 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDATA: Decomposed Attention-based Task Adaptation for Rehearsal-Free Continual Learning
Paper and Code
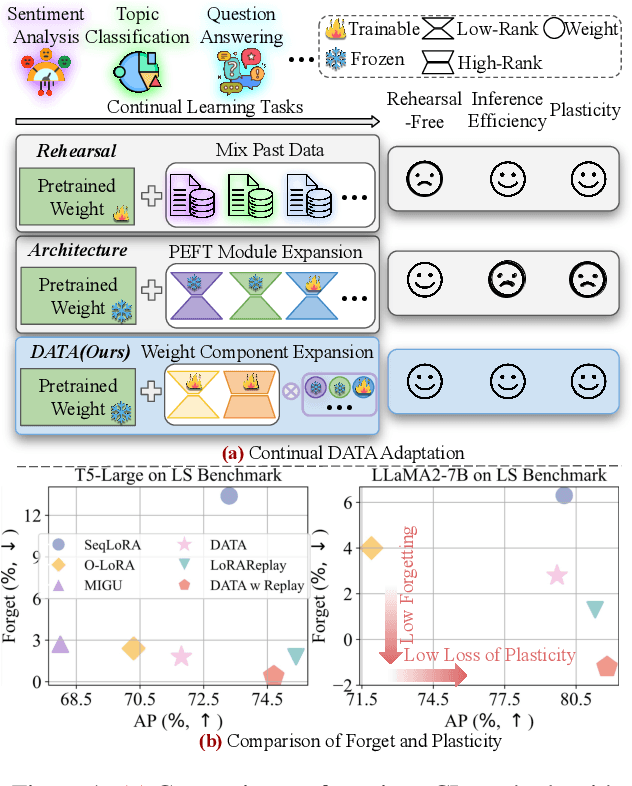
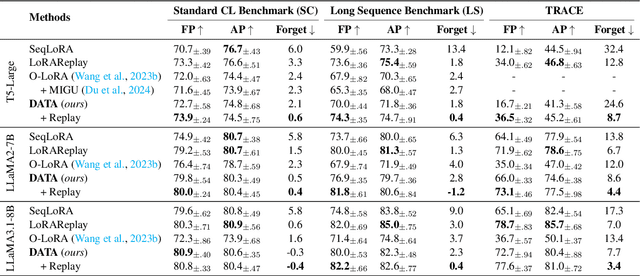
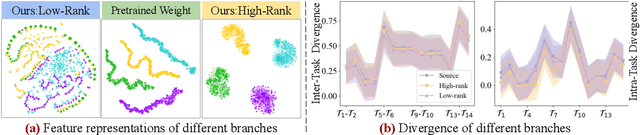
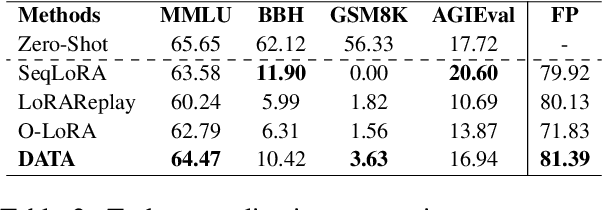
Continual learning (CL) is essential for Large Language Models (LLMs) to adapt to evolving real-world demands, yet they are susceptible to catastrophic forgetting (CF). While traditional CF solutions rely on expensive data rehearsal, recent rehearsal-free methods employ model-based and regularization-based strategies to address this issue. However, these approaches often neglect the model's plasticity, which is crucial to achieving optimal performance on newly learned tasks. Consequently, a key challenge in CL is striking a balance between preserving plasticity and mitigating CF. To tackle this challenge, we propose the $\textbf{D}$ecomposed $\textbf{A}$ttention-based $\textbf{T}$ask $\textbf{A}$daptation (DATA), which explicitly decouples and learns both task-specific and task-shared knowledge using high-rank and low-rank task adapters (e.g., LoRAs). For new tasks, DATA dynamically adjusts the weights of adapters of different ranks based on their relevance and distinction from previous tasks, allowing the model to acquire new task-specific skills while effectively retaining previously learned knowledge. Specifically, we implement a decomposed component weighting strategy comprising learnable components that collectively generate attention-based weights, allowing the model to integrate and utilize diverse knowledge from each DATA. Extensive experiments on three widely used benchmarks demonstrate that our proposed method achieves state-of-the-art performance. Notably, our approach significantly enhances model plasticity and mitigates CF by extending learnable components and employing stochastic restoration during training iterations.