 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentSpeech: Latent Diffusion for Text-To-Speech Generation
Dec 11, 2024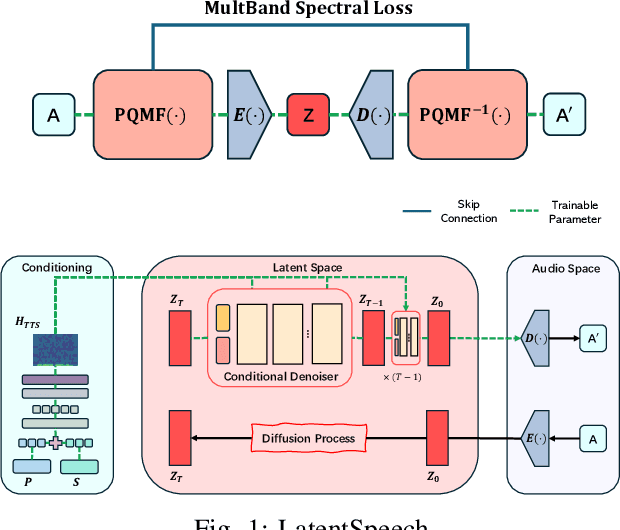
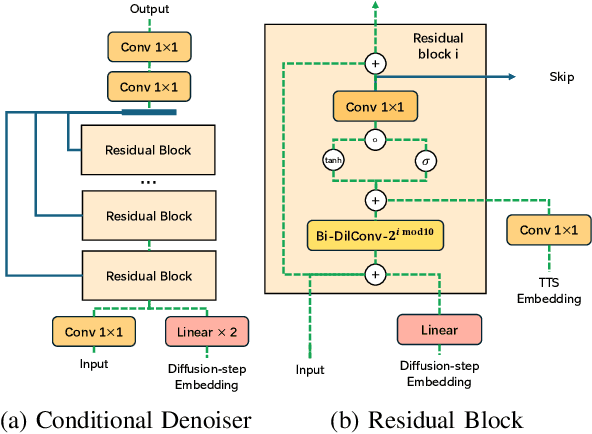
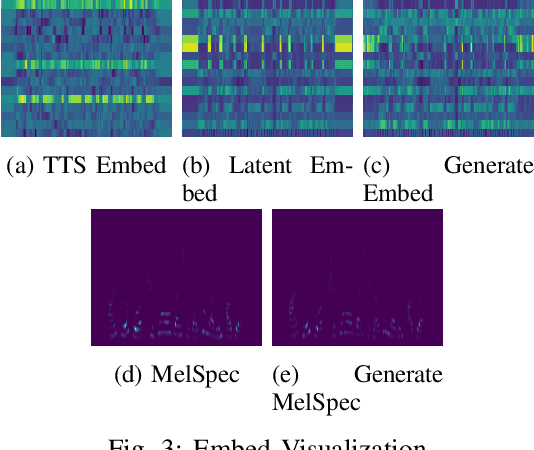
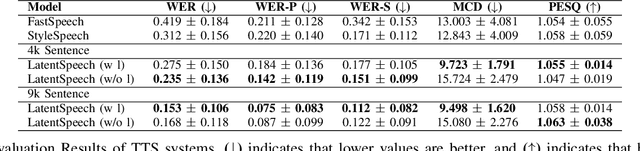
Diffusion-based Generative AI gains significant attention for its superior performance over other generative techniques like Generative Adversarial Networks and Variational Autoencoders. While it has achieved notable advancements in fields such as computer vision and natural language processing, their application in speech generation remains under-explored. Mainstream Text-to-Speech systems primarily map outputs to Mel-Spectrograms in the spectral space, leading to high computational loads due to the sparsity of MelSpecs. To address these limitations, we propose LatentSpeech, a novel TTS generation approach utilizing latent diffusion models. By using latent embeddings as the intermediate representation, LatentSpeech reduces the target dimension to 5% of what is required for MelSpecs, simplifying the processing for the TTS encoder and vocoder and enabling efficient high-quality speech generation. This study marks the first integration of latent diffusion models in TTS, enhancing the accuracy and naturalness of generated speech. Experimental results on benchmark datasets demonstrate that LatentSpeech achieves a 25% improvement in Word Error Rate and a 24% improvement in Mel Cepstral Distortion compared to existing models, with further improvements rising to 49.5% and 26%, respectively, with additional training data. These findings highlight the potential of LatentSpeech to advance the state-of-the-art in TTS technology
Aligner-Guided Training Paradigm: Advancing Text-to-Speech Models with Aligner Guided Duration
Dec 11, 2024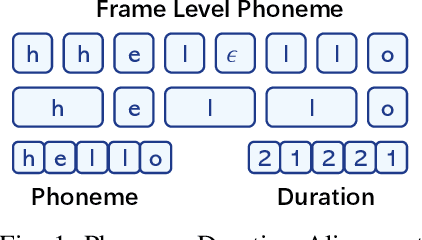
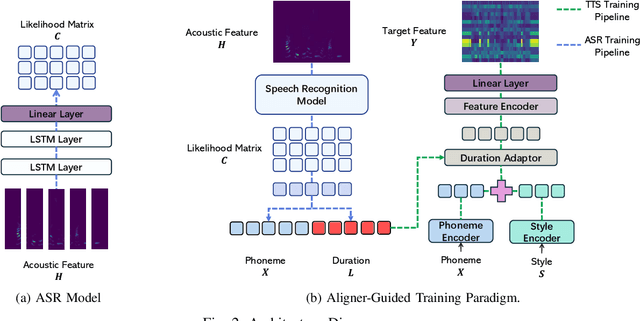
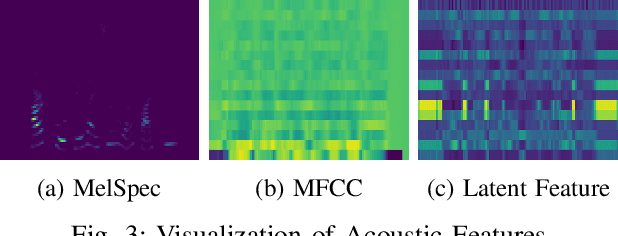

Recent advancements in text-to-speech (TTS) systems, such as FastSpeech and StyleSpeech, have significantly improved speech generation quality. However, these models often rely on duration generated by external tools like the Montreal Forced Aligner, which can be time-consuming and lack flexibility. The importance of accurate duration is often