 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligner-Guided Training Paradigm: Advancing Text-to-Speech Models with Aligner Guided Duration
Paper and Code
Dec 11, 2024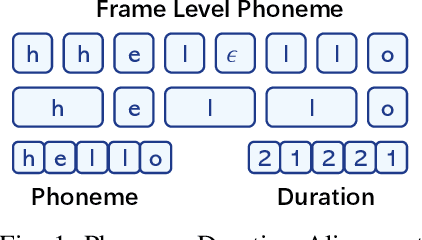
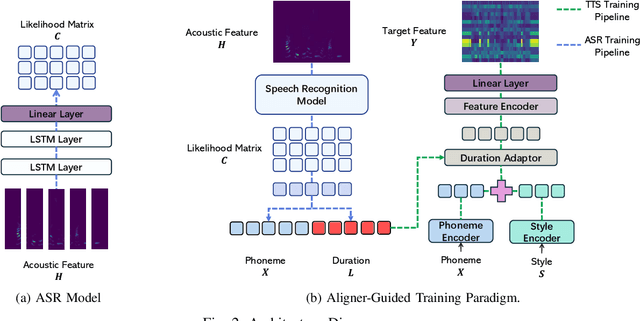
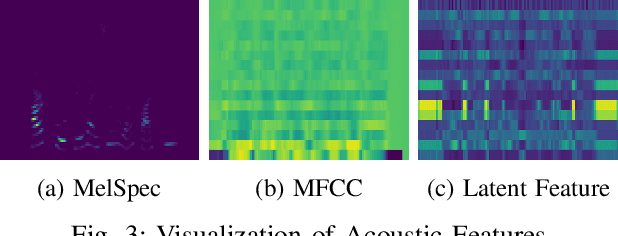

Recent advancements in text-to-speech (TTS) systems, such as FastSpeech and StyleSpeech, have significantly improved speech generation quality. However, these models often rely on duration generated by external tools like the Montreal Forced Aligner, which can be time-consuming and lack flexibility. The importance of accurate duration is often underestimated, despite their crucial role in achieving natural prosody and intelligibility. To address these limitations, we propose a novel Aligner-Guided Training Paradigm that prioritizes accurate duration labelling by training an aligner before the TTS model. This approach reduces dependence on external tools and enhances alignment accuracy. We further explore the impact of different acoustic features, including Mel-Spectrograms, MFCCs, and latent features, on TTS model performance. Our experimental results show that aligner-guided duration labelling can achieve up to a 16\% improvement in word error rate and significantly enhance phoneme and tone alignment. These findings highlight the effectiveness of our approach in optimizing TTS systems for more natural and intelligible speech generation.