 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaMETA: Towards Learning Disentangled Paralinguistic Speaking Styles Representations from Speech
Jan 18, 2026Learning representative embeddings for different types of speaking styles, such as emotion, age, and gender, is critical for both recognition tasks (e.g., cognitive computing and human-computer interaction) and generative tasks (e.g., style-controllable speech generation). In this work, we introduce ParaMETA, a unified and flexible framework for learning and controlling speaking styles directly from speech. Unlike existing methods that rely on single-task models or cross-modal alignment, ParaMETA learns disentangled, task-specific embeddings by projecting speech into dedicated subspaces for each type of style. This design reduces inter-task interference, mitigates negative transfer, and allows a single model to handle multiple paralinguistic tasks such as emotion, gender, age, and language classification. Beyond recognition, ParaMETA enables fine-grained style control in Text-To-Speech (TTS) generative models. It supports both speech- and text-based prompting and allows users to modify one speaking styles while preserving others. Extensive experiments demonstrate that ParaMETA outperforms strong baselines in classification accuracy and generates more natural and expressive speech, while maintaining a lightweight and efficient model suitable for real-world applications.
Beyond Hard and Soft: Hybrid Context Compression for Balancing Local and Global Information Retention
May 21, 2025Large Language Models (LLMs) encounter significant challenges in long-sequence inference due to computational inefficiency and redundant processing, driving interest in context compression techniques. Existing methods often rely on token importance to perform hard local compression or encode context into latent representations for soft global compression. However, the uneven distribution of textual content relevance and the diversity of demands for user instructions mean these approaches frequently lead to the loss of potentially valuable information. To address this, we propose $\textbf{Hy}$brid $\textbf{Co}$ntext $\textbf{Co}$mpression (HyCo$_2$) for LLMs, which integrates both global and local perspectives to guide context compression while retaining both the essential semantics and critical details for task completion. Specifically, we employ a hybrid adapter to refine global semantics with the global view, based on the observation that different adapters excel at different tasks. Then we incorporate a classification layer that assigns a retention probability to each context token based on the local view, determining whether it should be retained or discarded. To foster a balanced integration of global and local compression, we introduce auxiliary paraphrasing and completion pretraining before instruction tuning. This promotes a synergistic integration that emphasizes instruction-relevant information while preserving essential local details, ultimately balancing local and global information retention in context compression. Experiments show that our HyCo$_2$ method significantly enhances long-text reasoning while reducing token usage. It improves the performance of various LLM series by an average of 13.1\% across seven knowledge-intensive QA benchmarks. Moreover, HyCo$_2$ matches the performance of uncompressed methods while reducing token consumption by 88.8\%.
mmMirror: Device Free mmWave Indoor NLoS Localization Using Van-Atta-Array IRS
May 16, 2025Industry 4.0 is transforming manufacturing and logistics by integrating robots into shared human environments, such as factories, warehouses, and healthcare facilities. However, the risk of human-robot collisions, especially in Non-Line-of-Sight (NLoS) scenarios like around corners, remains a critical challenge. Existing solutions, such as vision-based and LiDAR systems, often fail under occlusion, lighting constraints, or privacy concerns, while RF-based systems are limited by range and accuracy. To address these limitations, we propose mmMirror, a novel system leveraging a Van Atta Array-based millimeter-wave (mmWave) reconfigurable intelligent reflecting surface (IRS) for precise, device-free NLoS localization. mmMirror integrates seamlessly with existing frequency-modulated continuous-wave (FMCW) radars and offers: (i) robust NLoS localization with centimeter-level accuracy at ranges up to 3 m, (ii) seamless uplink and downlink communication between radar and IRS, (iii) support for multi-radar and multi-target scenarios via dynamic beam steering, and (iv) reduced scanning latency through adaptive time slot allocation. Implemented using commodity 24 GHz radars and a PCB-based IRS prototype, mmMirror demonstrates its potential in enabling safe human-robot interactions in dynamic and complex environments.
