 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Multilingual Text-to-Speech Generation with Language-Aware Style Adaptation
Paper and Code
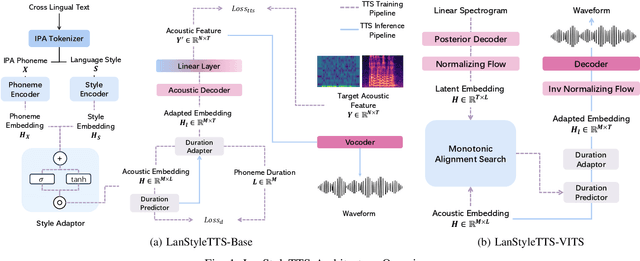



Text-to-Speech (TTS) models can generate natural, human-like speech across multiple languages by transforming phonemes into waveforms. However, multilingual TTS remains challenging due to discrepancies in phoneme vocabularies and variations in prosody and speaking style across languages. Existing approaches either train separate models for each language, which achieve high performance at the cost of increased computational resources, or use a unified model for multiple languages that struggles to capture fine-grained, language-specific style variations. In this work, we propose LanStyleTTS, a non-autoregressive, language-aware style adaptive TTS framework that standardizes phoneme representations and enables fine-grained, phoneme-level style control across languages. This design supports a unified multilingual TTS model capable of producing accurate and high-quality speech without the need to train language-specific models. We evaluate LanStyleTTS by integrating it with several state-of-the-art non-autoregressive TTS architectures. Results show consistent performance improvements across different model backbones. Furthermore, we investigate a range of acoustic feature representations, including mel-spectrograms and autoencoder-derived latent features. Our experiments demonstrate that latent encodings can significantly reduce model size and computational cost while preserving high-quality speech generation.