 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of LLM Tool Calling via Experiential Knowledge Integration and Activation
Jun 09, 2026Large language models (LLMs) rely on tool use to act as autonomous agents, yet often fail in multi-step execution due to insufficient tool-related knowledge and ineffective knowledge activation. Therefore, we present a systematic study on how knowledge influences tool-use performance, covering the stages of knowledge acquisition, activation, and internalization. In the knowledge acquisition stage, we acquire and evaluate various forms of experiential knowledge, and our analysis shows that simple instance-level knowledge can already provide strong and reliable gains, while abstract intent-level knowledge offers limited benefits. At inference time, to activate knowledge, we find that prompting LLM to expand the depth of reasoning yields diminishing returns, whereas expanding the width of reasoning by parallel sampling with aggregation more effectively activates latent experiential knowledge. At training time, for knowledge internalization, post-training with knowledge-augmented data further improves performance, with reinforcement learning outperforming supervised fine-tuning. Based on these insights, we propose the Knowledge-Augmented Tool Execution (KATE), a knowledge-augmented tool execution framework that integrates experiential knowledge with reasoning-width-expanded inference and knowledge-aware training. Experiments on BFCL-V3 and AppWorld demonstrate consistent and substantial improvements over strong baselines across model scales. Our Code is available at https://github.com/hypasd-art/KATE.
ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
Mar 31, 2026Multimodal Large Language Models (MLLMs) achieve stronger visual understanding by scaling input fidelity, yet the resulting visual token growth makes jointly sustaining high spatial resolution and long temporal context prohibitive. We argue that the bottleneck lies not in how post-encoding representations are compressed but in the volume of pixels the encoder receives, and address it with ResAdapt, an Input-side adaptation framework that learns how much visual budget each frame should receive before encoding. ResAdapt couples a lightweight Allocator with an unchanged MLLM backbone, so the backbone retains its native visual-token interface while receiving an operator-transformed input. We formulate allocation as a contextual bandit and train the Allocator with Cost-Aware Policy Optimization (CAPO), which converts sparse rollout feedback into a stable accuracy-cost learning signal. Across budget-controlled video QA, temporal grounding, and image reasoning tasks, ResAdapt improves low-budget operating points and often lies on or near the efficiency-accuracy frontier, with the clearest gains on reasoning-intensive benchmarks under aggressive compression. Notably, ResAdapt supports up to 16x more frames at the same visual budget while delivering over 15% performance gain. Code is available at https://github.com/Xnhyacinth/ResAdapt.
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Dec 22, 2025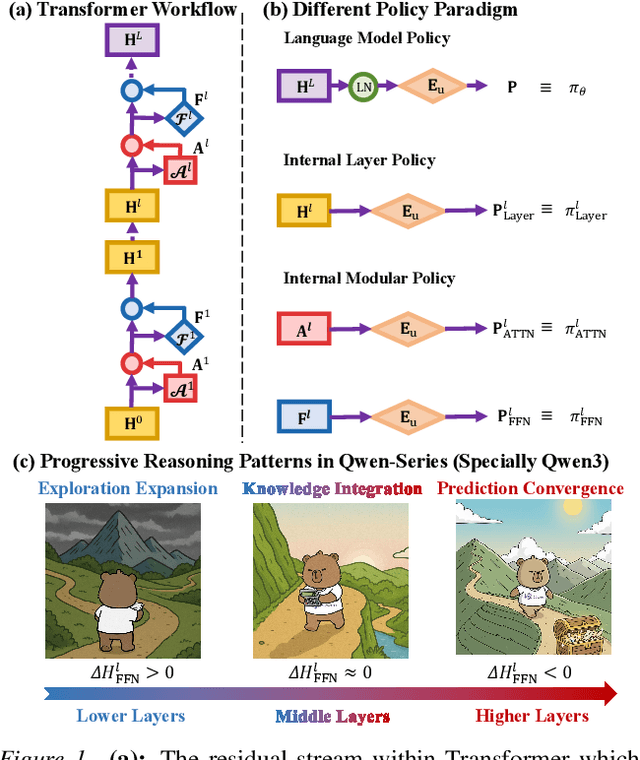
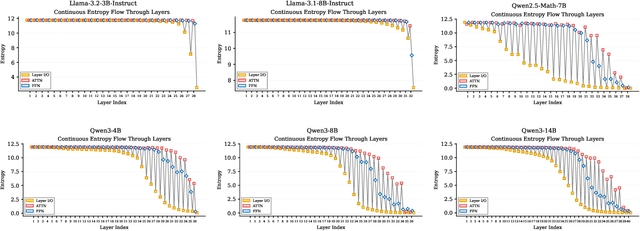
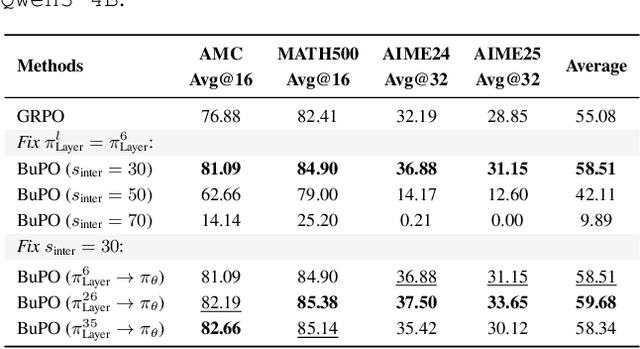
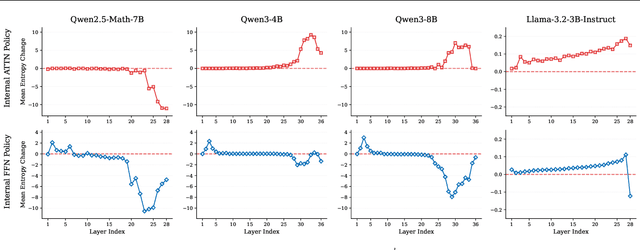
Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the language model policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning
Aug 21, 2025Long-context inference in large language models (LLMs) is increasingly constrained by the KV cache bottleneck: memory usage grows linearly with sequence length, while attention computation scales quadratically. Existing approaches address this issue by compressing the KV cache along the temporal axis through strategies such as token eviction or merging to reduce memory and computational overhead. However, these methods often neglect fine-grained importance variations across feature dimensions (i.e., the channel axis), thereby limiting their ability to effectively balance efficiency and model accuracy. In reality, we observe that channel saliency varies dramatically across both queries and positions: certain feature channels carry near-zero information for a given query, while others spike in relevance. To address this oversight, we propose SPARK, a training-free plug-and-play method that applies unstructured sparsity by pruning KV at the channel level, while dynamically restoring the pruned entries during attention score computation. Notably, our approach is orthogonal to existing KV compression and quantization techniques, making it compatible for integration with them to achieve further acceleration. By reducing channel-level redundancy, SPARK enables processing of longer sequences within the same memory budget. For sequences of equal length, SPARK not only preserves or improves model accuracy but also reduces KV cache storage by over 30% compared to eviction-based methods. Furthermore, even with an aggressive pruning ratio of 80%, SPARK maintains performance with less degradation than 5% compared to the baseline eviction method, demonstrating its robustness and effectiveness. Our code will be available at https://github.com/Xnhyacinth/SparK.
Beyond Hard and Soft: Hybrid Context Compression for Balancing Local and Global Information Retention
May 21, 2025Large Language Models (LLMs) encounter significant challenges in long-sequence inference due to computational inefficiency and redundant processing, driving interest in context compression techniques. Existing methods often rely on token importance to perform hard local compression or encode context into latent representations for soft global compression. However, the uneven distribution of textual content relevance and the diversity of demands for user instructions mean these approaches frequently lead to the loss of potentially valuable information. To address this, we propose $\textbf{Hy}$brid $\textbf{Co}$ntext $\textbf{Co}$mpression (HyCo$_2$) for LLMs, which integrates both global and local perspectives to guide context compression while retaining both the essential semantics and critical details for task completion. Specifically, we employ a hybrid adapter to refine global semantics with the global view, based on the observation that different adapters excel at different tasks. Then we incorporate a classification layer that assigns a retention probability to each context token based on the local view, determining whether it should be retained or discarded. To foster a balanced integration of global and local compression, we introduce auxiliary paraphrasing and completion pretraining before instruction tuning. This promotes a synergistic integration that emphasizes instruction-relevant information while preserving essential local details, ultimately balancing local and global information retention in context compression. Experiments show that our HyCo$_2$ method significantly enhances long-text reasoning while reducing token usage. It improves the performance of various LLM series by an average of 13.1\% across seven knowledge-intensive QA benchmarks. Moreover, HyCo$_2$ matches the performance of uncompressed methods while reducing token consumption by 88.8\%.