N$^2$LoS: Single-Tag mmWave Backscatter for Robust Non-Line-of-Sight Localization
May 13, 2025The accuracy of traditional localization methods significantly degrades when the direct path between the wireless transmitter and the target is blocked or non-penetrable. This paper proposes N2LoS, a novel approach for precise non-line-of-sight (NLoS) localization using a single mmWave radar and a backscatter tag. N2LoS leverages multipath reflections from both the tag and surrounding reflectors to accurately estimate the targets position. N2LoS introduces several key innovations. First, we design HFD (Hybrid Frequency-Hopping and Direct Sequence Spread Spectrum) to detect and differentiate reflectors from the target. Second, we enhance signal-to-noise ratio (SNR) by exploiting the correlation properties of the designed signals, improving detection robustness in complex environments. Third, we propose FS-MUSIC (Frequency-Spatial Multiple Signal Classification), a super resolution algorithm that extends the traditional MUSIC method by constructing a higher-rank signal matrix, enabling the resolution of additional multipath components. We evaluate N2LoS using a 24 GHz mmWave radar with 250 MHz bandwidth in three diverse environments: a laboratory, an office, and an around-the-corner corridor. Experimental results demonstrate that N2LoS achieves median localization errors of 10.69 cm (X) and 11.98 cm (Y) at a 5 m range in the laboratory setting, showcasing its effectiveness for real-world NLoS localization.
Generalized Multilingual Text-to-Speech Generation with Language-Aware Style Adaptation
Apr 11, 2025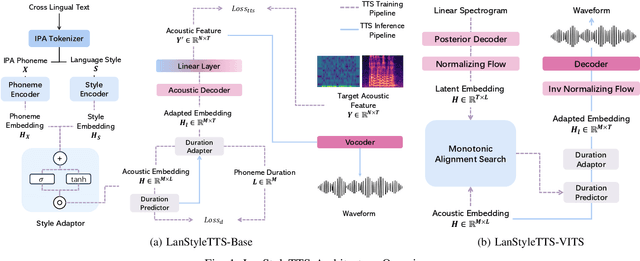



Text-to-Speech (TTS) models can generate natural, human-like speech across multiple languages by transforming phonemes into waveforms. However, multilingual TTS remains challenging due to discrepancies in phoneme vocabularies and variations in prosody and speaking style across languages. Existing approaches either train separate models for each language, which achieve high performance at the cost of increased computational resources, or use a unified model for multiple languages that struggles to capture fine-grained, language-specific style variations. In this work, we propose LanStyleTTS, a non-autoregressive, language-aware style adaptive TTS framework that standardizes phoneme representations and enables fine-grained, phoneme-level style control across languages. This design supports a unified multilingual TTS model capable of producing accurate and high-quality speech without the need to train language-specific models. We evaluate LanStyleTTS by integrating it with several state-of-the-art non-autoregressive TTS architectures. Results show consistent performance improvements across different model backbones. Furthermore, we investigate a range of acoustic feature representations, including mel-spectrograms and autoencoder-derived latent features. Our experiments demonstrate that latent encodings can significantly reduce model size and computational cost while preserving high-quality speech generation.
CAKE: Cascading and Adaptive KV Cache Eviction with Layer Preferences
Mar 16, 2025



Large language models (LLMs) excel at processing long sequences, boosting demand for key-value (KV) caching. While recent efforts to evict KV cache have alleviated the inference burden, they often fail to allocate resources rationally across layers with different attention patterns. In this paper, we introduce Cascading and Adaptive KV cache Eviction (CAKE), a novel approach that frames KV cache eviction as a "cake-slicing problem." CAKE assesses layer-specific preferences by considering attention dynamics in both spatial and temporal dimensions, allocates rational cache size for layers accordingly, and manages memory constraints in a cascading manner. This approach enables a global view of cache allocation, adaptively distributing resources across diverse attention mechanisms while maintaining memory budgets. CAKE also employs a new eviction indicator that considers the shifting importance of tokens over time, addressing limitations in existing methods that overlook temporal dynamics. Comprehensive experiments on LongBench and NeedleBench show that CAKE maintains model performance with only 3.2% of the KV cache and consistently outperforms current baselines across various models and memory constraints, particularly in low-memory settings. Additionally, CAKE achieves over 10x speedup in decoding latency compared to full cache when processing contexts of 128K tokens with FlashAttention-2. Our code is available at https://github.com/antgroup/cakekv.
