 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentSpeech: Latent Diffusion for Text-To-Speech Generation
Paper and Code
Dec 11, 2024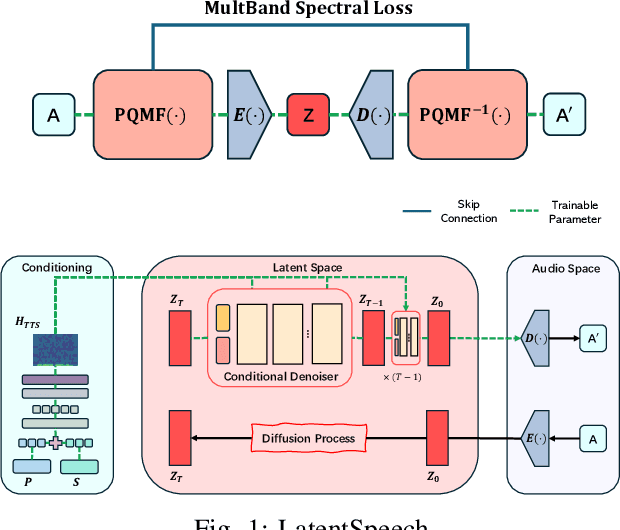
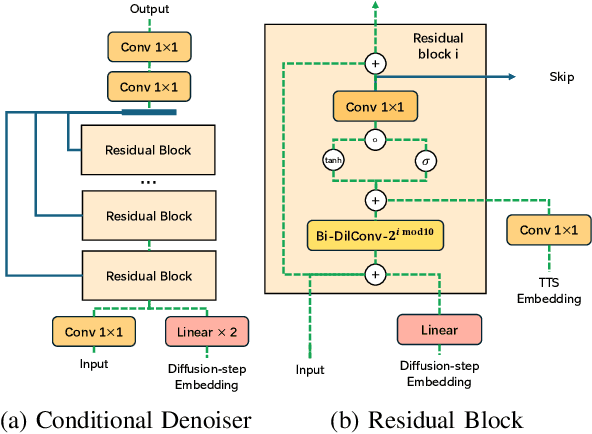
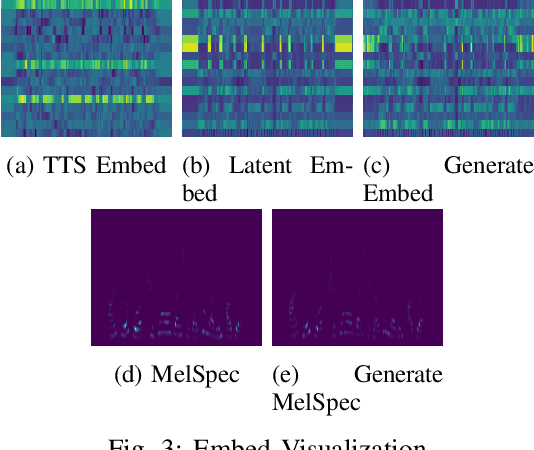
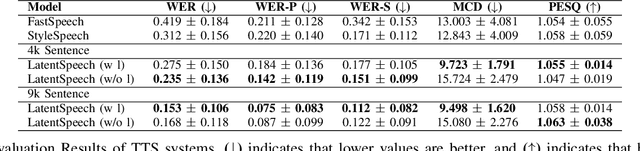
Diffusion-based Generative AI gains significant attention for its superior performance over other generative techniques like Generative Adversarial Networks and Variational Autoencoders. While it has achieved notable advancements in fields such as computer vision and natural language processing, their application in speech generation remains under-explored. Mainstream Text-to-Speech systems primarily map outputs to Mel-Spectrograms in the spectral space, leading to high computational loads due to the sparsity of MelSpecs. To address these limitations, we propose LatentSpeech, a novel TTS generation approach utilizing latent diffusion models. By using latent embeddings as the intermediate representation, LatentSpeech reduces the target dimension to 5% of what is required for MelSpecs, simplifying the processing for the TTS encoder and vocoder and enabling efficient high-quality speech generation. This study marks the first integration of latent diffusion models in TTS, enhancing the accuracy and naturalness of generated speech. Experimental results on benchmark datasets demonstrate that LatentSpeech achieves a 25% improvement in Word Error Rate and a 24% improvement in Mel Cepstral Distortion compared to existing models, with further improvements rising to 49.5% and 26%, respectively, with additional training data. These findings highlight the potential of LatentSpeech to advance the state-of-the-art in TTS technology