Better wit than wealth: Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement
Mar 31, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving relevant documents from external sources and incorporating them into the context. While it improves reliability by providing factual texts, it significantly increases inference costs as context length grows and introduces challenging issue of RAG hallucination, primarily caused by the lack of corresponding parametric knowledge in LLMs. An efficient solution is to enhance the knowledge of LLMs at test-time. Parametric RAG (PRAG) addresses this by embedding document into LLMs parameters to perform test-time knowledge enhancement, effectively reducing inference costs through offline training. However, its high training and storage costs, along with limited generalization ability, significantly restrict its practical adoption. To address these challenges, we propose Dynamic Parametric RAG (DyPRAG), a novel framework that leverages a lightweight parameter translator model to efficiently convert documents into parametric knowledge. DyPRAG not only reduces inference, training, and storage costs but also dynamically generates parametric knowledge, seamlessly enhancing the knowledge of LLMs and resolving knowledge conflicts in a plug-and-play manner at test-time. Extensive experiments on multiple datasets demonstrate the effectiveness and generalization capabilities of DyPRAG, offering a powerful and practical RAG paradigm which enables superior knowledge fusion and mitigates RAG hallucination in real-world applications. Our code is available at https://github.com/Trae1ounG/DyPRAG.
DATA: Decomposed Attention-based Task Adaptation for Rehearsal-Free Continual Learning
Feb 17, 2025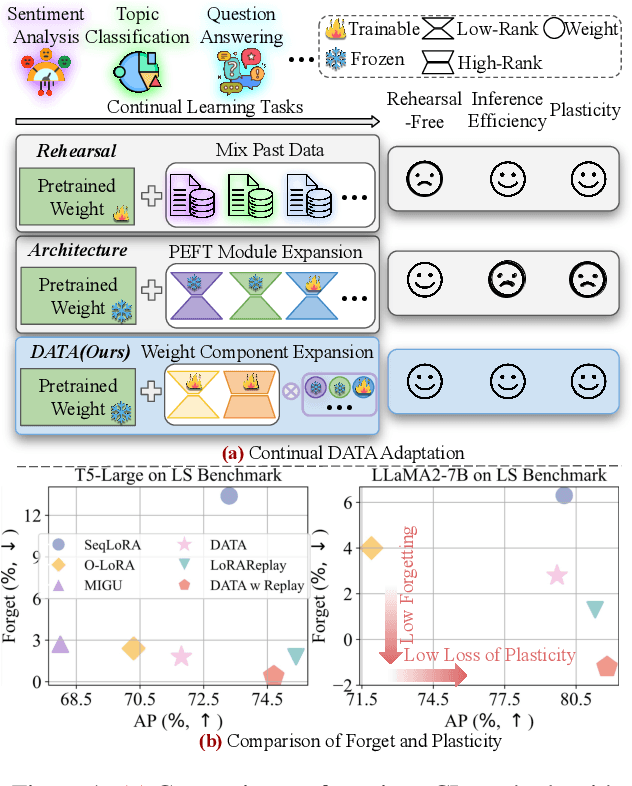
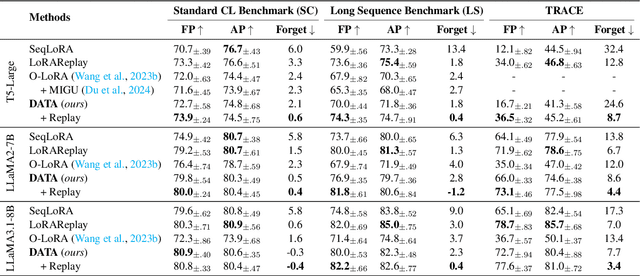
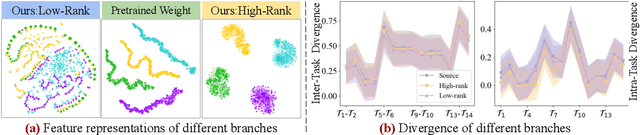
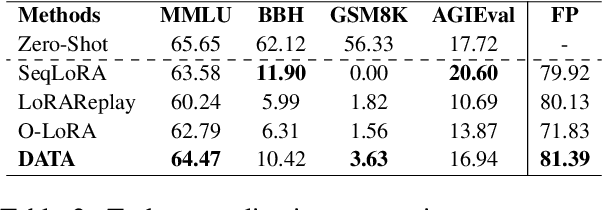
Continual learning (CL) is essential for Large Language Models (LLMs) to adapt to evolving real-world demands, yet they are susceptible to catastrophic forgetting (CF). While traditional CF solutions rely on expensive data rehearsal, recent rehearsal-free methods employ model-based and regularization-based strategies to address this issue. However, these approaches often neglect the model's plasticity, which is crucial to achieving optimal performance on newly learned tasks. Consequently, a key challenge in CL is striking a balance between preserving plasticity and mitigating CF. To tackle this challenge, we propose the $\textbf{D}$ecomposed $\textbf{A}$ttention-based $\textbf{T}$ask $\textbf{A}$daptation (DATA), which explicitly decouples and learns both task-specific and task-shared knowledge using high-rank and low-rank task adapters (e.g., LoRAs). For new tasks, DATA dynamically adjusts the weights of adapters of different ranks based on their relevance and distinction from previous tasks, allowing the model to acquire new task-specific skills while effectively retaining previously learned knowledge. Specifically, we implement a decomposed component weighting strategy comprising learnable components that collectively generate attention-based weights, allowing the model to integrate and utilize diverse knowledge from each DATA. Extensive experiments on three widely used benchmarks demonstrate that our proposed method achieves state-of-the-art performance. Notably, our approach significantly enhances model plasticity and mitigates CF by extending learnable components and employing stochastic restoration during training iterations.