Deep Learning-Based Direct Leaf Area Estimation using Two RGBD Datasets for Model Development
Mar 13, 2025


Estimation of a single leaf area can be a measure of crop growth and a phenotypic trait to breed new varieties. It has also been used to measure leaf area index and total leaf area. Some studies have used hand-held cameras, image processing 3D reconstruction and unsupervised learning-based methods to estimate the leaf area in plant images. Deep learning works well for object detection and segmentation tasks; however, direct area estimation of objects has not been explored. This work investigates deep learning-based leaf area estimation, for RGBD images taken using a mobile camera setup in real-world scenarios. A dataset for attached leaves captured with a top angle view and a dataset for detached single leaves were collected for model development and testing. First, image processing-based area estimation was tested on manually segmented leaves. Then a Mask R-CNN-based model was investigated, and modified to accept RGBD images and to estimate the leaf area. The detached-leaf data set was then mixed with the attached-leaf plant data set to estimate the single leaf area for plant images, and another network design with two backbones was proposed: one for segmentation and the other for area estimation. Instead of trying all possibilities or random values, an agile approach was used in hyperparameter tuning. The final model was cross-validated with 5-folds and tested with two unseen datasets: detached and attached leaves. The F1 score with 90% IoA for segmentation result on unseen detached-leaf data was 1.0, while R-squared of area estimation was 0.81. For unseen plant data segmentation, the F1 score with 90% IoA was 0.59, while the R-squared score was 0.57. The research suggests using attached leaves with ground truth area to improve the results.
LatentSpeech: Latent Diffusion for Text-To-Speech Generation
Dec 11, 2024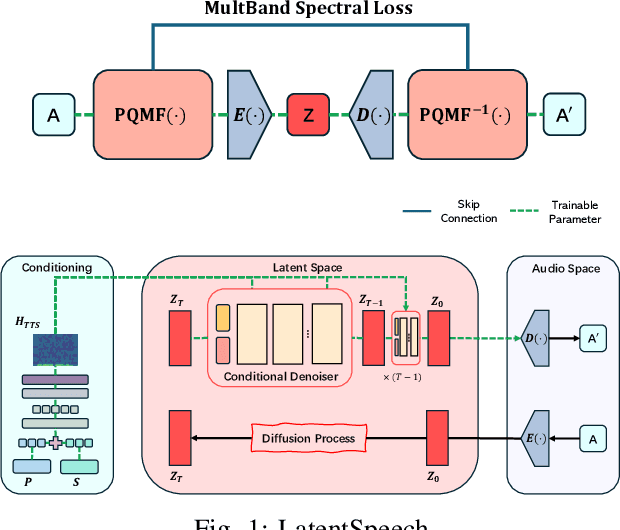
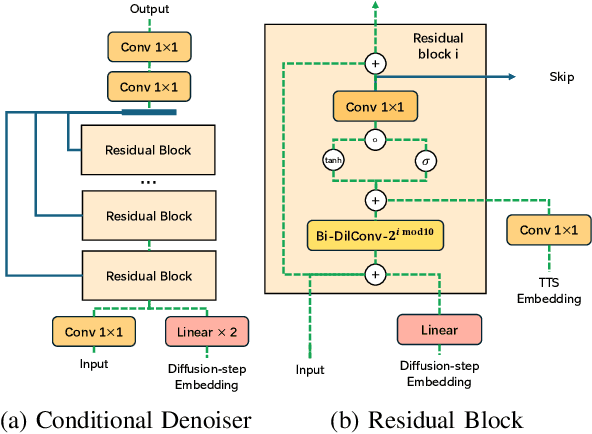
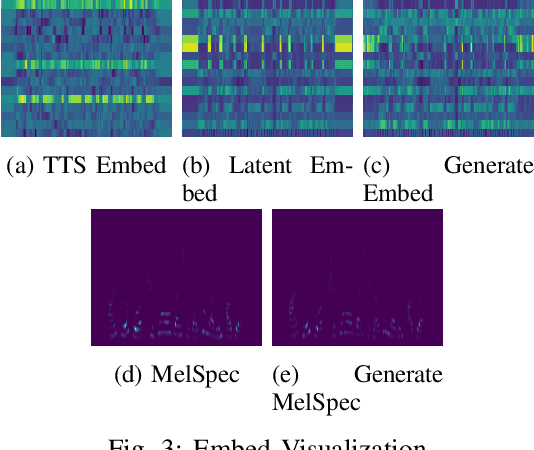
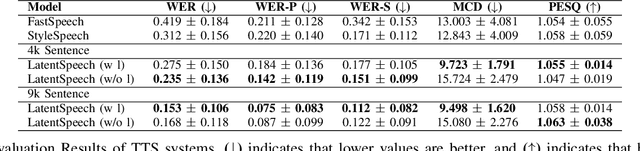
Diffusion-based Generative AI gains significant attention for its superior performance over other generative techniques like Generative Adversarial Networks and Variational Autoencoders. While it has achieved notable advancements in fields such as computer vision and natural language processing, their application in speech generation remains under-explored. Mainstream Text-to-Speech systems primarily map outputs to Mel-Spectrograms in the spectral space, leading to high computational loads due to the sparsity of MelSpecs. To address these limitations, we propose LatentSpeech, a novel TTS generation approach utilizing latent diffusion models. By using latent embeddings as the intermediate representation, LatentSpeech reduces the target dimension to 5% of what is required for MelSpecs, simplifying the processing for the TTS encoder and vocoder and enabling efficient high-quality speech generation. This study marks the first integration of latent diffusion models in TTS, enhancing the accuracy and naturalness of generated speech. Experimental results on benchmark datasets demonstrate that LatentSpeech achieves a 25% improvement in Word Error Rate and a 24% improvement in Mel Cepstral Distortion compared to existing models, with further improvements rising to 49.5% and 26%, respectively, with additional training data. These findings highlight the potential of LatentSpeech to advance the state-of-the-art in TTS technology