underestimated, despite their crucial role in achieving natural prosody and intelligibility. To address these limitations, we propose a novel Aligner-Guided Training Paradigm that prioritizes accurate duration labelling by training an aligner before the TTS model. This approach reduces dependence on external tools and enhances alignment accuracy. We further explore the impact of different acoustic features, including Mel-Spectrograms, MFCCs, and latent features, on TTS model performance. Our experimental results show that aligner-guided duration labelling can achieve up to a 16\% improvement in word error rate and significantly enhance phoneme and tone alignment. These findings highlight the effectiveness of our approach in optimizing TTS systems for more natural and intelligible speech generation.
StyleSpeech: Parameter-efficient Fine Tuning for Pre-trained Controllable Text-to-Speech
Aug 27, 2024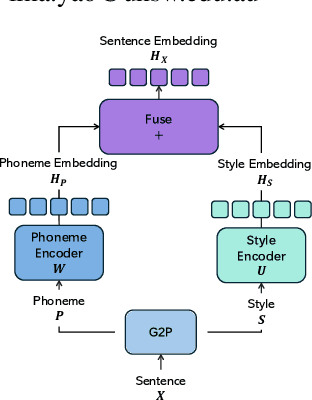
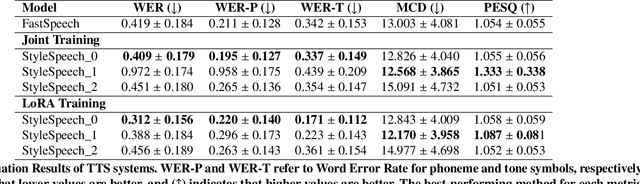
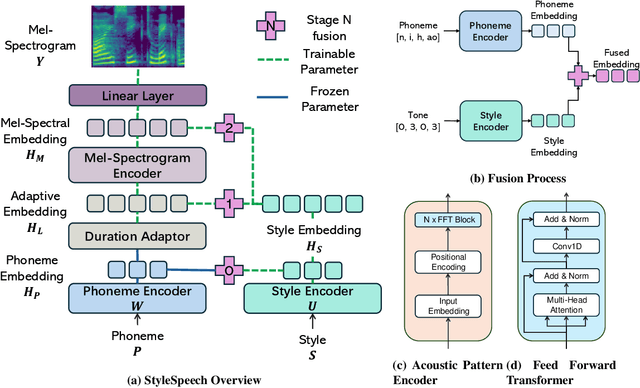
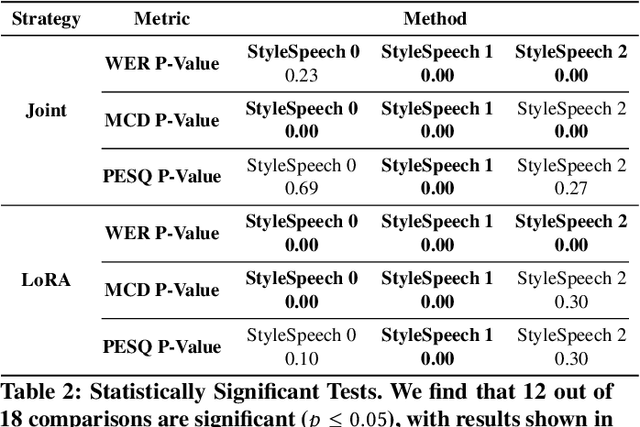
This paper introduces StyleSpeech, a novel Text-to-Speech~(TTS) system that enhances the naturalness and accuracy of synthesized speech. Building upon existing TTS technologies, StyleSpeech incorporates a unique Style Decorator structure that enables deep learning models to simultaneously learn style and phoneme features, improving adaptability and efficiency through the principles of Lower Rank Adaptation~(LoRA). LoRA allows efficient adaptation of style features in pre-trained models. Additionally, we introduce a novel automatic evaluation metric, the LLM-Guided Mean Opinion Score (LLM-MOS), which employs large language models to offer an objective and robust protocol for automatically assessing TTS system performance. Extensive testing on benchmark datasets shows that our approach markedly outperforms existing state-of-the-art baseline methods in producing natural, accurate, and high-quality speech. These advancements not only pushes the boundaries of current TTS system capabilities, but also facilitate the application of TTS system in more dynamic and specialized, such as interactive virtual assistants, adaptive audiobooks, and customized voice for gaming. Speech samples can be found in https://style-speech.vercel.app