VaiBot: Shuttle Between the Instructions and Parameters
Feb 04, 2025How to interact with LLMs through \emph{instructions} has been widely studied by researchers. However, previous studies have treated the emergence of instructions and the training of LLMs on task data as separate processes, overlooking the inherent unity between the two. This paper proposes a neural network framework, VaiBot, that integrates VAE and VIB, designed to uniformly model, learn, and infer both deduction and induction tasks under LLMs. Through experiments, we demonstrate that VaiBot performs on par with existing baseline methods in terms of deductive capabilities while significantly surpassing them in inductive capabilities. We also find that VaiBot can scale up using general instruction-following data and exhibits excellent one-shot induction abilities. We finally synergistically integrate the deductive and inductive processes of VaiBot. Through T-SNE dimensionality reduction, we observe that its inductive-deductive process significantly improves the distribution of training parameters, enabling it to outperform baseline methods in inductive reasoning tasks. The code and data for this paper can be found at https://anonymous.4open.science/r/VaiBot-021F.
From Instance Training to Instruction Learning: Task Adapters Generation from Instructions
Jun 18, 2024



Large language models (LLMs) have acquired the ability to solve general tasks by utilizing instruction finetuning (IFT). However, IFT still relies heavily on instance training of extensive task data, which greatly limits the adaptability of LLMs to real-world scenarios where labeled task instances are scarce and broader task generalization becomes paramount. Contrary to LLMs, humans acquire skills and complete tasks not merely through repeated practice but also by understanding and following instructional guidelines. This paper is dedicated to simulating human learning to address the shortcomings of instance training, focusing on instruction learning to enhance cross-task generalization. Within this context, we introduce Task Adapters Generation from Instructions (TAGI), which automatically constructs the task-specific model in a parameter generation manner based on the given task instructions without retraining for unseen tasks. Specifically, we utilize knowledge distillation to enhance the consistency between TAGI developed through Learning with Instruction and task-specific models developed through Training with Instance, by aligning the labels, output logits, and adapter parameters between them. TAGI is endowed with cross-task generalization capabilities through a two-stage training process that includes hypernetwork pretraining and finetuning. We evaluate TAGI on the Super-Natural Instructions and P3 datasets. The experimental results demonstrate that TAGI can match or even outperform traditional meta-trained models and other hypernetwork models, while significantly reducing computational requirements.
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
Mar 28, 2024



Retrieval-Augmented-Generation and Gener-ation-Augmented-Generation have been proposed to enhance the knowledge required for question answering over Large Language Models (LLMs). However, the former depends on external resources, and both require incorporating the explicit documents into the context, which results in longer contexts that lead to more resource consumption. Recent works indicate that LLMs have modeled rich knowledge, albeit not effectively triggered or activated. Inspired by this, we propose a novel knowledge-augmented framework, Imagination-Augmented-Generation (IAG), which simulates the human capacity to compensate for knowledge deficits while answering questions solely through imagination, without relying on external resources. Guided by IAG, we propose an imagine richer context method for question answering (IMcQA), which obtains richer context through the following two modules: explicit imagination by generating a short dummy document with long context compress and implicit imagination with HyperNetwork for generating adapter weights. Experimental results on three datasets demonstrate that IMcQA exhibits significant advantages in both open-domain and closed-book settings, as well as in both in-distribution performance and out-of-distribution generalizations. Our code will be available at https://github.com/Xnhyacinth/IAG.