Aligner-Guided Training Paradigm: Advancing Text-to-Speech Models with Aligner Guided Duration
Dec 11, 2024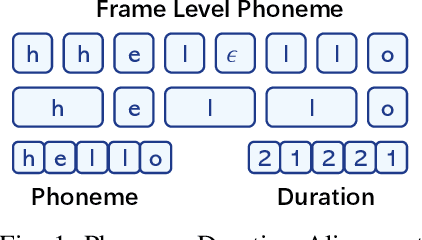
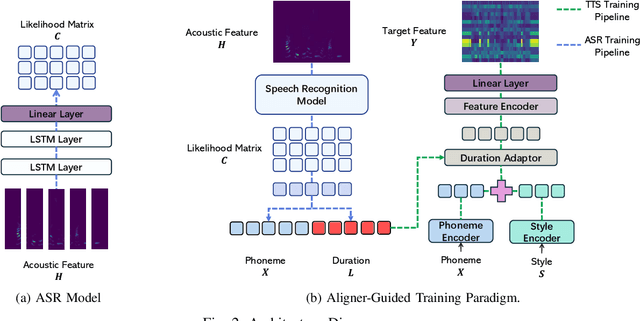
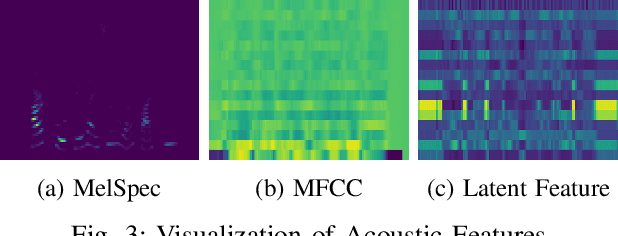

Recent advancements in text-to-speech (TTS) systems, such as FastSpeech and StyleSpeech, have significantly improved speech generation quality. However, these models often rely on duration generated by external tools like the Montreal Forced Aligner, which can be time-consuming and lack flexibility. The importance of accurate duration is often underestimated, despite their crucial role in achieving natural prosody and intelligibility. To address these limitations, we propose a novel Aligner-Guided Training Paradigm that prioritizes accurate duration labelling by training an aligner before the TTS model. This approach reduces dependence on external tools and enhances alignment accuracy. We further explore the impact of different acoustic features, including Mel-Spectrograms, MFCCs, and latent features, on TTS model performance. Our experimental results show that aligner-guided duration labelling can achieve up to a 16\% improvement in word error rate and significantly enhance phoneme and tone alignment. These findings highlight the effectiveness of our approach in optimizing TTS systems for more natural and intelligible speech generation.
LightLLM: A Versatile Large Language Model for Predictive Light Sensing
Nov 20, 2024



We propose LightLLM, a model that fine tunes pre-trained large language models (LLMs) for light-based sensing tasks. It integrates a sensor data encoder to extract key features, a contextual prompt to provide environmental information, and a fusion layer to combine these inputs into a unified representation. This combined input is then processed by the pre-trained LLM, which remains frozen while being fine-tuned through the addition of lightweight, trainable components, allowing the model to adapt to new tasks without altering its original parameters. This approach enables flexible adaptation of LLM to specialized light sensing tasks with minimal computational overhead and retraining effort. We have implemented LightLLM for three light sensing tasks: light-based localization, outdoor solar forecasting, and indoor solar estimation. Using real-world experimental datasets, we demonstrate that LightLLM significantly outperforms state-of-the-art methods, achieving 4.4x improvement in localization accuracy and 3.4x improvement in indoor solar estimation when tested in previously unseen environments. We further demonstrate that LightLLM outperforms ChatGPT-4 with direct prompting, highlighting the advantages of LightLLM's specialized architecture for sensor data fusion with textual prompts.