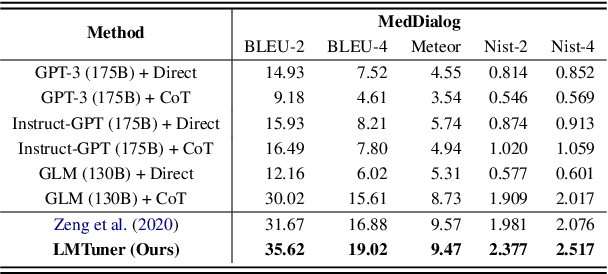
With the burgeoning development in the realm of large language models (LLMs), the demand for efficient incremental training tailored to specific industries and domains continues to increase. Currently, the predominantly employed frameworks lack modular design, it often takes a lot of coding work to kickstart the training of LLM. To address this, we present "LMTuner", a highly usable, integrable, and scalable system for training LLMs expeditiously and with minimal user-input. LMTuner comprises three main modules - the Interaction, Training, and Inference Modules. We advocate that LMTuner's usability and integrality alleviate the complexities in training large language models. Remarkably, even a novice user could commence training large language models within five minutes. Furthermore, it integrates DeepSpeed frameworks and supports Efficient Fine-Tuning methodologies like Low Rank Adaptation (LoRA), Quantized LoRA (QLoRA), etc., enabling the training of language models scaling from 300M to a whopping 130B parameters using a single server. The LMTuner's homepage (https://wengsyx.github.io/LMTuner/)and screencast video (https://youtu.be/nsXmWOmN3rE) are now publicly available.
Mixline: A Hybrid Reinforcement Learning Framework for Long-horizon Bimanual Coffee Stirring Task
Nov 04, 2022Bimanual activities like coffee stirring, which require coordination of dual arms, are common in daily life and intractable to learn by robots. Adopting reinforcement learning to learn these tasks is a promising topic since it enables the robot to explore how dual arms coordinate together to accomplish the same task. However, this field has two main challenges: coordination mechanism and long-horizon task decomposition. Therefore, we propose the Mixline method to learn sub-tasks separately via the online algorithm and then compose them together based on the generated data through the offline algorithm. We constructed a learning environment based on the GPU-accelerated Isaac Gym. In our work, the bimanual robot successfully learned to grasp, hold and lift the spoon and cup, insert them together and stir the coffee. The proposed method has the potential to be extended to other long-horizon bimanual tasks.
* 10 pages, conference
A Data-driven Storage Control Framework for Dynamic Pricing
Dec 01, 2019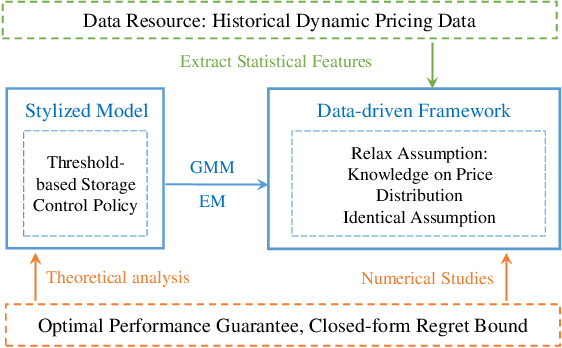
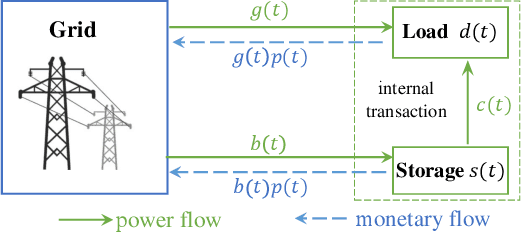
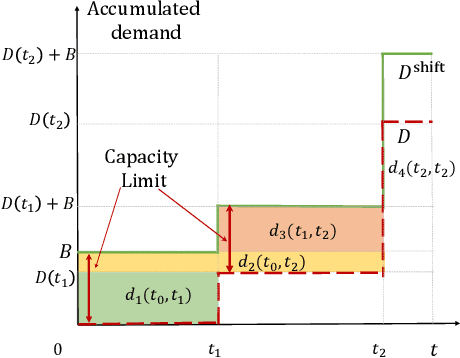
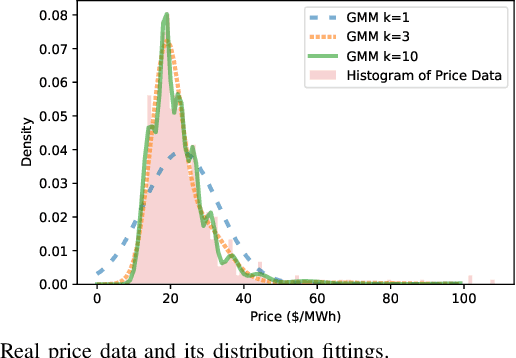
Dynamic pricing is both an opportunity and a challenge to the demand side. It is an opportunity as it better reflects the real time market conditions and hence enables an active demand side. However, demand's active participation does not necessarily lead to benefits. The challenge conventionally comes from the limited flexible resources and limited intelligent devices in demand side. The decreasing cost of storage system and the widely deployed smart meters inspire us to design a data-driven storage control framework for dynamic prices. We first establish a stylized model by assuming the knowledge and structure of dynamic price distributions, and design the optimal storage control policy. Based on Gaussian Mixture Model, we propose a practical data-driven control framework, which helps relax the assumptions in the stylized model. Numerical studies illustrate the remarkable performance of the proposed data-driven framework.