 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleSpeech: Parameter-efficient Fine Tuning for Pre-trained Controllable Text-to-Speech
Paper and Code
Aug 27, 2024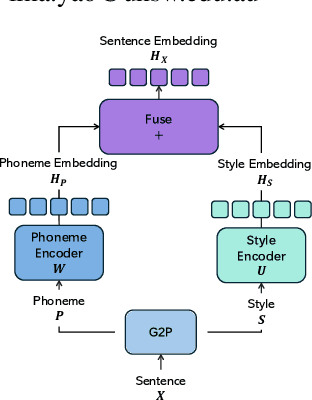
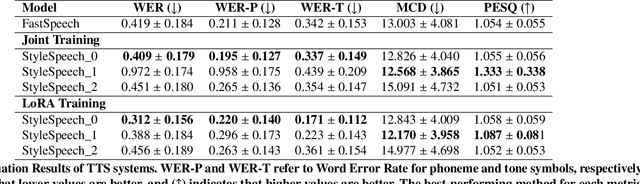
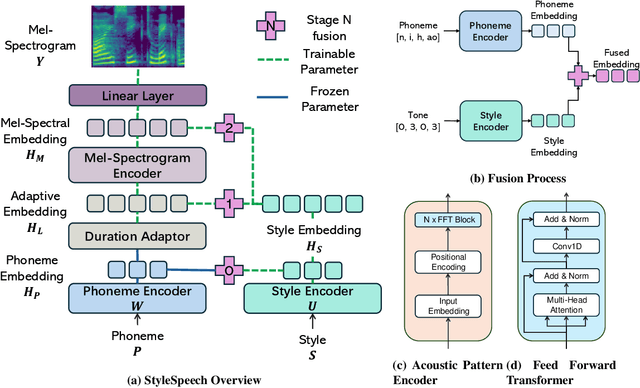
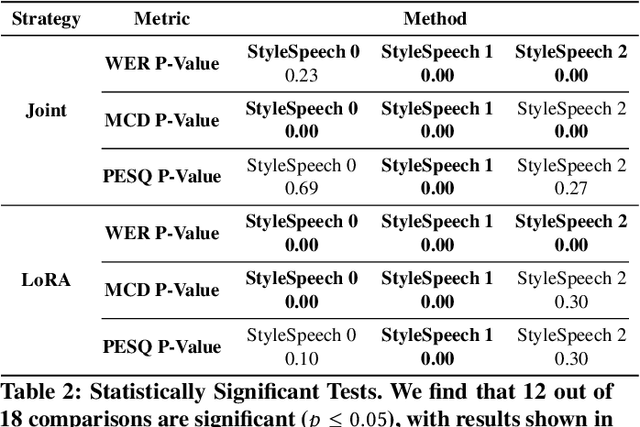
This paper introduces StyleSpeech, a novel Text-to-Speech~(TTS) system that enhances the naturalness and accuracy of synthesized speech. Building upon existing TTS technologies, StyleSpeech incorporates a unique Style Decorator structure that enables deep learning models to simultaneously learn style and phoneme features, improving adaptability and efficiency through the principles of Lower Rank Adaptation~(LoRA). LoRA allows efficient adaptation of style features in pre-trained models. Additionally, we introduce a novel automatic evaluation metric, the LLM-Guided Mean Opinion Score (LLM-MOS), which employs large language models to offer an objective and robust protocol for automatically assessing TTS system performance. Extensive testing on benchmark datasets shows that our approach markedly outperforms existing state-of-the-art baseline methods in producing natural, accurate, and high-quality speech. These advancements not only pushes the boundaries of current TTS system capabilities, but also facilitate the application of TTS system in more dynamic and specialized, such as interactive virtual assistants, adaptive audiobooks, and customized voice for gaming. Speech samples can be found in https://style-speech.vercel.app